
 Сегодня сноа занялся работой над облаком тегов на Delphi. Всё никак не мог придумать куда бы прикрутить полученный мной код: использовать в блог-клиенте? Не то…блог-клиентов пруд пруди и практически все с облаками. На сайт exe-шник тоже как-то не улыбает привинчивать. И в процессе поиска наткнулся на одну темку на серче. Речь там шла о таком понятии как " тошнота страницы ". Причем, если Вы почитаете эту тему, то увидите, что иногда сами веб-мастера путаются в том, что есть тошнота страницы , а что есть частота слова.
Сегодня сноа занялся работой над облаком тегов на Delphi. Всё никак не мог придумать куда бы прикрутить полученный мной код: использовать в блог-клиенте? Не то…блог-клиентов пруд пруди и практически все с облаками. На сайт exe-шник тоже как-то не улыбает привинчивать. И в процессе поиска наткнулся на одну темку на серче. Речь там шла о таком понятии как " тошнота страницы ". Причем, если Вы почитаете эту тему, то увидите, что иногда сами веб-мастера путаются в том, что есть тошнота страницы , а что есть частота слова.
Вот я и попытался пристроить полученный мной алгоритм постоения облака тегов к практической задаче SEOшников - написать программу для расчёта тошноты произвольного текста. Т.к. любая программа должна иметь осмысленное название, то я решил назвать её в честь целого созвездия из м/ф "Шрек" (в переводе Гоблина) - Блевантон. Собственно название практически соответствует основной задаче программы.
Теперь давайте немного разберемся в теории. Что такое тошнота текста? Одно из определений звучит следующим образом:
Тошнота страницы (текста) - это величина спама на странице. Сейчас примерно равна корню квадратному из числа самого частого слова на странице. Те если на странице самое частое слово (например, www) встречается 100 раз, то тошнота равна 10. Если самое частое слово встречается менее семи раз, то тошнота равна константе = корень из семи.
Как можно заметить - в расчёте тошноты принимают участие все слова (!) в отличие от расчёта плотности ключевика, где из текста выбрасываются стоп-слова. Единственная обработка текста заключается, по-моему, в исключении из текста пробелов и управляющих символов (например, символов !, ?, " и пр.), т.к. если такую чистку не провести, то, видимо самым спамным словом как раз и будет один из управляющих символов. Если я не прав - оптимизаторы и СЕОшники поправьте . Кстати про SEO - если Вас интересует продвижение сайта, то можете зайти на сайт по ссылке или посетить мой второй блог о раскрутку блога по программированию (ссылка в сайдбаре - DelphiSEO)
Теперь, собственно о том, что делает "Блевантон". Во-первых, я немного дополнил алгоритм построения облака - теперь оно строиться по всем правилам, а точнее - слова в облаке выстаиваются по алфавиту.
Загружаем произволный текст в программу:
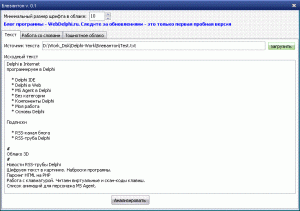
В качестве проверочного текста я взял одну из страниц своего блога.
Теперь нажимаем на кнопку"Анализировать" и " Блевантон " начинает свою работу.
Первое, что делает программа - удаляет из текста повторяющиеся пробелы, пустые строки и все стоп-символы . Стоп-символы, кстати, находятся в текстовом файле, так что, при желании, можете этот файл редактировать на свое усмотрение.
Далее, текст разбивается на отдельные слова и над списком слов проводятся те же операции, что и при построении облака тегов, т.е. - подсчитывается вхождение каждого слова в текст, список слов сортируется по возрастанию упоминаний.
Ну, а дальше все элементарно - вытаскиваем из облака последний элемент и смотрим сколько раз слово из элемента облака упоминается в тексте и, исходя из определения, высчитываем тошноту.
Третий этап работы - сортируем облако по алфавиту и выстраиваем его:
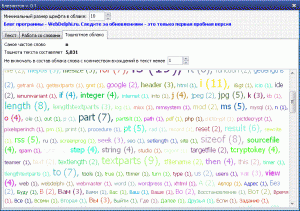
То облако, которое строится в программе как-то не вяжется с определением "облако тегов", поэтому и название у него соответствующее "Тошнотное облако". И несет оно в себе несколько иной смысл - с помощью него вы можете без проблем невооруженным глазом увидеть какое слово или даже ряд слов встречается в тексте очень часто и попытаться отредактировать текст. Ведь, согласитесь, практически у каждого из нас встречаются как в письменной, так и в устной речи слова-паразиты, которые так и лезут наружу - вот в облаке-то они и будут Вам отчётливо видны. А чтобы такие слова прямо-таки выпячивались в облаке, я дописал алгоритм построения и добавил возможность отсеивания малозначащих слов, т.е. слов которые встречаются в тексте реже заданного порога.
Для того, чтобы перестроить облако, необходимо задать тот порог повторяемости слова ниже которого слова будут исключаться из построения. Например на следующем рисунке я выкинул из облака все слова, которые встречаются в тексте менее 3 раз:
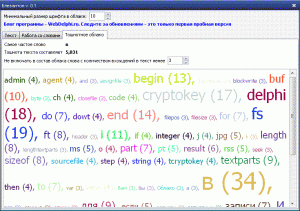
Чувствуете разницу? Облако "сдулось" практически в 4 раза, соответственно и просмотр значительно облегчается.
Таким образом, регулируя "порог чувствительности" у облака Вы можете рассматривать свой текст во всей красе как Вам угодно.
Теперь о том, что "Блевантон" НЕ умеет в отличие от всевозможных он-лайн сервисов по проверке тошноты. Единственное, что пока не удается осуществить - это поиск и группировка всех словоформ. Например, сейчас слова который и которые - разные, хотя по идее они должны выделяться в отдельную группу. Но, я думаю, это мелочь малозначащая, тем более для первой версии программы. Пока можете скачивать "Блевантон", проверять его работу, анализировать свои тексты и т.д. Буду очень благодарен за ценный советы по улучшению программы. Может кто-то захочет, чтобы программа выполняла и другие функции по анализу текста - предлагайте, постараюсь реализовать.