
Если предыдущий пост предназначался исключительно для пользователей программы "Пинговалка", то этот - для разработчиков. Сегодня будем разбираться с sitemap.xml.
В целом sitemap может пригодится для чего угодно, начиная от того, чтобы просто получить список всех страниц, так и, например, для того, чтобы по полученному списку в дальнейшем спарсить названия страниц, проверить индексацию в поисковиках и т.д. Зная путь к sitemap, можно сэкономить достаточно много времени на получение необходимой информации по сайту.
Как и сказано в заголовке поста - использовать будем две бесплатные, кроссплатформенные библиотеки - Synapse и NativeXML.
Прежде, чем перейдем к реализации чтения sitemap в Delphi, немного разберемся с тем, что нас ждет.
Немного слов про Sitemap
Файл Sitemap представляет собой XML-файл, в котором перечислены URL-адреса веб-сайта в сочетании с метаданными, связанными с каждым URL-адресом. В качестве мета-данных, в sitemap может содержаться следующая информация: дата последнего изменения, частота изменений, приоритетность на уровне сайта.
Sitemap используется для того, чтобы поисковые системы могли более грамотно сканировать сайт.
Например, запись отдельного URL с мета-данными может выглядеть так:

Если сайт более менее старенький, то его Sitemap может насчитывать тысячи URL. К примеру, sitemap моего блога насчитывает сейчас 865 страниц, включая страницы по тегам. А если взять какой-нибудь варезник где обновления могут проходить по 100 штук на день? Или раскрученный, популярный форум? Там sitemap может насчитывать достаточно большое количество страниц. Поэтому разработчики протокола Sitemap сделали ограничение - 50000 URL на один файл. Также файл должен быть размером до 10 Мб.
Если передается информация по 50000+ страницам, то в поисковую систему отправляется индексный файл Sitemap. В этом фале перечислены пути к XML-файлам в которых содержаться уже URL"ы страниц. Запись в индексном файле может выглядеть так:

Все данные в Sitemap передаются в кодировке UTF-8. Вот, пожалуй, вся та информация, которая нам пригодится для разработки. Теперь перейдем к реализации нашей программы.
Парсим Sitemap в Delphi
Напишем небольшую программу, которая будет без лишних вопросов скачивать и парсить sitemap любого вида - как с индексным файлом, так и без него. Для этого, вначале немного определимся с алгоритмом. Работать будем так:
- Скачиваем файл по заданному URL
- Читаем файл и определяем является ли он индексным
- Если мы скачали индексный sitemap, то получаем из него ссылки на другие файлы и скачиваем эти файлы
- Парсим все скачанные файлы на предмет информации по URL.
Получать будем всю доступную информацию - адреса, явки, пароли, даты изменения, приоритеты и т.д.
Начнем с описания необходимых типов данных. Каждый элемент в sitemap будет представлен в виде записи (record):
type
TSitemapElement = record
loc: string; //URL страницы
lastmod: TDate; //дата последнего изменения
changefreq: string;//частота обновления
priority: currency;//приоритет внутри сайта
end; |
Загружать и обрабатывать Sitemap будем в отдельном потоке:
TOnGetElement = procedure (Element:TSitemapElement) of object;
TSitemapLoader = class(TThread)
private
FHeaderXML: TNativeXML; // индексный файл XML
FSitemapURL: string; // URL базового сайтмапа
FURLList: TStrings; // список всех url где есть сайтмапы
FChankedXML: array of TNativeXML; // массив всех сайтмапов
FOnGetElement: TOnGetElement;
FOnLoadDone : TNotifyEvent;
function TryLoadHeadSitemap: boolean; // пробуем закачать головной сайтмап
function IsChanked: boolean;
procedure LoadFile(URL: string);
procedure ParseXML(XML: TNativeXML);
public
constructor Create(Syspended: boolean; AAddress: string);
property OnGetElement : TOnGetElement read FOnGetElement write FOnGetElement;
property OnLoadDone : TNotifyEvent read FOnLoadDone write FOnLoadDone;
protected
procedure Execute; override;
end; |
Для потока определено всего два события:
- OnGetElement - будет срабатывать каждый раз как только мы будем получать готовую запись TSitemapElement;
- OnLoadDone - сработает всего один раз, когда поток завершит свою работу
Теперь жмем Ctrl+Shift+C и, если у вас Delphi не Starter Edition, то IDE создаст вам "скелеты" методов потока. рассмотрим их подробнее.
Конструктор:
constructor TSitemapLoader.Create(Syspended: boolean; AAddress: string); begin inherited Create(Syspended); FHeaderXML := TNativeXML.Create; FSitemapURL := AAddress; FURLList := TStringList.Create; end; |
Метод TryLoadHeadSitemap пробует скачать XML-файл, URL которого был задан в конструкторе. Если файл успешно скачан и помещен в поле FHeaderXML (скачать мы можем и не XML), то метод вернет нам True:
function TSitemapLoader.TryLoadHeadSitemap: boolean;
begin
with THTTPSend.Create do
begin
if HTTPMethod('GET', FSitemapURL) then
begin
try
FHeaderXML.LoadFromStream(Document);
Result := true;
except
Result := false;
end;
end
else
Result := false;
end;
end; |
IsChanked проверяет является ли загруженый в методе TryLoadHeadSitemap XML-файл индексным. Если файл индексный, то в этом же методе считываются URL'ы всех sitemap, содержащих данные по страницам сайта:
function TSitemapLoader.IsChanked: boolean;
var
NodeList: TXmlNodeList;
i: integer;
begin
if FHeaderXML.IsEmpty then Exit;
Result := FHeaderXML.Root.NodeByName('sitemap') <> nil;
FURLList.Clear;
if Result then
begin
NodeList := TXmlNodeList.Create;
FHeaderXML.Root.NodesByName('sitemap', NodeList);
for i := 0 to NodeList.Count - 1 do
FURLList.Add(NodeList[i].NodeByName('loc').ValueAsString);
end
end; |
LoadFile грузит XML-файл, засположенный по адресу URL и, если файл загружен успешно, то этот файл заносится в массив FChankedXML:
procedure TSitemapLoader.LoadFile(URL: string);
var
XML: TNativeXML;
begin
with THTTPSend.Create do
begin
if HTTPMethod('GET', URL) then
begin
XML := TNativeXML.Create;
try
XML.LoadFromStream(Document);
SetLength(FChankedXML, length(FChankedXML) + 1);
FChankedXML[length(FChankedXML) - 1]:=TNativeXML.Create;
FChankedXML[length(FChankedXML) - 1].Assign(XML);
finally
XML.Free
end;
end
end;
end; |
Ну и, собственно, Execute в котором все эти методы собраны воедино:
procedure TSitemapLoader.Execute;
var i:integer;
begin
try
if TryLoadHeadSitemap then
begin
if IsChanked then
begin
for i:=0 to FURLList.Count-1 do
LoadFile(FURLList[i]);
for i:=0 to Length(FChankedXML)-1 do
ParseXML(FChankedXML[i]);
end
else
ParseXML(FHeaderXML);
end
finally
FURLList.Free;
for i:=Length(FChankedXML)-1 downto 0 do
FChankedXML[i].Free;
FChankedXML:=nil;
if Assigned(FOnLoadDone) then
FOnLoadDone(self)
end;
end; |
Теперь нам остается только разработать GUI для нашего приложения. Так как все операции по загрузке Sitemap будут у нас выполнятся по одному клику, то GUI будет аскетичным :)
1 Edit, 1 кнопка и 1 ListView для вывода результатов - всё, что нам потребуется. Вначале определим обработчики событий потока:
procedure TFMain.GetElement(Element: TSitemapElement);
begin
ListView1.Items.BeginUpdate;
try
with ListView1.Items.Add do
begin
Caption:=Element.loc;
SubItems.Add(Element.lastmod);
SubItems.Add(CurrToStr(Element.priority));
SubItems.Add(Element.changefreq)
end;
finally
ListView1.Items.EndUpdate;
end;
end;
procedure TFMain.LoadDone(Sender: TObject);
begin
ShowMessage('Загрузка завершена')
end; |
Теперь, в обработчике OnClick кнопки нам остается только правильно запустить поток. Делаем это следующим образом:
procedure TFMain.Button1Click(Sender: TObject); var Loader: TSitemapLoader; begin ListView1.Items.Clear; Loader:= TSitemapLoader.Create(true,Edit1.Text); Loader.OnGetElement:=GetElement; Loader.OnLoadDone:=LoadDone; Loader.Start; end; |
Запускаем программу, вводим в edit адрес к Sitemap, жмем кнопку и спустя несколько секунд получаем результат:
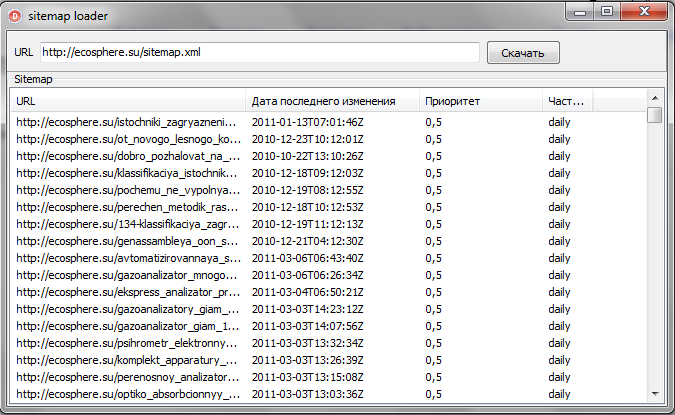
Как и ожидалось, при каждом получении элемента Sitemap наш список обновляется, но из за достаточно высокой скорости работы NativeXML обновление превращается в быстрое мельтешение ListView, поэтому по-хорошему, обновление следовало бы проводить только в самом конце работы потока, а для визуализации процесса заполнять ProgressBar, отсчитывать что-нибудь в Label и т.д. Также было бы неплохо предусмотреть вывод сообщений, в случае, если скачаный файл не содержит XML или скачивание вообще невозможно, но пусть реализация этих моментов останется в качестве самостоятельной работы тем, кто скачает исходники программы :).