
С современным уровнем развития дисциплины управления требованиями, хранение и работа с требованиями в текстовых документах кажется анахронизмом. Существует множество систем управления требованиями, и многопользовательских клиент-серверных, и однопользовательских локальных, позволяющих работать со структурой и иерархией требований, формулировками и оформлением, а также предопределенными и пользовательскими метаданными. Однако часто возникают ситуации, когда текстовый документ является необходимым. Например: техническое задание как формальный документ, подписываемый заказчиком и исполнителем; спецификация требований для согласования с заказчиком; план-график реализации требований и т.д. Фактически все эти документы - это определенный срез данных из единой базы требований по проекту. Соответственно, у пользователя должна быть возможность быстрой и удобной генерации требуемого документа, содержащего актуальную информацию.
В данной статье мы рассмотрим процесс генерации документов в системе управления требованиями Borland/Microfocus CaliberRM.
В системе Borland/Microfocus CaliberRM для генерации документов предназначена утилита Document Factory. Document Factory может генерировать документы в форматах .doc, .rtf и .txt. Принцип действия Document Factory довольно прост - это анализ шаблона документа и замена ключевых слов значениями из базы данных требований, а также выполнение команд и операторов, указанных в теле шаблона. При подготовке шаблона используются следующие термины:
- Команды (commands). С помощью команд определяется выборка, сортировка и группировка требований из базы данных.
- Ключевые слова (keywords). Ключевые слова в шаблоне подменяются на соответствующие значения из базы данных требований.
- Операторы (operators). Операторы представляют собой определенные критерии для поиска групп требований.
Все остальное оформление документа (колонтитулы, начертание, цвет и размер шрифта, таблицы, изображения, а также другие объекты) остаются в документе неизменными, то есть такими же, какие были в шаблоне.
Рассмотрим структуру шаблона. Так как в базе данных может существовать несколько проектов по работе с требованиями, а в каждом проекте может быть несколько базовых линий (baseline) требований, в шаблоне документа нужно указать наименование проекта и базовой линии с помощью команд $PROJECT и $BASELINE. Соответственно, в документ попадут только требования из указанного проекта и отмеченные заданной базовой линией. В случае если в проекте не задано базовых линий (точнее, существует только одна - Current Baseline), то команду $BASELINE можно не указывать. В случае если задано несколько базовых линий, а в шаблоне документа команда $BASELINE не указана, то при генерации документа будет выдано диалоговое окно с возможностью выбора базовой линии требований, для которой необходимо генерировать документ. При отсутствии в шаблоне документа команды $PROJECT, при генерации документа будет выдано диалоговое окно для выбора проекта. Такой подход удобен, когда используется универсальный шаблон для нескольких проектов, а генерация документа выполняется вручную. Однако при автоматической генерации по расписанию (мы рассмотрим эту возможность ниже) такой вариант неприемлем.
Для отображения определенных групп требований используется понятие секций и команды $BEGIN_SECTION и $END_SECTION. Данные команды начала и окончания секции представляют собой своеобразный цикл по требованиям в базе данных. Например, если между этими командами указать ключевое слово <<name>>, то в документе будут выведены наименования всех требований в заданном проекте. Для того чтобы выводить ограниченный набор требований по какому-либо условию используются команда $FILTER. Например, чтобы вывести в секцию только бизнес-требования, необходим следующий код (точнее текст, а не код):
$BEGIN_SECTION
…
$FILTER{type = "1. Business Requirements"}
…
$END_SECTION
Важные замечания: секций в шаблоне может быть сколько угодно много, но они не должны быть вложенными; все команды, кроме $PROJECTS, $BASELINE и пары $BEGIN_SIGNATURES/ $END_SIGNATURES должны находиться внутри секций; в одной секции может быть только одно использование одной команды.
Рассмотрим следующий пример с использованием дополнительных команд:
$BEGIN_SECTION
$FILTER{type = "3. Functional Requirements"}
$SORT{hierarchy}
$INDENTION_LEVEL{3}
$INDENTION_SIZE{.5}
<<tag>><<id_number>>. <<name>>
<<description>>
$END_SECTION
В данном примере в документ будут выведены только функциональные требования (команда $FILTER), требования будут отсортированы в порядке возрастания по иерархии (команда $SORT). Команда $INDENTION_LEVEL{3} говорит о том, что будут выведены требования только трех верхних уровней вложенности, требования более глубоких уровней будут проигнорированы. Команда $INDENTION_SIZE{.5} задает размер отступа в дюймах при выводе требований из разных уровней вложенности. Непосредственно вывод производится с помощью ключевых слов <<tag>> (тэг требования), <<id_number>> (номер требования по базе данных), <<name>> (заголовок требования) и <<description>> (текст требования). В команде $FILTER можно использовать математические и логические операции, а также слова Like, Not Like, Between, Not Between, In и Not In.
Также интерес представляют следующие команды:
- $BEGIN_LIST/$END_LIST - используется для вывода списков, например, списка ответственных исполнителей назначенных за реализацию требования.
- $BEGIN_HISTORY/$END _HISTORY - используется для вывода истории изменений требований.
- $BEGIN_TRACES/ $END _TRACES - используется для вывода информации о связях трассировки с другими требованиями.
- $BEGIN_DISCUSSIONS/ $END_DISCUSSIONS - используется для вывода дискуссий, проводимых "вокруг" требований.
- $BEGIN_GLOSSARY/ $END_GLOSSARY - используется для вывода глоссария.
- $CALCULATE - используется для выполнения элементарных математических операций (умножение, деление, сложение, вычитание) над атрибутами требований.
Наиболее часто используются следующие ключевые слова:
- <<type>> - тип требования
- <<hierarchy>> - иерархический номер
- <<id_number>> - идентификатор требования по базе данных
- <<status>> - статус требования
- <<priority>> - приоритет требования
- <<description>> - детальное описание требования (текст требования)
- <<tag>> - тэг требований (код типа требования)
- <<name>> - имя (заголовок) требования
- <<version>> - номер версии требования
- <<owner>> - текущий владелец требования
В случае если используются пользовательские атрибуты требований - их также можно использовать в шаблоне обрамляя двойными скобками: <<пользовательский_атрибут>>.
Теперь рассмотрим процесс генерации документа на основе созданного шаблона с помощью утилиты Document Factory. Утилиту можно запустить из меню "Пуск" (отобразиться окно, представленное на рис.1) или с помощью нажатия кнопки "Document Factory" из клиентской части CaliberRM (отобразиться окно, представленное на рис.2, без запроса параметров подключения).
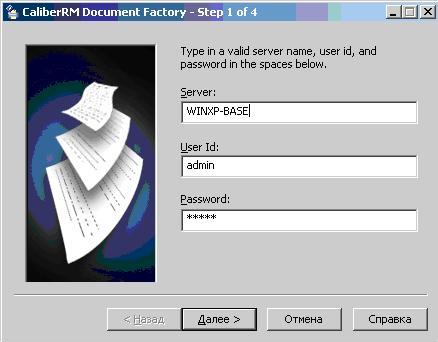
Рис.1. Параметры подключения к серверу CailberRM.
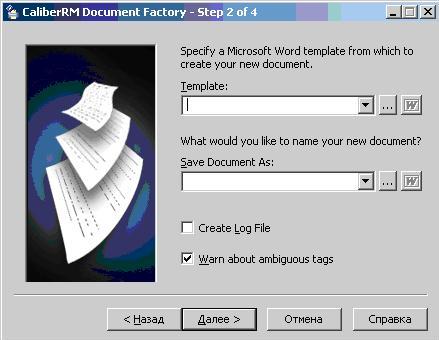
Рис.2. Указание пути к шаблону и конечному файлу.
Необходимо указать путь к файлу шаблона и путь к конечному файлу. Если необходимо при генерации создавать лог-файл - нужно поставить соответствующую галочку "Create Log File". Установка галочки "Warn about ambiguous tags" позволит выводить предупреждения о нераспознанных тегах, например, написанных с синтаксической ошибкой. После нажатия кнопки "Далее" отображается окно установки дополнительных параметров (рис.3).
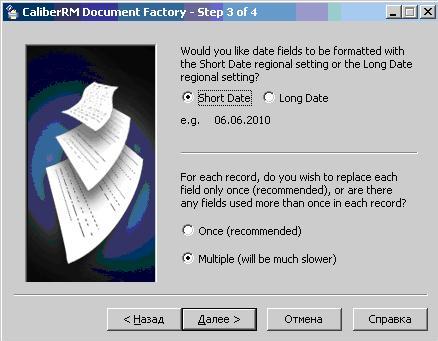
Рис.3. Установка дополнительных параметров.
В верхней части задается формат вывода даты - короткий или длинный, в нижней части задается режим вывода ключевых слов. При выборе значения Once замена ключевого слова происходит только один раз, то есть следующие вхождения данного ключевого слова заменены не будет. При выборе значения Multiple будут заменены все вхождения ключевого слова. После нажатия кнопки "Далее" отображается окно установки дополнительных параметров (рис.4).
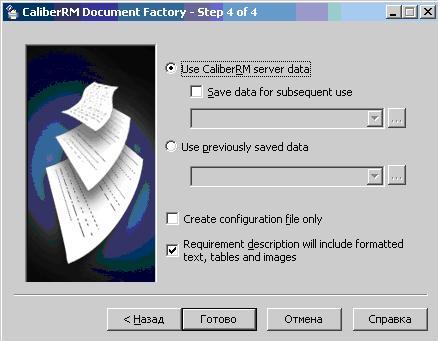
Рис.4. Установка дополнительных параметров.
На данном окне задаются следующе параметры. Источник формирования требований: из базы данных (Use CaliberRM server data) или из ранее сохраненного набора данных (Use previously saved data). Для сохранения набора данных необходимо установить галочку "Save data for subsequent use", при этом данные будут сохранены в формате mdb-файла. При установке галочки "Create configuration file only" будет сформирован конфигурационный файл с выставленными параметрами. Данный файл можно использовать для автоматизированной генерации документов по расписанию. Установкой галочки "Requirement description will include formatted text, tables and images" пользователь задает, будет ли использовано оформление требования из базы данных CailberRM или из шаблона документа. После установки дополнительных параметров необходимо нажать кнопку "Готово" для начала генерации документа.
В случае если в шаблоне не был указан конкретный проект с помощью команды $PROJECT, будет выдано окно с выбором проекта (рис.5).
Рис.5. Выбор проекта
После выбора проекта и нажатия кнопки "Ок" начинается непосредственно генерация документа (рис.6).
Рис.6. Процесс генерации документа.
В случае если генерация прошла успешно, пользователю выдается запрос на открытие сгенерированного документа. При нажатии кнопки "Да" документ будет открыт в программе Microsoft Word.
Рис.7. Запрос на открытие документа.
Теперь рассмотрим возможности автоматической генерации документов по расписанию.
Для этого необходимо использовать программу Docfactory.exe, в качестве параметра передавая конфигурационный файл, созданный ранее (рис.4), например:
C:\Program Files\Borland\CaliberRM\Docfactory.exe /conffile.ini
Затем данную команду можно запланировать на запуск с определенной периодичностью, например, с помощью стандартной программы Windows "Планировщик заданий".
Таким образом, возможности, предоставляемые CaliberRM и Document Factory, позволяют создавать практически любые документы с произвольным оформлением, содержащие информацию из базы данных требований CaliberRM.