
При хранении неструктурированного контента (видео, слышио, документы, ...) в реляционной базе классически рассматриваются две опции: 1) загонять контент в блобы; 2) хранить его в файловой системе, ограничившись переносом в реляционную таблицу основных (как правило, скалярных) атрибутов файла: тип, название, автор, путь и т.д. Каждый подход имеет свои недостатки. В первом случае это тяжелая нагрузка на журнал плюс предел объема каждой блобовской ячейки в 2 ГБ, который по мере развития носителей приобретает все более ограничительный характер, во втором нет никакой связи между таблицей и файлами, на которые она ссылается. Их можно переносить, переменовывать, удалять, и SQL Server про это ничего не узнает. Происходит потеря целостности. Появившийся в SQL Server 2008 тип filestream является своего рода осколком Атлантиды, некогда известной под именем WinFS. Он позволяет совместить оба подхода, преодолев недостатки каждого: хранить блобы в файловой системе, обеспечив клиенту к ним стриминговый доступ, с другой стороны вся работа с этими файлами происходит под полным контролем SQL Server, который обеспечивает по ним транзакционность, бэкап, полнотекст, репликацию, лог шиппинг, кластеризацию и прочие дела, за которые он обычно отвечает. Строго говоря, файлстрим не является типом. Это просто атрибут на блобовскую колонку, говорящий SQL Server хранить ее в виде отдельного файла. Размер блоба при этом ограничен только размерами тома.
Для поддержки типа FileStream требуется на уровне базы завести соответствующую файл-группу. В качестве flename для этой группы выступает локальная папка в файловой системе. Мы не можем взять файл по произвольному пути, подсунуть его SQL Serverу и сказать: смотри, это будет твоим полем файлстрим в такой-то записи. Как мы увидим далее, мы можем лишь скопировать содержимое этого файла в поле, а храниться оно будет в том файле, который отведет ему SQL Server и назовет в соответствии со своими правилами.
- use tempdb
-
-
- if exists(select 1 from sys.databases where name = 'TestFS') begin
-
- alter database TestFS set single_user with rollback immediate
-
- drop database TestFS
-
- end
-
-
- create database TestFS on
-
- primary (name = TestFS_data, filename = 'c:\Temp\TestFS_data.mdf'),
-
- filegroup FG1 contains filestream
-
- (name = TestFS_media, filename = 'c:\Temp\TestFS_media')
-
- log on (name = TestFS_log, filename = 'c:\Temp\TestFS_log.ldf')
-
-
- use TestFS
Вот, что появилось после создания базы в директории c:\Temp:
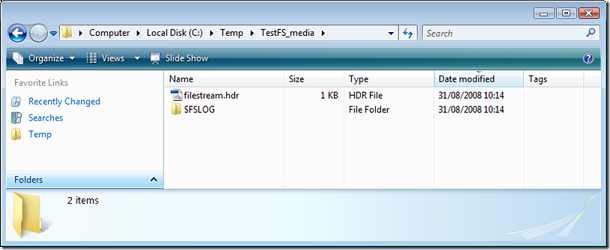
Прописанный в filestreamовской группе filename представляет собой фолдер на локальном диске. Если предложить файловую шару, обматерит:
create database TestFS1 on
primary (name = TestFS_data, filename = 'c:\Temp\TestFS_data.mdf'),
filegroup FG1 contains filestream
(name = TestFS_media, filename = '\\192.168.0.1\c$\Temp\TestFS_media')
log on (name = TestFS_log, filename = 'c:\Temp\TestFS_log.ldf')
-----------------------------------------------------------------------------------
Msg 5135, Level 16, State 2, Line 1
The path '\\192.168.0.1\c$\Temp\TestFS_media' cannot be used for FILESTREAM files. For information about supported paths, see SQL Server Books Online.
Msg 1802, Level 16, State 2, Line 1
CREATE DATABASE failed. Some file names listed could not be created. Check related errors.
Указанный путь должен существовать вплоть до n-1-го уровня, в нашем случае - c:\Temp. Фолдер TestFS_media существовать не должен.
Можно создавать несколько файл-групп типа файлстрим:
- create database TestFS1 on
-
- primary (name = TestFS_data, filename = 'c:\Temp\TestFS_data1.mdf'),
-
- filegroup FG1 contains filestream
-
- (name = TestFS_media1, filename = 'c:\Temp\TestFS_media1'),
-
- filegroup FG2 contains filestream
-
- (name = TestFS_media2, filename = 'c:\Temp\TestFS_media2')
-
- log on (name = TestFS_log, filename = 'c:\Temp\TestFS_log1.ldf')
однако в файлстримовской файлгруппе может быть прописан только один фолдер. Так делать нельзя:
...
filegroup FG1 contains filestream
(name = TestFS_media, filename = 'c:\Temp\TestFS_media'),
(name = aaa, filename = 'c:\aaa')
...
Т.е. автоматически разгонять файлстримовские файлы по разным папкам не получится.
После создания базы с файлстримовской файл-группой можно создавать таблицы с файлстримовскими полями. В операторе CREATE TABLE поле типа filestream - это обыкновенный блоб (varbinary(max)) с атрибутом filestream.
- create table Media (
-
- id int identity primary key,
-
- [guid] uniqueidentifier default newid() unique rowguidcol not null,
-
- [fileName] nvarchar(256),
-
- contentType nvarchar(256),
-
- blob nvarchar(max),
-
- stream varbinary(max) filestream
-
- )
При наличии в таблице поля filestream обязательным также является наличие поля uniqueidentifier. Оно может быть без дефолтного значения, но три атрибута: unique, rowguidcol, not null являются для него обязательными. Хотя uniqueidentifier на то и uniqueidentifier, чтобы быть unique, это условие требуется, чтобы, например, в новую запись не попало значение из предыдущей. Кроме того, оптимизатор намного радостней себя чувствует, когда видит явный unique. Атрибут rowguidcol позволяет обращаться к полю не по имени, а как $rowguid: напр., select $rowguid from Media. Понятно, что такое поле должно быть одно на таблицу. Какую принципиальную важность привносит этот атрибут, я, честно говоря, сказать не берусь. Просто бывают ситуации, которые его требуют, и быть посему. Раньше к ним относилась merge-репликация, сейчас вот добавился файлстрим.
Наличие primary key не является обязательным. В данном случае мы могли бы обойтись без поля id. Я его ввел здесь ради удобства, т.к. в примере писать where id = <целое> проще, чем запоминать гуид.
Апостериори узнать, имеет ли поле атрибут filestream, можно так:
select * from sys.columns where object_id = object_id('Media', 'table') and system_type_id = type_id('varbinary') and max_length = -1 and is_filestream = 1
По создании таблицы в C:\Temp\TestFS_media (параметр filename группы filestream при создании базы) появилась директория по имени некоторого гуида, соответствующая таблице, в ней - еще одна тоже с именем какого-то гуида, соответствуюшая полю filestream в этой таблице (их может быть несколько по числу таких полей).
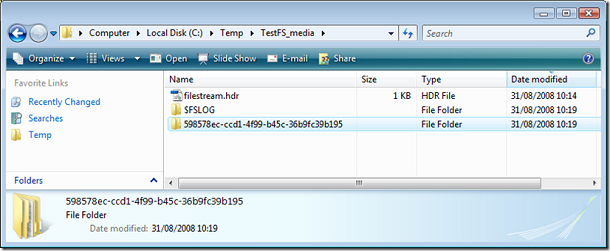
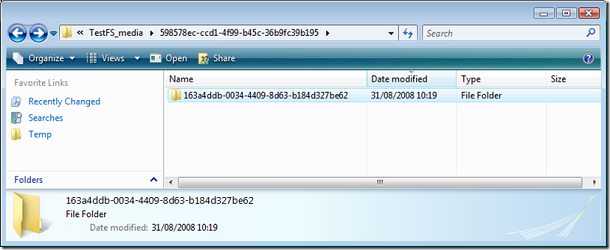
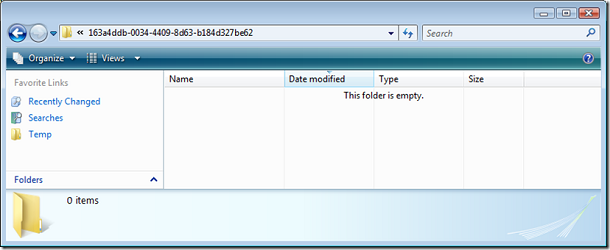
Давайте теперь добавлять в нее записи:
- insert Media(stream) values (cast(N'aaa' as varbinary(max)))
-
- insert Media(stream) values (cast(N'bbb' as varbinary(max)))
-
- insert Media(stream) values (cast(N'ccc' as varbinary(max)))
После вставки в листовой директории появилось три файла с именами гуидов, соответствующие трем вставленным записям. Под NULLовое значение файл не заводится, в блобе должно быть что-то непустое. Пустая строка - это уже непустота.
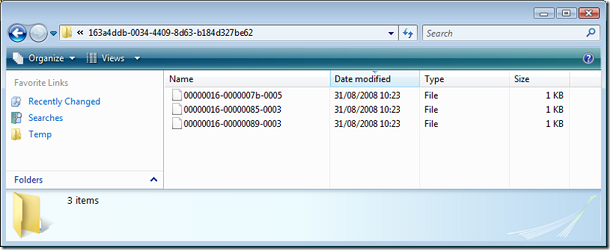
Файлы можно независимо открывать, читать и править обычным текстовым редактором. Вот, что у нас есть сейчас в первом файле.
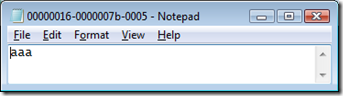
Вот мы его подредактировали:
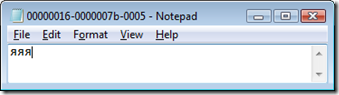
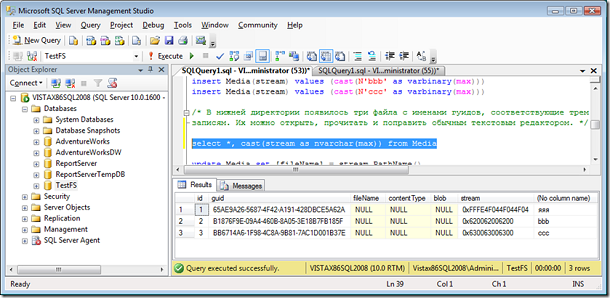
сохранили и посмотрели, что получилось:
- select *, cast(stream as nvarchar(max)) from Media
В качестве примера того, как это все находится под контролем SQL Server, посмотрим, как файлстримы бэкапятся вместе с базой. Делаем
- backup database TestFS to disk = 'c:\Temp\Test_FS.bak' with init
Затем дропаем базу, при этом фолдер TestFS_media исчезает из c:\Temp вместе со всеми своими файлами, в которых хранилось содержимое поле файлстрим от разных записей таблицы Media. Ресторим базу:
- restore database TestFS from disk = 'c:\Temp\Test_FS.bak' with move 'TestFS_media' to 'c:\aaa'
Здесь WITH MOVE - стандартная опция, в которой при восстановлении указывается, что логические имена файлов теперь будут соответствовать другим физическим путям. Мы говорим, что c:\Temp\TestFS_media переезжает в с:\aaa. При этом на диске с: автоматически создается фолдер aaa, куда развернулась файлстримовская файлгруппа. Так же, как и при создании базы, весь указываемый путь должен существовать от корня диска до уровня n-1, т.е. если бы мы сказали with move 'TestFS_media' to 'c:\aaa\bbb', не прокатило бы.
Контроль контролю рознь. SQL Server не воспрепятствует попытке удалить файл, соответствующий блобу. Точно так же, как мы его правили текстовым редактором в примере выше, можете зайти и просто его грохнуть средствами ОС. Вам за это ничего не будет, кроме укоров совести, потому что когда SQL Server в следующий раз обратится к этой ячейке и не найдет соответствующий ей файл, он расстроится и будет долго плакать. Чтобы до этого не доводить, можно порекомендовать не раздавать кому ни попадя права на папки, занятые под файлстримовские группы SQL Server. В идеале на c:\Temp\TestFS_media нужно дать права SQL Serverному эккаунту, а у остальных отобрать от греха.
Как и HierarchyID, про который я изрядно разглагольствовал в предыдущих постах, и геопространственные типы, разглагольствования на тему которых еще впереди, тип filestream поддерживается в бесплатном SQL Server, который SQL Express. Более того, ограничения на размер базы для SQL Express не распространяются на те данные, что лежат в файлстримовских блобах.