
Описание: При использовании IBM Rational Functional Tester с приложениями, основанными на Eclipse, информация о сбоях, представляемая в виде Problems, довольно ограниченна и недостаточна для эффективного определения проблем и анализа ошибок. В этой статье объясняется, как можно собрать подробную информацию в виде Problems и в журнале ошибок, отфильтровать эту информацию и эффективно воспользоваться ею, чтобы улучшить определение проблем и идентификацию ошибок.
Различные инструменты автоматизации позволяют тестировщикам записывать и воспроизводить сценарии тестирования, а затем повторно использовать эти же сценарии в следующий раз. Один из основных критериев оценки качества автоматизации - наличие в сценарии набора точек верификации для обнаружения как прогнозируемых, так и непредвиденных ошибок. IBM® Rational® Functional Tester поддерживает несколько типов точек верификации (например, точки верификации Data, Properties и Image), которые вставляются в сценарии автоматического тестирования, чтобы предусмотреть типичные проблемы, возникающие в приложениях. Однако в некоторых случаях точки верификации не используются или собранные данные бесполезны при определении проблем. В таких случаях вместо добавления точек верификации в сценарий тестирования тестировщикам необходимо кодировать механизм проверки. В этой статье показано, как это сделать.
Eclipse - это интегрированная среда разработки (Integrated Development Environment - IDE), которая используется в основном для целей разработки. IBM Rational Functional Tester встроен в Eclipse. В данной статье предполагается, что читатели хорошо знакомы со средой Eclipse, настройкой Rational Functional Tester для тестируемых приложений, с записью/воспроизведением сценариев тестирования и содержимым сценариев тестирования, а потому эти области не описываются детально. Мы использовали IBM Rational Application Developer (Eclipse-приложение) в качестве тестируемого приложения.
Наиболее распространенным вариантом использования IBM Rational Application Developer является создание нового проекта при помощи мастера. В результате работы мастера создается проект, который похож на проект Rational Functional Tester и, в зависимости от своего типа, содержит Java-файлы, XML-файлы и несколько файлов свойств. Большинство других случаев, связанных с использованием проекта, - это операции в графическом интерфейсе, такие как перетаскивание текстового блока в .jsp-файл, приводящее к изменениям в новом проекте.
IBM Rational Application Developer отображает в виде Problems любые обнаруженные при компиляции ошибки или предупреждения. Любые исключительные ситуации, отмеченные во время исполнения, накапливаются в виде Error Log (файл журнала рабочей области). Тестировщики записывают сценарий тестирования и вставляют точки верификации в соответствии с назначением теста, а затем проверяют в этих двух видах наличие каких-либо ошибок, зафиксированных во время выполнения варианта тестирования.
Поскольку в виде Problems фиксируются ошибки времени компиляции, использование точек верификации является простым способом обнаружить эти ошибки. Rational Functional Tester помечает вариант тестирования как неудавшийся и предоставляет в виде Problems снимок зафиксированной ошибки.
Однако не всегда целесообразно использовать точки верификации, чтобы собрать детальную информацию, связанную с тестируемым приложением. Причина в том, что во время выполнения задачи случаются исключительные ситуации, отображаемые в виде Error. Таким образом, операции в тестируемом приложении могут быть успешными, но неправильными по причине наличия в файле журнала исключительных ситуаций и предупреждений.
В виде Problems возникает ограничение, если ошибок так много, что появляется полоса прокрутки. Из-за прокрутки вы не можете видеть все ошибки в снимке сбоев, предоставляемом Rational Functional Tester.
В виде Error ограничение связано с тем, что посредством снимка невозможно представить детальную трассировку стека для исключительной ситуации.
Для лучшего определения проблем и минимизации риска пропустить ошибку необходима трассировка обоих этих видов.
В данной статье объясняется, как собрать информацию в видах Problems и Error Log тестируемого приложения, отфильтровать ее и модифицировать для определения проблем и выявления ошибок. Ссылки на файлы журнала рабочей области, приведенные в данной статье, можно применить к любой тестируемой системе, которая создает файлы журнала.
Подготовка Rational Functional Tester к тестированию приложений, основанных на Eclipse
Чтобы использовать IBM Rational Functional Tester для основанных на Eclipse приложений, необходимо настроить приложение и запустить среду тестирования. Чтобы настроить приложение:
- Откройте Rational Functional Tester.
- В меню Main выберите Configure > Configure Application for testing. Откроется окно Application Configuration Tool (см. рисунок 1).
- Добавьте информацию о тестируемом приложении.
- Нажмите кнопку Finish, чтобы сохранить изменения.
Рисунок 1. Диалог настройки приложения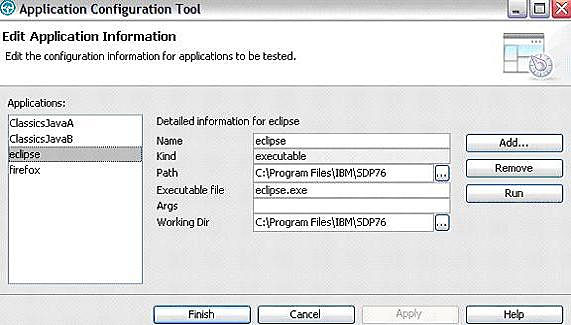
Чтобы запустить среду Eclipse для тестирования:
- Выберите Configure > Enable environment for testing. Откроется окно Enable Environments (см. рисунок 2).
- Выберите Eclipse и нажмите кнопку Enable. Если среды Eclipse нет в списке, нажмите кнопку Search.
- Нажмите кнопку Finish, чтобы сохранить изменения.
Рисунок 2. Диалог Enable Environments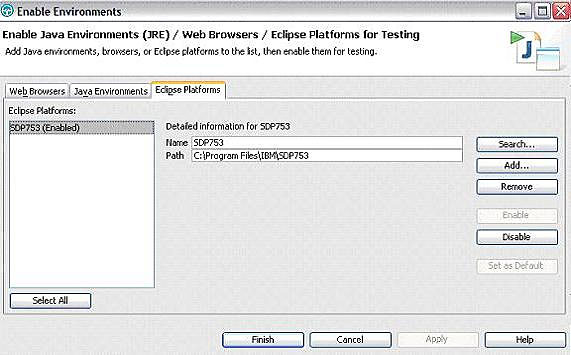
Запись и воспроизведение сценариев тестирования
В зависимости от мастерства тестировщика и сложности тестируемого приложения существует много способов кодирования сценариев тестирования. Как и другие автоматизированные средства тестирования, Rational Functional Tester позволяет тестировщику легко записывать операции в графическом интерфейсе и воспроизводить их в тестируемом приложении. Тестировщик может также кодировать вариант тестирования вручную, без использования возможностей записи, предоставляемых инструментарием, и захватывать объекты тестирования позднее, идентифицируя их при помощи инструментария.
Создание и фильтрация дополнительных журналов
Получение информации дополнительного журнала - это двухступенчатый процесс: во-первых, необходимо создать дополнительные информативные журналы, во-вторых, отфильтровать из них существенную информацию для быстрого анализа после выполнения.
Приведенные ниже методы создания журналов следует применять строго после окончания сценария в варианте тестирования и до начала планируемого восстановления или очистки тестовой среды для выполнения следующего варианта тестирования.
Создание дополнительных журналов
Обычно несколько вариантов тестирования объединяют в набор тестов и затем выполняют весь набор тестов целиком. После каждого варианта тестирования тестируемое приложение восстанавливается в исходное состояние, что включает в себя очистку тестовых данных, созданных во время выполнения варианта тестирования.
Ошибки, фиксируемые в виде Problems, являются специфическими для проекта ошибками, возникающими во время компиляции. Поэтому после завершения выполнения проект удаляется, а информация теряется.
Напротив, информация в файле журнала сохраняется, поскольку действия тестировщика продолжаются. Ограничение файла журнала состоит в том, что после выполнения набора тестов вы не в состоянии определить, какие исключительные ситуации к какому варианту тестирования относятся.
Поэтому, прежде чем запустить вариант тестирования, необходимо очистить или удалить файл журнала, чтобы гарантировать, что записи в нем будут принадлежать только последнему варианту тестирования.
После очистки или удаления файла журнала закодируйте методы обработки файла для получения нужной информации из данного файла журнала и поместите эти методы в сценарий тестирования после методов или кода выполнения теста. Для достижения наилучших результатов записывайте и поддерживайте сценарии тестирования в атомарной форме - один вариант использования на один сценарий тестирования.
Сбор информации в виде Problems
Как уже упоминалось ранее в этой статье, предоставляемые Rational Functional Tester точки верификации могут сообщать о наличии ошибок компиляции и предоставлять снимки вида Problems. Но для лучшего анализа и определения проблем необходим полный список ошибок, который может не отображаться на снимке. Следующий метод объясняет, как извлечь этот список.
Присвойте аргументу, передаваемому в метод, имя сценария, для которого будут собираться данные в файле журнала. Это привязывает данные в файле ErrorDetails к сценарию, потому что перед каждой записью в файле журнала указывается имя сценария.
Пример кода для сбора данных в виде Problems
В приведенном ниже примере кода сначала открывается вид Problems, а затем этот вид проверяется на наличие в нем записи. Если запись найдена, код проверяет, является ли она записью об ошибке (кроме списка ошибок вид также предоставляет список предупреждений). Если это запись об ошибке, код создает файл ErrorDetails.text в C:\TestResults.
Листинг 1. Пример кода для сбора данных в виде Problems
public void errorDetails(String headline_ErrorFile) {
// Вы можете передать заголовок базы тестирования
// в метод errorDetails в качестве аргумента
String path_ProblemView = "Window->Show View->Problems";
// Путь или шаги по открытию вида Problems для сбора данных
String path_ErrorDetails = "C:\\TestResults\\ErrorDetails.text";
// Путь к создаваемому дополнительному файлу журнала.
AppObject.ObjectMapper p1 = new AppObject.ObjectMapper();
p1.getMenu().click(atPath(path_ProblemView));
ITestDataTreeNodes tn= p1.getProblems_View().getTreeHierarchy().getTreeNodes();
int rootcount=tn.getRootNodeCount();
if (rootcount != 0) {
String Heading = tn.getRootNodes()[0].getNode().toString();
if (Heading.contains("Errors")) {
int entry = tn.getRootNodes()[0].getChildCount();
p1.getProblems_View().click(atPath(Heading + "->Location(PLUS_MINUS)"));
String heading = headline_ErrorFile + "\r\n";
StringBuffer str = new StringBuffer(heading);
int ErrorCount = 1;
while (ErrorCount <= entry) {
String Source = " "+ ErrorCount + "-" +
tn.getRootNodes()[0].getChildren()[ErrorCount - 1].getNode().toString()+ "\r\n";
str = str.append(Source);
ErrorCount++;
}
try {
BufferedWriter out = new BufferedWriter(new FileWriter(path_ErrorDetails, true));
out.write(str.toString());
out.close();
} catch (IOException e) {
System.out.println("Please check the file ");
}
}
}
}
|
Сбор информации в виде Error Log (файл) журнала
В дополнение к фиксации в виде Problems ошибок и предупреждений времени компиляции, в файл журнала рабочего пространства Eclipse записываются исключительные ситуации времени исполнения. Таким образом, необходимо проверять этот файл после выполнения каждого сценария, а также во время выполнения теста. Проверка файла после каждого сценария гарантирует, что можно будет определить, какие исключительные ситуации к какому сценарию относятся.
В следующем примере кода сначала проверяется, сделана ли запись в файл журнала после завершения варианта тестирования. Если в журнале нет записи, код пропускает остаток метода, потому что вариант тестирования выполнен правильно и никакой информации для сбора нет. Если файл журнала содержит записи, код создает текстовый файл на основе имени сценария, сканирует файл журнала и записывает данные в этот текстовый файл.
Листинг 2. Пример кода для сбора данных в файле журнала
public String workspace = "C:\\Sampleworkspace\\.metadata\\.log";
// Путь к источнику для сбора данных, который можно передать
// как аргумент метода
public void createLogs(String LogPath) {
/* В LogPath указывается местоположение нового файла для хранения информации, например
"C:\\TestResults\\" + "Test Scenario" + ".txt"; */
AppObject.ObjectMapper p1 = new AppObject.ObjectMapper();
p1.getMenu().click( atPath ("Window->Show View->Other..."));
p1.getShowViewTree().click( atPath ("General->Error Log"));
p1.getOk_PaletteView().click();
int entry1 = p1.getErrorLog_View().getTreeHierarchy().getTreeNodes().getRootNodeCount();
if (entry1 != 0) {
try {
Scanner scanner = new Scanner(new File(workspace));
scanner.useDelimiter(System. getProperty ("line.separator"));
StringBuffer str = new StringBuffer("Complete Stack traces of All components");
while (scanner.hasNext()) {
String lineData = scanner.nextLine();
str.append("\r\n" + lineData);
try {
BufferedWriter out = new BufferedWriter(new FileWriter(LogPath, true));
out.write(str.toString());
out.close();
} catch (IOException e) {
System. out .println("Please check the file ");
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
|
Фильтрация собранной информации (журналы)
В предыдущих примерах создаются дополнительные журналы, но не определяется значимость содержащейся в них информации. При определении и анализе проблем группы разработки в первую очередь интересуются ошибками или исключительными ситуациями, которые связаны с их компонентами. В этом разделе рассказывается, как отфильтровать созданные журналы. Для фильтрации журнала в качестве параметра передается строковая переменная с информацией, по которой необходимо выполнить фильтрацию, например, именем компонента или плагина.
Необходимо передать месторасположение фильтруемого файла журнала в качестве параметра, в котором можно использовать имя сценария (например, C:\TestResults\Test Scenario_Filter.txt) вместе со строкой для фильтрации файла журнала. Значение LogPath такое же, что и в приведенном выше методе, и должно представлять собой имя фильтруемого файла.
Листинг 3. Пример кода для фильтрации/сортировки заданных журналов
public void createFilterLogs(String Filter, String LogPath, String FilterLogPath) {
try {
Scanner scanner = new Scanner(new File(LogPath));
scanner.useDelimiter(System. getProperty ("line.separator"));
boolean stackFound = false;
StringBuffer str = null;
while (scanner.hasNext()) {
while (scanner.hasNext()) {
String lineData = scanner.nextLine();
if (lineData.startsWith("!STACK")) {
stackFound = true;
String heading = "Stack Trace of our Component \r\n";
str = new StringBuffer(heading);
}
if (stackFound) {
str.append("\r\n" + lineData);
if (lineData.equals("")) {
stackFound = false;
break;
}
}
}
if (str != null) {
if (str.toString().contains(Filter)) {
try {
BufferedWriter out=new BufferedWriter(new FileWriter(FilterLogPath, true));
out.write(str.toString());
out.close();
} catch (IOException e) {
System. out .println("Please check the file ");
}
}
}
}
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
|
Используя вышеприведенные методы, вы получили модифицированные отфильтрованные журналы, как показано на рисунке 3. Файл ErrorDetails содержит ошибки компиляции, которые имели место в рабочем пространстве для всех выполненных тестов, в том числе записи, не показанные на снимках Rational Functional Tester из-за прокрутки.
Рисунок 3. Список созданных файлов журналов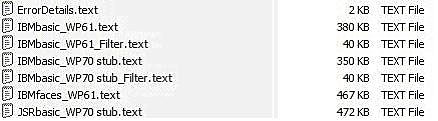
На рисунке 3 перечислено несколько файлов, например, IBMbasic_WP61.text, IBMbasic_WP70 stub.text, IBMfaces_WP61.text и JSRbasic_WP70 stub.text. Однако только два файла имеют слово _Filter в составе своих имен. Это означает, что только эти два сценария содержат исключительные ситуации, соответствующие строке Filter в коде, и представляют интерес для определения проблемы.
На рисунке 4 показано содержимое обычного файла ErrorDetails.text. На основе этого файла можно определить ошибки компиляции, которые связаны с определенным вариантом тестирования. На рисунке 4 можно увидеть запись "Error while creating jsrbasicPortlet Targeted on WebSphere portal v6.1". Это заголовок, переданный в метод errorDetails () как строка (ее можно настроить или получить путем объединения нескольких параметров, используемых в конкретном варианте тестирования), и следующий за заголовком пронумерованный список проблем, которые перечислены в виде Problems при выполнении варианта тестирования.
Рисунок 4. Содержимое файла ErrorDetails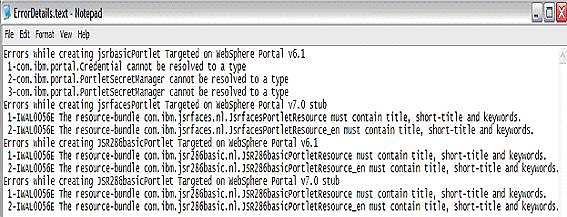
Преимущества данного подхода:
- Журналы представляют подробную информацию об исключительных ситуациях и ошибках компиляции, способствующую выявлению дефектов и путей их устранения.
- Журналы доступны сразу после завершения сценария теста, т.е. не нужно ждать завершения всех сценариев, чтобы приступить к анализу журналов. Тем самым ускоряется определение проблем.
- Исключительные ситуации, соответствующие фильтруемой строке, копируются в файлы, к именам которых добавляется
_Filter. Это позволяет идентифицировать и изучить в первую очередь значимые журналы, а другие исследовать позже. - Журналы можно сохранить и использовать при будущем анализе ошибок в конкретном варианте, который уже использовался ранее.