
Вопрос: Мы используем много распределенных транзакций и теперь исследуем возможность использования зеркального отображения для обеспечения высокой доступности одной из наших критически важных баз данных. В процессе тестирования мы обнаружили, что иногда распределенные транзакции терпят неудачу при попытке перейти на зеркальную базу данных. Вы не могли бы объяснить, в чем тут дело?
Ответ:Вообще говоря, это задокументированное ограничение на использование распределенных транзакций. Ограничение распространяется на зеркальное отображение базы данных и доставку журналов, и вообще на любую технологию, в которой после перехода на другой ресурс меняется имя Windows-сервера.
При использовании координатора распределенных транзакций локальный координатор обладает идентификатором ресурса, указывающим на сервер, на котором он выполняется. При переходе на другой ресурс в условиях зеркального отображения основной становится база данных, расположенная на другом сервере (участнике зеркального отображения), поэтому идентификатор ресурса координатора другой.
Если распределенная транзакция активна, координатор транзакций на участнике зеркального отображения пытается выяснить состояние транзакции и ему это не удается из-за другого идентификатора ресурса. Координатор не распознает его, так как изначально не участвовал в распределенной транзакции.
Подобная проблема может наблюдаться в транзакциях с перекрестными транзакциями (простыми транзакциями, вносящими обновления в более чем одну базу данных). В условиях, когда одна из вовлеченных в транзакцию баз данных поддерживает зеркалирование, а другая - нет, возможна фиксация перекрестной транзакции в обеих базах данных. Однако если произойдет принудительный переход на зеркальный ресурс (когда основная база и зеркало не синхронизированы и выполняется ручной переход, позволяющий потерю данных), зафиксированная в зеркальной базе данных транзакция может потерпеть неудачу, при этом нарушится целостность перекрестной транзакции.
Это может произойти, если отраженная база данных не находится в состоянии SYNCHRONIZED (подробнее см. мою колонку в журнале за июнь 2009 года), то есть журнальные записи зафиксированной перекрестной транзакцию пока еще не попали на зеркало. После принудительного перехода транзакция не существует в новой основной базе данных и целостность перекрестной транзакции нарушается.
Вопрос:Недавно я проконтролировал показания некоторых счетчиков производительности в попытках выяснить причину неполадок с нашим хранилищем базы данных. При этом я заметил что-то очень странное: хотя в базе данных ничего не происходило, шла активная запись в файлы базы данных, причем файлов как данных, так и журналов. Я даже удостоверился, что при этом не было никаких подключений к SQL Server. Как может быть, что в отсутствие подключений активно выполняются операции ввода-вывода?
Ответ:SQL Server выполняет много обязательных вспомогательных операций, их называют фоновыми задачами. Одна или несколько таких задач и вызывают активный ввод-вывод. Вот лишь несколько "подозреваемых":
Очистка фантомных записей:Операция удаления только отмечает записи как удаленные - это механизм оптимизации производительности на случай отмены операции - при этом физически пространство не обнуляется. При фиксации операции удаления кто-то должен физически удалить удаленные записи из базы данных. Эту работу выполняет задача очистки фантомных записей. Подробнее об этом можно прочитать данной публикациив моем блоге, где также объясняется, как узнать, выполняется ли эта задача в системе.
Автоматическое сжатие:Эта задача автоматически удаляет пустое пространство в базе данных. Она перемещает страницы с конца файлов данных в начало, таким образом консолидируя свободное пространство в конце файла, и затем усекает файлы. Вы можете включить эту задачу, но это совсем не обязательно - она вызывает проблемы фрагментации индексов (что снижает производительность) и использует много ресурсов. Обычно в базе данных активировано автоматическое увеличение размера файла, поэтому так очень легко организовать бесконечный цикл "сжатия-увеличения" и масса работы будет выполняться впустую. Проверить состояние всех баз данных позволяет такой запрос:
SELECT name, is_auto_shrink_on FROM sys.databases
SEОтложенное освобождение:Эта задача отвечает за удаление или усечение таблиц и индексов (усечение индексов может требоваться из-за операции перестроения индексов, когда после создания нового индекса старый удаляется). В маленьких таблицах и индексах освобождение выполняется немедленно, а в больших - фоновой задачей. При этом нужно гарантировать, что все необходимые блокировки будут получены без превышения размера доступной памяти. Для контроля этой задачи можете использовать счетчики производительности, контролирующие отложенное освобождение.
Отложенная запись:Эта задача удаляет старые страницы из кеша в памяти (его еще называют буферным пулом). Когда сервер близок к недостатку памяти, страницы могут удаляться даже при наличии изменений в них. В том случае измененная страница должна быть записана на диск до ее удаления из памяти. Для наблюдения за этой задачей можно использовать счетчик "Lazy writes/sec", как это описано здесь в разделе Books Online.
Все эти задачи могут вносить изменения в базу данных. В них изменения выполняются в рамках транзакций, но при каждой фиксации транзакции сгенерированные записи журнала транзакций должны записываться в журнальную часть базы данных на диске. При каждом изменении базы данных должна создаваться контрольная точка для сброса измененных страниц файла данных на диск. Подробнее об этом рассказывается в моей статье в выпуске журнала TechNet Magazine за февраль 2009 в статье Understanding Logging and Recovery in SQL Server..
Как видите даже в отсутствие активных подключений к SQL Server, на нем может выполняться несколько фоновых задач. Если операции ввода-вывода продолжаются давно после завершения операций с базой данных, рекомендуем проверить, не выполняются ли какие-либо запланированные задания.
Мне поневоле пришлось принять на себя обязанности администратора базы данных, и я знакомлюсь с различными функциями, чтобы быстро освоить SQL Server. Предыдущий администратор создал задания создания резервных копий файла, но я не могу выяснить, как использовать их для восстановления. Существует ли способ увидеть, какие резервные копии находятся в файле? И как правильно задействовать их для восстановления?
Ответ:Хотя резервные копии могут добавляться в конец существующего файла, большинство администраторов размещают резервные копии в отдельных файлах, которым дают информативные имена (обычно содержащие дату и время). Это позволяет избежать некоторых проблем и облегчает выполнение других задач:
- копирование резервных копий для обеспечения их безопасности упрощается, когда каждая резервная копия размещается в отдельном файле. Если все резервные копии находятся в одном файле, копию последней резервной копии можно получить, только скопировав весь файл с резервной копией;
- удаление старых резервных копий невозможно, когда все резервные копии находятся в одном файле;
- случайная запись поверх существующих резервных копий практически невероятна, если резервные копии размещаются в отдельных специально поименованных файлах.
К сожалению, эта информация бесполезна в вашей ситуации - у вас уже есть файл со многими резервными копиями. Есть два способа восстановления из резервных копий: вручную или средствами среды SQL Server Management Studio (SSMS).
Чтобы узнать, какие резервные копии находятся в файле, можно в SSMS создать "Новое устройство резервного копирования" (New Backup Device), ссылающееся на этот файл. Создав такую ссылку. можно узнать, что есть в этом устройстве резервного копирования. С другой стороны, можно воспользоваться командой RESTORE HEADERONLY. В любом случае анализируется резервное устройство и возвращается одна строка выходных данных, описывающих каждую резервную копию в файле. SSMS снабжает типы резервных копий информативным именем. Используя правильный синтаксис, можно узнать тип каждой резервной копии и задействовать соответствующую команду RESTORE для восстановления из резервной копии. Подробнее см. электронную документацию по SQL Server (в данной статье мы используем справку для версии SQL Server 2008).
Вам придется выяснить, какие резервные копии выбрать для восстановления. В этом есть несколько хитрых моментов, потому что нужный столбец результата выполнения запроса RESTORE HEADERONLY не соответствует параметру, который надо использовать для восстановления. Резервные копии в файле пронумерованы, начиная с единицы, причем единица соответствует самой старой резервной копии. Номер указывается в столбце Position. Чтобы восстановить резервную копию с определенным номером, надо использовать предложение WITH FILE=<номер> в составе команды RESTORE. Вот пример:
RESTORE DATABASE test FROM DISK = 'C:\SQLskills\test.bak' WITH FILE = 1, NORECOVERY;RESTORE LOG test FROM DISK = 'C:\SQLskills\test.bak'
WITH FILE = 2, NORECOVERY
И так далее. Последовательность восстановления начинается с создания резервной копии базы данных, после чего надо восстановить базу данных из одной или нескольких разносных резервных копий базы данных и/или резервных копий журнала транзакций (впрочем, разностных резервных копий может и не быть). Подробности дальнейших операций выходят за рамки этой рубрики, но вы можете почитать подробнее о последовательностях восстановления и других вариантах использования команды RESTORE, которые могут вам понадобиться, в моей статье в выпуске журнала за ноябрь 2009 года.
Используя SSMS, файл с резервной копией задают в Мастере восстановления баз данных, а тот автоматически покажет все имеющиеся в файле резервные копии и позволит выбирать нужные (рис. Пример показан на рис. 1.
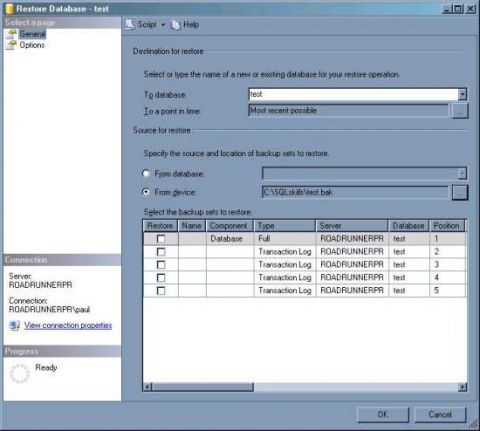
Использование Мастера восстановления баз данных в SSMS для отображения имеющихся в файле резервных копий
Какой вариант вы бы не выбрали, исключительно важно перед попыткой восстановить производственную систему поупражняться на тестовой системе. Один из моих любимых принципов: "Нельзя говорить, что у вас есть резервная копия, пока вы успешно не восстановили систему из нее".
Вопрос:У меня довольно большая база данных, которую надо копировать каждые несколько недель в среду разработки. Моя проблема состоит в том, что база данных была недавно увеличена в ожидании поступления большого объема данных и теперь она занимает слишком много места при восстановлении в среде разработки. Как сделать базу данных меньше при восстановлении?
Ответ: Это довольно популярный вопрос, на который, к сожалению, нет удовлетворительного ответа.
В процессе резервного копирования база данных никак не изменяется - просто считываются все используемые части базы данных и включаются в резервную копию, туда же включается часть журнала транзакций (в моем блоге вы узнаете подробнее о том, почему это происходит и какая часть журнала попадает в резервную копию). Процесс восстановления из резервной копии базы данных просто создает файлы, записывает содержимое резервной копии, после чего выполняет восстановление базы данных. Вообще говоря, все, что было в исходной базе данных, оказывается в восстановленной версии. Нет никакой возможности при восстановлении сжать базу данных, решить проблему фрагментации индекса, обновить статистику или выполнить любую из других операций, которые обычно хотят выполнить.
Так, как же все-таки добиться желаемого? В зависимости от конкретной ситуации можно выбрать один из трех возможных вариантов.
Во-первых, можно выполнить операцию сжатия на производственной базе данных, чтобы вернуть в систему пустое пространство. В этом случае восстановленная копия базы данных будет содержать все то же, что и производственная база, но без лишнего пустого пространства. Однако цена этого решения высока. Производственную базу данных придется потом снова расширить, а операция сжатия чрезвычайно ресурсоемка (высокая нагрузка на процессор, много операций ввода-вывода и увеличивается размер журнала транзакций) и вызывает фрагментацию индексов. Фрагментацию индексов придется устранить, на что потребуются еще ресурсы. Это далеко не самый удачный вариант. (Подробнее об опасностях сжатия файла данных см. мой блог.) Можно попытаться удалить свободное пространство в конце файла (DBCC SHRINKFILE WITH TRUNCATEONLY), но это вряд ли даст желаемое сокращение размера.
Во-вторых, если требуется только восстановить производственную базу данных один раз в среде разработки, надо предусмотреть достаточно места для восстановления полноразмерной базы данных, а затем сжать ее для освобождения пространства. После этого надо решить, стоит ли избавляться от фрагментации, возникшей из-за сжатия.
Если вы собираетесь тестировать производительность выполнения запросов или создания отчетов, фрагментация может сильно снизить производительность. В противном случае можно не обращать внимание на фрагментацию. Для решения проблемы фрагментации нельзя перестроить индексы (командой ALTER INDEX … REBUILD), поскольку это потребует дополнительного пространства и вызовет рост базы данных - надо реорганизовать индексы (командой ALTER INDEX … REORGANIZE).
Если вы все-таки решите избавиться от фрагментации, надо не забыть использовать простую модель восстановления, чтобы журнал транзакций не увеличивался за счет записей, создаваемых при реорганизации. Если базу данных оставить в полной модели восстановления, файл журнала продолжит расти, если только не создавать резервные копии журнала, но уж эта операция совершенно лишняя, если требуется просто получить копию базы данных в среде разработки.
В-третьих, если вам нужно часто восстанавливать промышленную базу данных в среде разработки, вам наверняка не захочется выполнять все операции, описанные во втором варианте. В этом случае лучше всего следовать инструкциям второго варианта, после чего создать еще одну резервную копию сжатой (и возможно дефрагментированной) базы данных.
Эта вторая резервная копия может далее использоваться для многократного восстановления промышленной базы данных минимального размера.
Резюме: нет простого способа переноса в среду разработки производственной базы данных с максимальным размером свободного пространства без необходимости предусмотреть свободное пространство, необходимое для начального восстановления.