
Задача на первый взгляд может показаться тривиальной: извлечь полезный текст из HTML страниц с различных сайтов, например новости с новостных лент. На практике, однако, реализация подобной функциональности, как правило, оканчивается написанием кучи парсеров заточенных под конкретные сайты. Поддерживать такие парсеры - сущий кошмар, особенно если система должна работать в автономном режиме долгое время. Хотелось бы иметь универсальное решение. Сегодня я опишу один из возможных вариантов решения этой проблемы.
Веб страница состоит из многих частей: полезный текст, некоторым образом размеченный, меню, заголовки, метатекст, скрипты итп. Можно было бы просто убрать всю HTML-разметку, но, к сожалению, это не работает, т.к. остается слишком много мусора. Кроме того, иногда мы хотим сохранить некоторые элементы разметки, например ссылки или изображения относящиеся к тексту, слова и предложения выделенные другим шрифтом итп.
Суть предлагаемого подхода состоит в том, чтобы разбить документ на большое количество частей (это могут быть строки либо параграфы) и для каждой части посчитать количество HTML разметки. Оказывается, что количество HTML разметки в участках с осмысленным текстом существенно меньше чем в других участках документа.
Для нашего примера я взял статью с rbcdaily. Можно было бы использовать версию для печати, но в целях чистоты эксперимента, остановимся на стандартной версии. Текст был разбит на строки и для каждой строки посчитано количество HTML-тегов разметки и количество прочего текста.
boolean isMarkup = false;
int markupCnt = 0;
for (int i = 0; i < sline.length(); i++) {
char ch = sline.charAt(i);
if (ch == '<') {
isMarkup = true;
}
if (isMarkup) {
markupCnt++;
}
if (ch == '>') {
isMarkup = false;
}
}
Красной линией на графике обозначается длина строки, синей линией количество не-HTML текста. В целях улучшения визуализации, показаны данные усредненные по 5 строк.
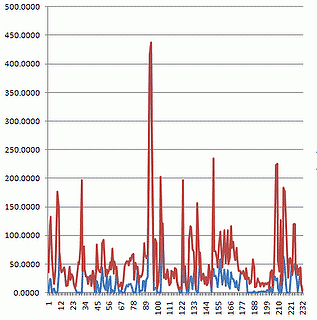
Не слишком понятная картина, правда? Некий пик между 89 и 100, а в остальном, много пиков и провалов. Беглый взгляд в HTML и становится понятно, что в нашем случае он очень сильно засорен JavaScipt-ом и HTML-комментариями. Для улучшения результатов, стоит их удалить. Это сделать достаточно просто, предварительно обработав HTML. После этого, результаты становятся более очевидными:
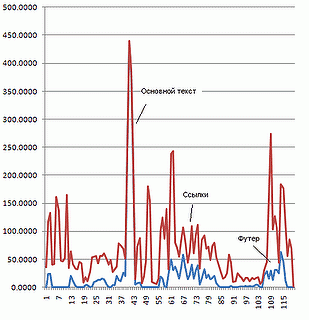
У нас четко нарисовался пик с основным текстом и куча мусора, который можно смело выбрасывать в корзину. Простейшим способам выбрать где здесь текст, а где мусор, это отобрать строки в которых величина отношения длины HTML разметки к длине строки меньше определенного порогового значения. В нашем случае я взял 0.3 и получил на удивление хорошие результаты

У такого подхода, однако, есть недостаток: несмотря на то, что все заголовки убраны, в тексте все еще сохраняется подпись. Кроме того, могут быть пропущены часть строк реального текста если, по некоторому стечению обстоятельств, там оказалось много разметки или сама строчка была слишком короткой. Для того чтобы улучшить фильтрацию следует рассматривать не только текущую строку но и соседние с ней. Как это сделать, я расскажу в следующий раз.
Протестировать результаты такого фильтра можно тут, введите адрес страницы которую бы вы хотели отфильтровать и нажмите старт.
Решение основывалось на том, что в тех участках HTML-страниц где содержится полезный текст, как правило, очень мало разметки. То есть, величина отношения количества текста к количеству разметки больше некоторого порогового значения. Для своего тестирования я использовал новостные ленты rbc.ru, rbcdaily.ru и свой блог algorithmist.ru.
Этот подход дал неплохие результаты, но к сожалению он дает очень большое количество ложных срабатываний, около 2% на указанных выше сайтах. Улучшить ситуацию нам помогут методы машинного обучения, а именно нейронные сети. Идея заключается в том, чтобы в момент проверки является ли та или иная строчка полезным текстом обратиться к предварительно натренированной нейронной сети и спросить у нее.
В качестве параметров для нейронной сети я выбрал следующие атрибуты:
- плотность HTML разметки в данной строке
- длина строки
- плотность HTML разметки в предыдущей строке
- длина предыдущей строки
- плотность HTML разметки в следующей строке
- длина следующей строки
- номер строки в документе
Все длины строк предварительно нормированы относительно максимальной длины строки в документе. Номер строки в документе так же нормирован относительно общего количества строк. Таким образом все 7 параметров принимают значения от 0 до 1 включительно.
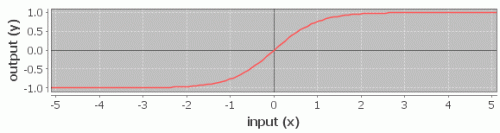
Для создания нейронной сети я воспользовался библиотечкой Encog. За основу была взята простейшая feed forward нейронная сеть и активирующая функция гиперболический тангенс:
Чтобы не гадать какая же конфигурация нейронной сети будет оптимальной, я воспользовался алгоритмом под названием pruning. Идея заключается в том, чтобы последовательно упрощать либо усложнять нейронную сеть, в поисках варианта с наименьшей ошибкой. Наилучших результатов удалось добиться с нейронной сетью из трех невидимых уровней, в первых двух из которых 7 нейронов, а в третьем 3. Тут главное знать меру, можно задать и большее количество невидимых уровней, но тогда возникает риск перетренировать нейронную сеть, слишком точно настроив на конкретные данные и тем самым ухудшить результаты на новых данных.
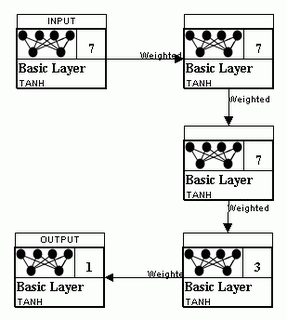
Для тренировки нейронной сети было создано два набора данных. Один тренировочный, другой проверочный. Конечно, мне было слишком лениво создавать большое количество данных вручную, поэтому каждый набор состоял всего из 10 статей с разных сайтов.
В результате, получилась нейронная сеть с характеристиками: количество ложных срабатываний 0.4%, количество пропусков события 0%. Конечно, эти результаты сильно зависят от того, какие именно сайты скармливать нейронной сети. Она не 100% универсальная. Но на большинстве новостных лент и блогов ведет себя неплохо выдавая внятное содержимое практически для любой страницы.
Думаю, что если требуется получить максимально точный результат, то лучше тренировать отдельные нейронные сети на каждый веб сайт. На практике это гораздо проще чем писать специальный HTML парсер и поддерживать его при малейших изменениях сайта.