
.NET 4 содержит богатый набор средств, упрощающих распараллеливание кода. Если мы начинаем обрабатывать некоторый набор данных одновременно в нескольких потоках, то автоматически поднимается вопрос о синхронизации выполнения этих потоков, в частности о том, где хранить результаты обработки. Существует достаточно способов координировать потоки между собой, и всегда можно реализовать любой из них. Но создатели Parallel Extensions уже позаботились об этом, и в состав .NET 4 был включен ряд "потокобезопасных" структур данных. Реализован набор наиболее популярных коллекций, с которыми я и предлагаю ознакомиться.
1. Очередь: ConcurrentQueue<T>
Этот класс представляет собой классическую очередь, работающую по принципу FIFO, с той лишь разницей, что к ней возможен безопасный доступ со стороны нескольких потоков. Новой "параллельной" природе соответствует и набор методов - получение элемента производится посредством вызова Try*:
queue.Enqueue(10);
int t;
Console.WriteLine(queue.TryPeek(out t));
Console.WriteLine(queue.TryDequeue(out t));
Как можно догадаться по названию, отличаются эти вызовы тем, что TryPeek() оставляет элемент в очереди, а TryDequeue() извлекает его. Оба метода возвращают false если элемент получить не удалось, иначе - true. Добавление элемента производится с помощью метода Enqueue() - здесь ничего особенного нет. С помощью свойств Count и IsEmpty можно узнать количество элементов в очереди, и есть ли они вообще.
2. Стек: ConcurrentStack<T>
Здесь дело обстоит точно так же, как и с очередью - имеем дело с обычным стеком, но наделенным возможностью конкурентного доступа. Кроме принципа LIFO, использующегося в стеке, отличительной чертой его является возможность добавления и извлечения нескольких элементов:
stack.Push(10);
stack.PushRange(new int[] { 1, 2, 3, 4, 5 });
int t;
if (stack.TryPop(out t))
{
Console.WriteLine("Pop: " + t);
}
if (stack.TryPeek(out t))
{
Console.WriteLine("Peek: " + t);
}
int[] ts = new int[5];
int count;
if ((count = stack.TryPopRange(ts, 0, 3)) > 0)
{
Console.WriteLine("PopRange");
for (int i = 0; i < count; i++)
{
Console.WriteLine(ts[i]);
}
}
Вот результат работы этого участка кода:
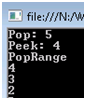
Методы TryPeek() и TryPop() возвращают bool значения, а TryPopRange() - количество извлеченных элементов. Можно положить в стек сразу несколько элементов посредством вызова PushRange().
3. Коллекция: ConcurrentBag<T>
Представляет собой неупорядоченное хранилище данных, и этим похоже на множество, хотя отличается от него тем, что может хранить дублирующиеся элементы. В отличие от предыдущих структур не гарантируется какой-либо порядок извлечения элементов. Это, наверное, самая простая коллекция из всего набора:
bag.Add(70);
int t;
bag.TryPeek(out t);
Console.WriteLine(t);
bag.Add(110);
Console.WriteLine();
for (int i = 0; i < 3; i++)
{
bag.TryTake(out t);
Console.WriteLine(t);
}
Этот кусочек кода даст следующий вывод на консоль:
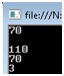
Глядя на результат, может сложиться ощущение, что коллекция следует принципу LIFO. Ещё раз подчеркну, что это не гарантируется. Никакого определённого порядка. Обратите внимание на конструктор - есть возможность задать начальный набор элементов. То же самое можно сделать при создании очереди и стека.
4. Словарь: ConcurrentDictionary<TKey, TValue>
И здесь просматриваются черты "старого знакомого" - да, это реализация привычного Dictionary<TKey, TValue>, но с возможностью конкурентного доступа. Разумеется, наделение такими способностями не прошло даром - немного изменился привычный набор методов. Давайте его рассмотрим, для этого создадим коллекцию:
dict = new ConcurrentDictionary<string, string>();
dict.TryAdd("name", "OFC340");
dict.TryAdd("age", "25");dict.TryAdd("age", "25");
Работа по добавлению/изменению/удалению элементов производится с помощью методов Try*, которые вернут true, если действие выполнено прошла успешно, иначе false. В данном случае добавление значения с ключом "age" будет в первый раз успешно, а во второй - нет, при этом никаких исключений сгенерировано не будет. Например, попытка получить значение по ключу, которого нет в словаре:
Console.WriteLine(dict.TryGetValue("nokey", out t));
приведет лишь к выводу на консоль строки "False". Удаление элемента будет выглядеть так:
С помощью свойств Values и Keys можно получить актуальные на момент вызова коллекции ключей и значений словаря. На этом вся специфика "потокобезопасной" версии заканчивается.
Как видите, в реализации рассмотренных нами коллекций нет никакой "мега"-функциональности, только необходимые вещи. Мне нравятся такие решения - когда строятся базовые структуры, нагромождение лишних возможностей лишь мешает. В случае необходимости всегда можно дополнить их нужным поведением.
Кроме указанных, в текущей версии .NET beta 1 есть двусвязный список ConcurrentLinkedList<T>. Однако, я не буду на нём останавливаться, поскольку в MSDN нас заботливо предупредили: "ConcurrentLinkedList(of T) is planned to be removed prior to the final release of Visual Studio 2010. Please do not use this class", т.е. этот список будет исключен и в финальной версии .NET 4.0 его не будет. Поэтому тратить время на его рассмотрение не стоит (хотя, смотреть там особо нечего - "конкурентная" версия известного LinkedList<T>).
Представленные выше 4 структуры данных - самые простые, и на них я завершу первую часть обзора. Во второй части речь пойдёт о более интересном хранилище - BlockingCollection<T>.