
Введение
В качестве утилиты для эталонного тестирования дисковой подсистемы используется разработанная Майкрософт программа SQLIO.
В методике используется ограниченный набор параметров вызова SQLIO. Давайте рассмотрим назначение параметров на примере:
sqlio -kR -s300 -b64 -f1 -i2000000 -o1 -t1 -R1 -LP -a0xf -BN
Параметр -k определяет, будет ли производиться чтение (R) или запись (W). Параметр -s задаёт продолжительность теста, указываемую в секундах. Параметр -b задаёт размер блока ввода-вывода в килобайтах. Параметр -f определяет число блоков в строке. Параметр -i определяет число строк. С помощью параметров -b, -f и -i

Рис.1.
Параметр -o указывает количество отправляемых в одном потоке запросов ввода-вывода, т.е. глубину очереди. Практика показывает, что программа SQLIO при глубине очереди 64 и выше может вести себя нестабильно, поэтому число 64 не превышалось. Параметр -t задаёт число используемых в тесте потоков, максимальное значение 256. В настоящей методике этот параметр не превышает числа ядер процессоров. Параметр -R задаёт номера LUN сырых (RAW) разделов дисков. Параметр -L задаёт таймер теста, в методике используется таймер процессоров. Параметр -a задаёт маску используемых в тесте процессоров. Параметр -B используется для отключения аппаратного и программного кэширования (кэш дисков и дисковых контроллеров будет отключён, если ими такая возможность поддерживается).
В отчёте по каждому из единичных тестов, выполненных утилитой SQLIO, кроме численных параметров рабочей нагрузки данного теста указаны и вычисленные показатели производительности. Кроме метрик задержки, можно увидеть две величины: IOs/sec и MBs/sec. Первая является ни чем иным, как IOPS (Input-Output Operations Per Second), и показывает количество операций ввода-вывода в секунду, которые было обработано тестируемой дисковой подсистемой. Эта величина лучше всего характеризует производительность обслуживания коротких запросов, характерных для OLTP-нагрузки (8KB). Если приложение, для которого тестируется дисковая подсистема, использует в своей работе преимущественно такую нагрузку, может оказаться, что сравнения полученных в разных конфигурациях результатов стоит делать по этой метрике. Один диск на сегодняшний день может обслуживать от 50 IOs/sec для SATA и до 200 IOs/sec для FC дисков.
Второй метрикой является производительность передачи данных, так называемый Traffic Throughput. Это основная метрика настоящей методики, поскольку большинству приложений баз данных характерны укрупнённые запросы (например, упреждающее чтение способно использовать запросы ввода-вывода в 64 и 128 КБ).
Этап №0. Подготовка
Инсталляцию дисковой подсистемы нужно выполнять таким образом, чтобы было обеспечено сбалансированное и равномерное распределение дисков между контроллерами и по физическим шинам. Важно, чтобы на обслуживающей дисковый контроллер шине не было других, более медленных устройств, иначе, это может привести к снижению скорости обмена по шине для выравнивания с более медленным устройством. Дисковые контроллеры должны регистрироваться системой после встроенных контроллеров, которые обслуживают диск или диски операционной системы (иметь большие номера). В наших тестах, которые описаны в настоящей статье, это контроллер с номером 0, который обслуживает диск, пронумерованный операционной системой, как нулевой. После любых изменений конфигурации дисковой подсистемы нужно выполнять сохранение конфигурации в фал, который потом попадёт в отчёты. Важен, также, учет особенностей нумерации дисков в ОС.
Во время конфигурации виртуальных дисков/массивов, нужно отключать всякого рода кэширование (сквозная запись, отсутствие упреждающего чтения) и включать оптимизацию для баз данных, если таковая предусмотрена. Все созданные виртуальные диски должны быть зарегистрированы в mmc оснастке управления дисками.
Этап №1. Калибровка дисков
Задача: На этом этапе мы должны убедиться, что используемые диски работоспособны, определить разброс скоростей чтения и записи по дискам, чтобы потом учитывать возможности каждого диска при распределении дисков в массивах.
Возникает резонный вопрос, почему бы не воспользоваться стандартными в таких случаях стресс - тестами, которые, как правило, предоставляются вендором. Объяснение простое. Чаще всего мне доводилось работать с серверами удалённо, а в таких условиях не всегда удаётся добиться оперативной реакции обслуживающего аппаратную часть персонала. В таких случаях проще сделать быстрый тест на "вшивость". К тому же, не всегда тесты охватывают сразу все уровни системы, они могут ограничится только дисками или тестировать контроллер вместе с дисками. Существуют также специализированные тесты, которые позволяют тестировать систему в целом и определять её пригодность к использованию для того - либо иного приложения. У Майкрософт, к слову, есть подобный стресс - тест, который позволяет протестировать дисковую систему и сервер. Называется эта утилита: SQLIOSim.
Поскольку диски с повреждениями или существенными отклонениями от средней производительности, скорее всего, ведут себя одинаково плохо под разными типами рабочей нагрузки, а также потому, что дальнейшее тестирование также может выявить проблемные диски, мы ограничимся одним, грубым тестом. Для проведения этого калибровочного теста необходимы следующие подготовительные действия:
- С помощью поставляемых с дисковым контроллером специализированных утилит, конфигурируем все диски полки как 14 массивов RAID0, каждый из которых должен состоять из одного диска, размер каждого массива выбирается равным всему доступному размеру диска, размер блока низкоуровневой разметки (размер сегмента) выбираем равным 64Кб, политики кэширования должны исключать кэширование чтения и записи. В некоторых контроллерах дисковых массивов выбор размера сегмента может быть ограничен несколькими предопределёнными значениями. Можно встретить рекомендованные для типовых конфигураций значения, например, для баз данных предлагают установить размер блока в 128Кб, а для хранения видеофильмов задать 256Кб. В этих случаях резонно выбрать рекомендованные вендором значения.
- С помощью оснастки управления дисками, входящей в состав mmc-консоли управления компьютером, и системной утилиты DISKPART необходимо создать для каждого физического диска полки RAW-раздел (без форматирования NTFS) величиной на весь диск, и без присвоения буквы диска (буквы присваивать можно, но это не обязательно, к тому же, букв в алфавите может оказаться меньше числа дисков). Большие диски (более двух Терабайт) может потребоваться предварительно перевести в состояние Online, и конвертировать в GPT (GUID Partition Table). Для выравнивания начального смещения за счёт MBR используйте следующие команды DISKPART:
SELECT DISK=1
CREATE PARTITION PRIMARY ALIGN=128
В этом примере выбран диск 1 и смещение установлено в 128Кб. Выбор смещения зависит от размера сегмента.
- Установить программу SQLIO. Везде по тексту настоящей статьи местоположение программы sqlio.exe выбрано следующее: C:\SQLIO\ sqlio.exe
- Подготовьте командный файл, который будет запускать программу sqlio.exe в разных режимах для каждого диска и сохранять результаты в файлы. Пример командного файла можно найти в Приложении 1.
- Запустите командный файл на исполнении, а потом сведите собранные в файлы результаты в общую таблицу, для дальнейшего сравнения и анализа.
Пример аппаратной конфигурации дисков представлен в Таблице 1.
Таблица 1. Конфигурация дисковых массивов для калибровки дисков.
|
Номер диска |
Тип массива |
Размер |
Имя устройства |
Политика чтения |
Политика записи |
Политика кэша |
Размер блока полосы |
|
1:0 |
RAID-0 |
136.62GB |
Windows Disk 0 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
1:1 |
RAID-0 |
136.62GB |
Windows Disk 1 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
1:5 |
RAID-0 |
136.62GB |
Windows Disk 2 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
0:9 |
RAID-0 |
136.62GB |
Windows Disk 3 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
0:10 |
RAID-0 |
136.62GB |
Windows Disk 4 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
0:11 |
RAID-0 |
136.62GB |
Windows Disk 5 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
0:12 |
RAID-0 |
136.62GB |
Windows Disk 6 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
0:13 |
RAID-0 |
136.62GB |
Windows Disk 7 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
0:14 |
RAID-0 |
136.62GB |
Windows Disk 8 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
0:15 |
RAID-0 |
136.62GB |
Windows Disk 9 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
1:2 |
RAID-0 |
136.62GB |
Windows Disk 10 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
1:3 |
RAID-0 |
136.62GB |
Windows Disk 11 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
1:4 |
RAID-0 |
136.62GB |
Windows Disk 12 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
|
1:8 |
RAID-0 |
136.62GB |
Windows Disk 13 |
без упреждения |
прямая запись |
Direct I/O |
64 KB |
На Рисунке 2 показано, как должны выглядеть 14 дисков, подготовленные к тестированию.
Рис.2.
Ниже представлен сокращённый пример командного файла для запуска калибровочного теста. В этом файле каждый вызов программы sqlio.exe имеет одинаковые аргументы, кроме аргумента R, который изменяется от 1 до 14. Каждый диск тестируется на чтение и, после 30 секундной паузы, на запись (аргумент k). Время тестирования каждого диска 300 секунд (аргумент s), размер блока 64Кб (аргумент b), Число блоков в строке равно единице (аргумент f), число строк равно 2000000 (аргумент i), число очередей тоже равно единице (аргумент o), число потоков равно единице (аргумент t). Суммарный размер файла рабочей нагрузки на каждом диске составляет 128Гб, что почти совпадает с размером диска.
sqlio -kR -s300 -b64 -f1 -i2000000 -o1 -t1 -R1 -LP -a0xf -BN > R01-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s300 -b64 -f1 -i2000000 -o1 -t1 -R1 -LP -a0xf -BN > W01-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kR -s300 -b64 -f1 -i2000000 -o1 -t1 -R2 -LP -a0xf -BN > R02-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s300 -b64 -f1 -i2000000 -o1 -t1 -R2 -LP -a0xf -BN > W02-b64-f1-i2000000-o1-t1.log
timeout /T 30
……
sqlio -kR -s300 -b64 -f1 -i2000000 -o1 -t1 -R13 -LP -a0xf -BN > R13-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s300 -b64 -f1 -i2000000 -o1 -t1 -R13 -LP -a0xf -BN > W13-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kR -s300 -b64 -f1 -i2000000 -o1 -t1 -R14 -LP -a0xf -BN > R14-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s300 -b64 -f1 -i2000000 -o1 -t1 -R14 -LP -a0xf -BN > W14-b64-f1-i2000000-o1-t1.log
Ниже представлен пример отчёта о тесте операций записи для первого диска:
sqlio v1.5.SG
calibrating timestamp counter for latency timings... done (MHz measured at 2359)
1 thread reading for 300 secs from file 1:
using 64KB IOs over 64KB stripes with 2000000 IOs per run
enabling multiple I/Os per thread with 1 outstanding
buffering set to not use file nor disk caches (as is SQL Server)
affinity mask is 0xf (15)
initialization done
CUMULATIVE DATA:
throughput metrics:
IOs/sec: 999.67
MBs/sec: 66.91
latency metrics:
Min_Latency(ms): 0
Avg_Latency(ms): 0
Max_Latency(ms): 802
histogram:
ms: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24+
%: 87 13 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
В этом отчёте нас интересует метрика скорости чтения, именно эту метрику мы будем сводить в общий график (MBs/sec: 66.91). Метрика IOs/sec практически линейно зависит от MBs/sec, поскольку в каждом из тестов у нас будет фиксированный размер запроса ввода-вывода. Метрики для задержки запроса ввода-вывода (latency) могут быть интересны вкупе с MBs/sec для сравнения разных дисковых подсистем. Нас такое сравнение не интересует, поэтому метрики MBs/sec вполне достаточно.
Автоматизировать извлечение из файлов с результатами тестов необходимых для дальнейших оценок значений показателей производительности можно, например, с помощью PowerShell. В примере ниже показана команда, которая сохраняет в CSV-файле имена файлов и соответствующее им значение MBs/sec:
(Select-String -Pattern MBs/sec: -Path *.log / format-table `
{$_.Filename -replace ".log", ""}, `
{($_.Line).replace(".", ",") -replace "MBs/sec: ", ";"} `
-HideTableHeaders) / Out-File SQLIO.csv -Encoding ASCII -Append
Если результаты сильно выбиваются из общей массы, желательно для такого диска повторить измерения, существенно (например, в два раза) увеличив время теста (аргумент s). На полученные результаты может сильно влиять посторонняя активность на сервере. Старайтесь не подключаться к консоли сервера или посещать его в терминальном режиме, пока не будет закончен очередной пакет тестов. Кроме того, постарайтесь отключить на время тестирования любую другую постороннюю активность на сервере.
На Рисунке 3 показан результат калибровочного тестировании 13 дисков.
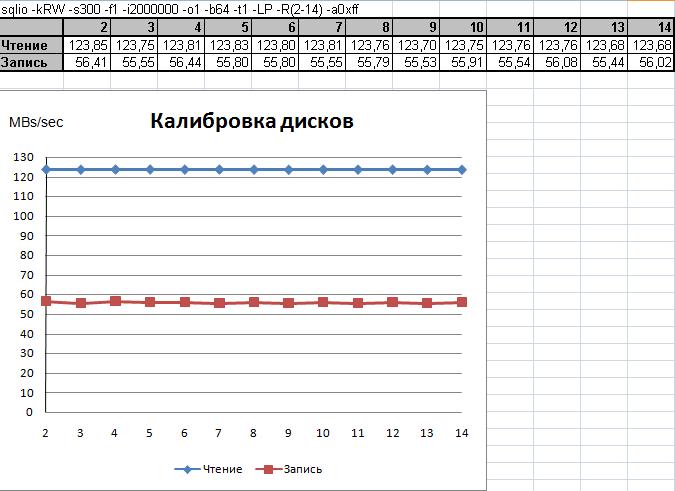
Рис. 3.
Наиболее важной задачей нагрузочного тестирования является выявление дисков, характеристики которых существенно отличаются от остальных. На Рисунке 2 диски практически идентичны, как по записи, так и по чтению. Однако, при тестировании большого числа дисков вероятность столкнуться с "подозрительными" дисками много выше. Например, такой пример показан на Рисунке 4. Обратите внимание на четырнадцатый диск.
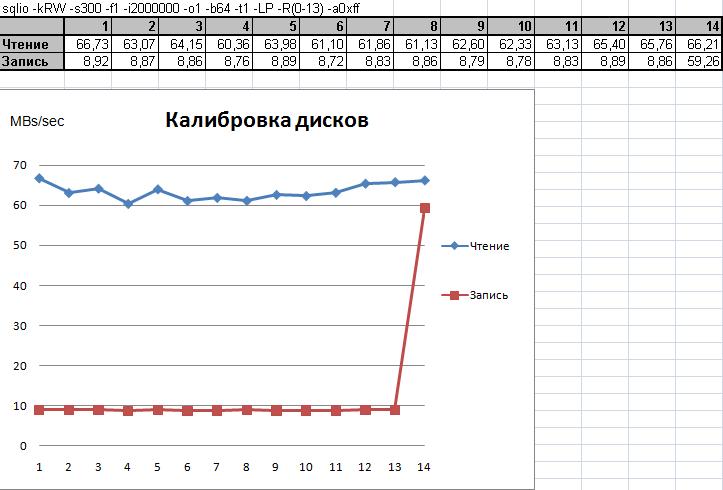
Рис. 4.
Совсем не обязательно, что в плохих или, наоборот, невероятно хороших результатах повинен сам диск. Причиной может стать неисправность дискового контроллера, терминатора шины или электрических цепей шины дисковой "полки".
Для калибровки можно выбирать и другие параметры рабочей нагрузки. Главное, чтобы результаты были показательны и были сопоставимы с паспортными характеристиками дисков.
Если позволяет время, можно проверить не только последовательные чтение/запись, но и случайный выбор блоков для ввода-вывода.
Особо хочется остановиться на вопросах документирования результатов измерений. Обратите внимание на заголовок таблиц каждого из представленных ранее двух результатов. Это строки:
sqlio -kRW -s300 -f1 -i2000000 -o1 -b64 -t1 -LP -R(2-14) -a0xff
sqlio -kRW -s300 -f1 -i2000000 -o1 -b64 -t1 -LP -R(0-13) -a0xff
Мне видится наиболее удобным и практичным именно такой вид описания тестовой конфигурации. Суть состоит в том, чтобы просто скопировать из командного файла строку запуска программы SQLIO и внести изменение в написание изменяемых параметров. В данном случае для параметра -R в скобках был задан диапазон изменения порядковых номеров дисков. В первом случае это диски со второго по четырнадцатый, а во втором случае - это диски с нулевого по тринадцатый. Подобные описатели конфигурации будут встречаться далее в этой статье для демонстрации результатов измерений.
Этап №2. Масштабирование дисков
Следующим этапом идёт выявление предельных возможностей дисковой подсистемы и калибровка её, как цельного компонента.
Наша задача понять, сколько дисков (шпинделей) способны захватить практически всю полосу пропускания. Это поможет при выборе числа дисков в массиве. Кроме того, этот тест позволяет убедиться, что дисковые контроллеры (а в наших тестах их два) и пассивное оборудование работает исправно.
Производительность отдельных компонент дисковой подсистемы в данной методике не исследуется, хотя понятно, что абстрагироваться от этого полностью невозможно. В предлагаемой методике мы смотрим на дисковую подсистему, условно, как на "чёрный ящик". Ограничения, а также разного рода ошибки, могут быть совершенно в разных местах. Чтобы начать разговор об этом с администраторами дисковой подсистемы, нужно иметь аргументы. Масштабирование позволяет получить на руки факты именно из этой области. Кроме того, поскольку мы хотим получить в итоге некий эталон производительности, подобные измерения бывают весьма полезны.
В качестве подготовки к этому этапу, нужно убедиться, что сервер и полка подключены друг к другу оптимальным способом и задействованы все особенности подключений, позволяющие повысить производительность передачи данных между дисками и сервером. Достигается это, например, увеличением числа используемых "петель" подключений, выбором оптимальных способов балансирования нагрузки через множество путей ввода-вывода, выбором более производительных интерфейсов, режимом работы и способом привязки дисковых контроллеров и т.д. и т.п. Для получения полной картины возможностей оптимизации тестируемой системы, обратитесь к технической документации вендора.
Суть теста очень проста. Вначале файл рабочей нагрузки помещается только на один диск, точно так же, как это делалось в предыдущем, калибровочном тесте. Потом тестируется конфигурация, когда файл рабочей нагрузки размещён на двух дисках. В калибровочном тесте файл всегда был только на одном диске, менялись только сами диски. В этом же тесте диски не меняются, а в каждом тесте добавляется ещё один диск и на нём размещается ещё один файл. Таким образом, число тестируемых диско в представленном ниже на Рисунке 5 примере результата изменяется от одного до тринадцати.
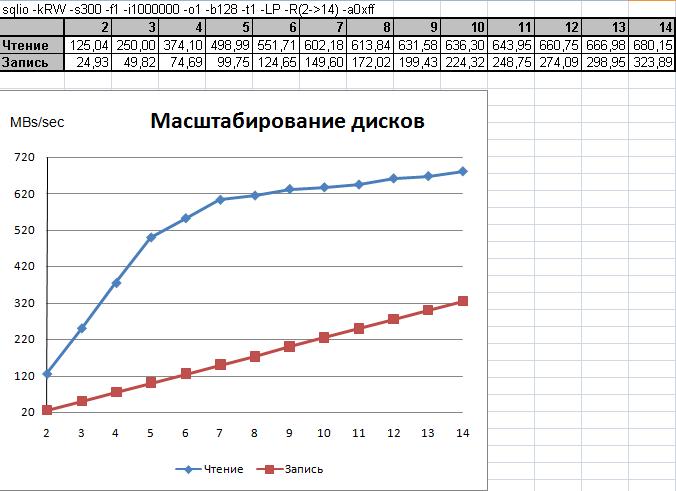
Рис.5.
Для документирования подобного приращения числа дисков я использую сочетание символов "à". Т.о. для обозначения приращения дисков, которое начинается с диска под номером 2 в нумерации операционной системы и заканчивается обоймой из тринадцати дисков по диск номер 14 включительно, можно использовать следующую запись: -R(2->14).
В командном файле это выглядит примерно так:
sqlio -kR -s180 -b64 -f1 -i2000000 -o1 -t1 -R2 -LP -a0xf -BN > R2-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s180 -b64 -f1 -i2000000 -o1 -t1 -R2 -LP -a0xf -BN > W2-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kR -s180 -b64 -f1 -i2000000 -o1 -t1 -R2,3 -LP -a0xf -BN > R23-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s180 -b64 -f1 -i2000000 -o1 -t1 -R2,3 -LP -a0xf -BN > W23-b64-f1-i2000000-o1-t1.log
timeout /T 30
… результаты сокращены…
sqlio -kR -s180 -b64 -f1 -i2000000 -o1 -t1 -R2,3,4,5,6,7,8,9,10,11,12,13 -LP -a0xf -BN > R2345678910111213-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s180 -b64 -f1 -i2000000 -o1 -t1 -R2,3,4,5,6,7,8,9,10,11,12,13 -LP -a0xf -BN > W2345678910111213-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kR -s180 -b64 -f1 -i2000000 -o1 -t1 -R2,3,4,5,6,7,8,9,10,11,12,13,14 -LP -a0xf -BN > R234567891011121314-b64-f1-i2000000-o1-t1.log
timeout /T 30
sqlio -kW -s180 -b64 -f1 -i2000000 -o1 -t1 -R2,3,4,5,6,7,8,9,10,11,12,13,14 -LP -a0xf -BN > W234567891011121314-b64-f1-i2000000-o1-t1.log
Получив информацию о том, какова реальная пропускная способность вашей дисковой подсистемы, вы можете спланировать дальнейшие тестовые конфигурации. Выбор тестируемых конфигураций может быть обусловлен вашими бизнес - требованиями к доступности и готовности серверов, а также отводимыми на тестирование сроками (полный цикл тестирования согласно данной методике может занимать порядка 7 суток круглосуточной работы тестового сервера). Зная, какое количество шпинделей потенциально может "запрудить" шину или контроллер, вы можете выбрать, сколько дисков оптимально собирать в один массив. Кроме того, в целях оптимизации времени тестов, данная методика предполагает допущение, что сервер баз данных, как и утилита SQLIO, балансирует нагрузку между дисками лучше, чем контроллер дискового массива. Как вы помните, база данных может состоять из нескольких файлов, и SQL Server будет резервировать в этих файлах пространство под новые страницы пропорционально размеру файлов. Учитывая эту особенность, мы ограничим число создаваемых массивов только некоторыми избранными конфигурациями, которые в лучшей мере используют преимущества балансировки ввода-вывода с помощью SQL Server. Т.е. это будут те конфигурации, которые не противоречат здравому смыслу и предлагают максимальное количество файлов. Ещё одним допущением для данной методики является то, что в каждой из тестовых конфигураций число шпинделей остаётся неизменным. Это нужно для того, чтобы сравнивать производительность разных массивов при равной стоимости оборудования.
Лучше всего рассмотреть вариант подобной тестовой схемы на примере, с графическими изображениями сайзинга дисков в массиве. Поскольку у нас уже собрана самая простая, и, во многих случаях, самая эффективная конфигурация дисков в массивы, начнём с неё. Похожая конфигурация показана на рисунке 6, и условно обозначается noRAID.
Рис.6.
Современные дисковые контроллеры часто не предусматривают возможности конфигурирования отдельных дисков, однако, оставляют возможность создания RAID0 из одного диска.
Следующие конфигурации, показанные на рисунках 7 и 8, представляют RAID1 и RAID0.
Рис.7.
Рис.8.
Конфигурации массивов RAID5 и RAID10 тоже внешне очень похожи, у них будет одинаковое количество логических дисков (LUN).
Рис.9.
Рис.10.
Каждая из показанных на рисунках конфигурация используется для прогона тестов, которые описаны на этапе 4.
Этап №3. Выбор размера сегмента
Следующий этап не обязателен и приведен тут, скорее, для полноты картины. Дело в том, что при выборе размера сегмента (блока, который используется дисковым контроллером для монтирования дисковых массивов) лучше всего полагаться на рекомендации производителя дисков и дисковой подсистемы, или воспользоваться рекомендациями Майкрософт, изложенными в документации, учебных материалах, статьях базы знаний или белых страницах.
В этой статье мы будем полагаться на то, что бизнес - требования наших приложений указывают на необходимость обеспечения высокой производительности запросов упреждающего чтения. Как известно, упреждающее чтение характерно тем, что размер запроса ввода - вывода чаще всего равняется 64 Кб. SQL Server пытается считывать данные не страницами, а экстентами, разумеется, если размер запроса соответствующий и фрагментация данных позволяет это сделать. Мы допускаем, что фрагментацию удаётся поддерживать в приемлемых рамках, а оптимизация запросов ввода-вывода, размер которых близок к размеру страницы 8 Кб, не представляется необходимой, поскольку такие запросы будут обслуживаться практически одинаково в разных конфигурациях в силу своих малых размеров. Также, мы будем опираться на очень распространённое бизнес-правило, что время резервного копирования и восстановления базы данных из резервной копии должны быть минимальными. В своих измерениях Вы можете полагаться на иные требования и правила. Чтобы помочь Вам сориентироваться в выборе размеров нагрузки, тут будет уместно привести Таблицу 2, в которой показано соотношение разных операций и размеров запросов.
Таблица 2. Характеристики для основных типов нагрузки ввода - вывода SQLServer
|
Характер нагрузки |
Доступ: случайный / последовательный |
Преобладает: чтение / запись |
Размер запроса ввода-вывода |
|
Журнал транзакций OLTPсистемы |
последовательный |
запись |
512 Б - 64 КБ |
|
Файлы данныхOLTPсистемы |
случайный |
чтение - запись |
8 КБ |
|
Массовая вставка |
последовательный |
запись |
от 8 КБ до 256 КБ |
|
Упреждающее чтение, просмотр индекса |
последовательный |
чтение |
от 8 КБ до 256 КБ |
|
Резервное копирование |
последовательный |
чтение / запись |
1 МБ |
|
Отложенная запись |
последовательный |
запись |
от 128 КБ до 2 МБ |
|
Восстановление из копии |
последовательный |
чтение / запись |
64 КБ |
|
Контрольная точка |
последовательный |
запись |
от 8 КБ до 128 КБ |
|
CREATE DATABASE |
последовательный |
запись |
512 КБ |
|
CHECKDB |
последовательный |
чтение |
8 КБ - 64 КБ |
|
DBREINDEX |
последовательный |
чтение / запись |
чтение: от 8 КБ до 256 КБ запись: от 8 КБ до 128 КБ |
|
SHOWCONTIG |
последовательный |
чтение |
8 KБ - 64 КБ |
Как правило, выбор размера сегмента не является сложной задачей и, зачастую, предсказуем. Например, ниже, на Рисунке 11 показана весьма распространённая зависимость производительности одного диска от размера сегмента.
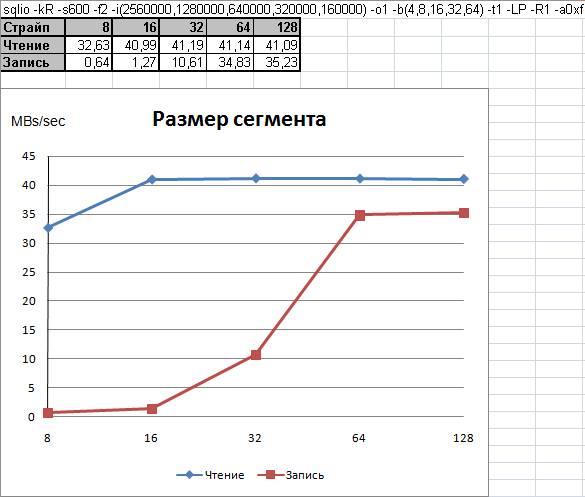
Рис.11.
Многие специалисты рекомендуют устанавливать размер блока для форматирования NTFS раздела операционной системы Windows равным 64 Кб и делать такого же размера размер сегмента при монтировании дискового массива. Глядя на представленный Рисунком 11 график, становится понятно, откуда взялась эта рекомендация.
Этап №4. Сравнение производительности разных типов дисковых массивов
Заключительный этап позволяет выяснить возможности разных типов дисковых массивов, что может стать отличным подспорьем при определении наиболее оптимальной конфигурации дисков, а также позволит предсказать, какие характеристики будут у разных конфигураций дисковой подсистемы. По результатам таких тестов можно будет осознанно разместить файлы сервера баз данных на дисковой подсистеме. Такую операцию на IT-жаргоне принято называть сайзингом.
Первым делом, нужно определиться, какие типы и конфигурации дисковых массивов будут участвовать в тестировании. На этот выбор влияют возможности задействованных дисковых контроллеров, а также, число доступных физических дисков. В нашем примере мы будем тестировать по три массива в каждой серии тестов, каждый раз это будет другой уровень RAID.
Каждый уровень RAID будет подвержен пяти тестовым сериям измерения скорости чтения и записи, для разных размеров блока. Размер блока (который задаётся параметром -b) будет принимать следующий набор значений: 1024, 512, 256, 64, 8. Как вы, наверное, заметили, размеры блока соответствуют размерам основных типов запросов ввода-вывода. Выбор размеров блока для тестирования важен, поскольку не стоит включать в тест те размеры запросов ввода - вывода, которые не важны, или не характерны для ваших приложений. Например, если в вашей промышленной среде существуют достаточно продолжительные окна для проведения технологических планов обслуживания баз данных, тогда можно исключить из теста размер блока в 128Кб. Если время создания базы данных тоже не критично (например, если вы используете RAW-партиции), можно убрать тест с размером блока 512Кб.
Кроме изменения размера блока (под блоком будем понимать размер запроса ввода-вывода), данная методика предполагает изменение ещё нескольких, критически важных характеристик рабочей нагрузки. Нам нужно оценить производительность не только для одного запроса, но и в условиях относительно глубоких очередей запросов ввода-вывода, а также распараллеливания этих запросов. Глубина очереди будет увеличиваться до 64. Шаг приращения величины очереди тоже стоит выбирать таким, какой характерен для ваших приложений или, как это будет показано в нашем примере, это могут быть отдельные, характерные для ваших задач значения. Мы будем использовать следующие параметры очереди: о1, о2, о4, о8, о16, о32, о64.
Число потоков у нас будет изменяться от одного до четырёх, ровно столько на тестовом сервере имеется ядер процессора. Синхронно с числом потоков будет изменяться страйп-фактор. Здесь, под числом страйпов (страйп-фактор) понимается число блоков в строке файла нагрузки. Значение переменной основного цикла программы (число страйпов в файле нагрузки) тоже будет меняться, оно вычисляется каждый раз таким образом, чтобы при текущем размере блока и числе блоков в страйпе, размер файла нагрузки был близок к ёмкости диска. Поскольку число вычислений значений параметра i (основной цикл) достаточно велико, лучше заранее подготовить небольшие таблички, охватывающую все выбранные для тестирования варианты параметров и конфигурации. Например, на рисунке 12 представлена подобная таблица.
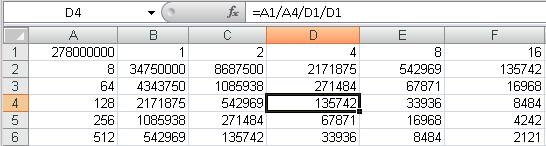
Рис.12.
Здесь, в ячейке A1 указан размер раздела диска (в данном случае у всех дисков он одинаков). Количество строк файла нагрузки, помещаемого на каждый из задействованных дисков, вычисляется делением размера раздела в Кб на размер блока (b), потом на число потоков (t) блоков в страйпе (f).
Настоящая методика использует несколько эмпирических допущений, которые существенно уменьшают объём выполняемых тестов. Рисунок 12 как раз и демонстрирует одно из таких допущений. Т.е. мы тестируем не все возможные варианты сочетаний параметров запуска SQLIO, а только те, которые перечислены в таблице. Т.е. Значения для параметров t и f могут быть 1,2,4,8,16. Поскольку максимальное значение для параметра t рекомендуется избирать не выше числа ядер процессоров (а в пример на рисунке 12 их число было 16). Значение f не должно превышать значение t, диапазон изменения этих параметров будет именно такой, как вы видите на рисунке. В колонке A, начиная со строки 2, заданы размеры запросов ввода вывода, которые характерны для приложения. Эти значения используются для параметра b. В таблице не хватает только одного из определяющих конфигурацию каждого теста параметра, это глубина очереди, задающаяся параметром o. Как и в нашем случае, в примере на рисунке 12 использовались следующие параметры очереди: о1, о2, о4, о8, о16, о32, о64.
Документирование конфигурации проще показать и подробно разобрать на следующем примере:
f(1,2,4) -i(1950,975,487) -o(1-64) -b1024 -t(1,2,4) -LP -R2,3,4 -a0xf
Здесь, размер блока был установлен в 1024Кб. Число блоков в страйпе файла нагрузки изменялось синхронно с числом потоков, т.е. значения были равны, и составляли: 1, 2 и 4. В зависимости от последнего числа изменяется число страйпов файла рабочей нагрузки. В этом тесте для мегабайтного размера блока значения такие: i1950, i975, i487. Глубина очереди изменялась так, как я показывал ранее, от единицы до 64.
В Таблице 3 показаны результаты теста, полученные для разных значений изменяемых параметров.
Таблица 3. RAID1:
|
Чтение |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
373,23 |
371,05 |
345,67 |
|
|
o2 |
373,49 |
326,56 |
331,87 |
|
|
o4 |
373,45 |
325,20 |
330,36 |
|
|
o8 |
373,01 |
331,09 |
318,53 |
|
|
o16 |
371,91 |
321,52 |
281,54 |
|
|
o32 |
368,80 |
290,96 |
264,18 |
|
|
o64 |
351,11 |
276,80 |
262,61 |
|
|
2585,00 |
2243,18 |
2134,76 |
6962,94 | |
|
Среднее: |
331,57 | |||
|
Запись |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
185,52 |
307,15 |
290,45 |
|
|
o2 |
307,73 |
259,25 |
257,31 |
|
|
o4 |
336,09 |
328,68 |
255,48 |
|
|
o8 |
337,55 |
254,93 |
241,74 |
|
|
o16 |
335,02 |
245,59 |
209,88 |
|
|
o32 |
322,65 |
219,26 |
214,20 |
|
|
o64 |
287,12 |
215,73 |
211,50 |
|
|
2111,68 |
1830,59 |
1680,56 |
5622,83 | |
|
Среднее: |
267,75 |
В таблицах с четвёртой по седьмую представлены значения для других размеров блока. Поскольку подобные тесты проводятся для всех тестируемых уровней RAID, и каждый такой тест содержит по пять таблиц, тут мы ограничимся демонстрацией результатов только для RAID1.
Таблица 4. RAID1: f(1,2,4) -i(3900,1900,970) -o(1-64) -b512 -t(1,2,4) -LP -R2,3,4 -a0xf
|
Чтение |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
373,15 |
372,56 |
361,55 |
|
|
o2 |
373,13 |
261,15 |
313,54 |
|
|
o4 |
372,56 |
268,08 |
307,82 |
|
|
o8 |
373,04 |
235,48 |
253,12 |
|
|
o16 |
373,07 |
237,75 |
237,83 |
|
|
o32 |
371,31 |
236,25 |
237,08 |
|
|
o64 |
367,76 |
230,83 |
231,77 |
|
|
2604,02 |
1842,10 |
1942,71 |
6388,83 | |
|
Среднее: |
304,23 | |||
|
Запись |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
156,97 |
265,91 |
265,18 |
|
|
o2 |
268,31 |
251,29 |
206,90 |
|
|
o4 |
332,29 |
325,32 |
180,68 |
|
|
o8 |
340,85 |
249,96 |
182,40 |
|
|
o16 |
332,81 |
190,25 |
172,63 |
|
|
o32 |
328,80 |
185,35 |
173,92 |
|
|
o64 |
317,41 |
183,24 |
176,61 |
|
|
2077,44 |
1651,32 |
1358,32 |
5087,08 | |
|
Среднее: |
242,24 |
Таблица 5. RAID1: f(1,2,4) -i(500000,250000,125000) -o(1-64) -b256 -t(1,2,4) -LP -R2,3,4 -a0xf
|
Чтение |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
374,15 |
243,60 |
248,95 |
|
|
o2 |
375,00 |
309,89 |
290,07 |
|
|
o4 |
375,03 |
306,97 |
291,95 |
|
|
o8 |
374,98 |
313,63 |
313,85 |
|
|
o16 |
375,03 |
306,96 |
304,26 |
|
|
o32 |
374,97 |
304,35 |
234,59 |
|
|
o64 |
374,12 |
301,15 |
255,86 |
|
|
2623,28 |
2086,55 |
1939,53 |
6649,36 | |
|
Среднее: |
316,64 | |||
|
Запись |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
121,68 |
172,75 |
167,27 |
|
|
o2 |
191,64 |
311,50 |
261,88 |
|
|
o4 |
313,80 |
328,33 |
157,86 |
|
|
o8 |
331,46 |
332,86 |
145,59 |
|
|
o16 |
336,23 |
326,75 |
160,41 |
|
|
o32 |
334,63 |
193,98 |
159,45 |
|
|
o64 |
330,98 |
186,63 |
160,22 |
|
|
1960,42 |
1852,80 |
1212,68 |
5025,90 | |
|
Среднее: |
239,33 |
Таблица 6. RAID1: f(1,2,4) -i(2000000,1000000,500000) -o(1-64) -b64 -t(1,2,4) -LP -R2,3,4 -a0xf
|
Чтение |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
348,86 |
167,24 |
371,95 |
|
|
o2 |
371,32 |
279,76 |
338,58 |
|
|
o4 |
370,44 |
202,74 |
344,97 |
|
|
o8 |
370,53 |
223,38 |
371,38 |
|
|
o16 |
374,59 |
205,17 |
323,17 |
|
|
o32 |
374,90 |
170,97 |
191,85 |
|
|
o64 |
374,86 |
156,27 |
171,86 |
|
|
2585,50 |
1405,53 |
2113,76 |
6104,79 | |
|
Среднее: |
290,70 | |||
|
Запись |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
107,37 |
135,34 |
147,57 |
|
|
o2 |
141,84 |
154,48 |
169,75 |
|
|
o4 |
165,56 |
170,44 |
174,16 |
|
|
o8 |
187,45 |
192,70 |
173,17 |
|
|
o16 |
193,43 |
193,40 |
179,14 |
|
|
o32 |
193,92 |
193,75 |
176,27 |
|
|
o64 |
194,66 |
193,26 |
176,17 |
|
|
1184,23 |
1233,37 |
1196,23 |
3613,83 | |
|
Среднее: |
172,09 |
Таблица 7. RAID1: f(1,2,4) -i(16000000,8000000,4000000) -o(1-64) -b8 -t(1,2,4) -LP -R2,3,4 -a0xf
|
Чтение |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
123,89 |
101,73 |
87,55 |
|
|
o2 |
169,70 |
116,12 |
91,55 |
|
|
o4 |
184,15 |
118,78 |
87,39 |
|
|
o8 |
211,35 |
129,39 |
81,27 |
|
|
o16 |
216,18 |
111,26 |
91,28 |
|
|
o32 |
185,17 |
121,52 |
94,14 |
|
|
o64 |
172,73 |
123,32 |
94,16 |
|
|
1263,17 |
822,12 |
627,34 |
2712,63 | |
|
Среднее: |
129,17 | |||
|
Запись |
f1-t1 |
f2-t2 |
f4-t4 |
|
|
o1 |
33,37 |
44,20 |
36,90 |
|
|
o2 |
53,05 |
37,09 |
53,80 |
|
|
o4 |
68,42 |
68,16 |
78,35 |
|
|
o8 |
79,19 |
78,15 |
78,50 |
|
|
o16 |
79,48 |
78,59 |
73,41 |
|
|
o32 |
79,35 |
75,58 |
87,38 |
|
|
o64 |
88,29 |
87,56 |
87,42 |
|
|
481,15 |
469,33 |
495,76 |
1446,24 | |
|
Среднее: |
68,87 |
По каждому из пяти режимов тестирования мы считаем среднее значение. Моя практика показывает, что такой простой формулы оказывается вполне достаточно, однако, это не исключает таких конфигураций, когда потребуется более взвешенный выбор статистических методов. Для каждого из тестируемых уровней RAID средние значения сводятся в общую таблицу, по которой уже можно строить график, удобный для сравнения эффективности разных уровней RAID в используемой тестовой среде.
На Рисунке 13 показан график средних значений производительности троек массивов для разных уровней RAID. Разными цветами обозначены размеры блоков. Шкала показывает производительность в Мб/сек.
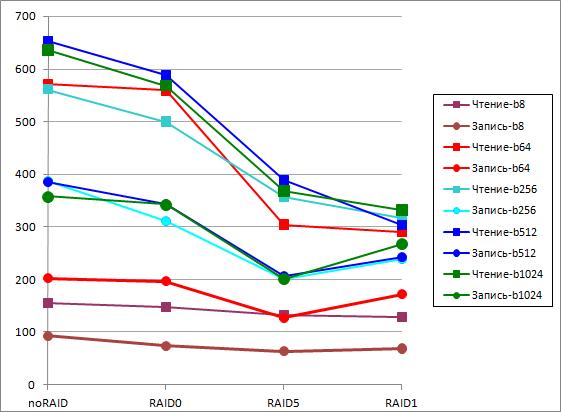
Рис.13.
Этот график отражает эффективность работы разных уровней RAID на нашей аппаратной платформе и для тех режимов рабочей нагрузки, которые характерны приложениям заказчика (это аналитические запросы).
При выборе другого оборудования или в условиях другого характера нагрузки, например, OLTP, график вполне может стать другим. На Рисунке 14 показан график для другой аппаратной платформы, у которой можно было создавать массивы RAID10.
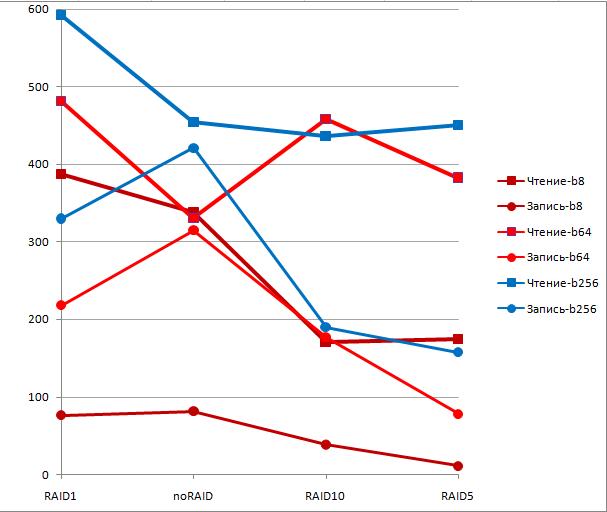
Рис.14.
На рисунках 14 и 15 показаны результаты для варианта прямого подключения дисковой подсистемы. На рисунке 16 показаны результаты тестирования дисковой подсистемы и сервера другого вендора, и в варианте подключения SAN.
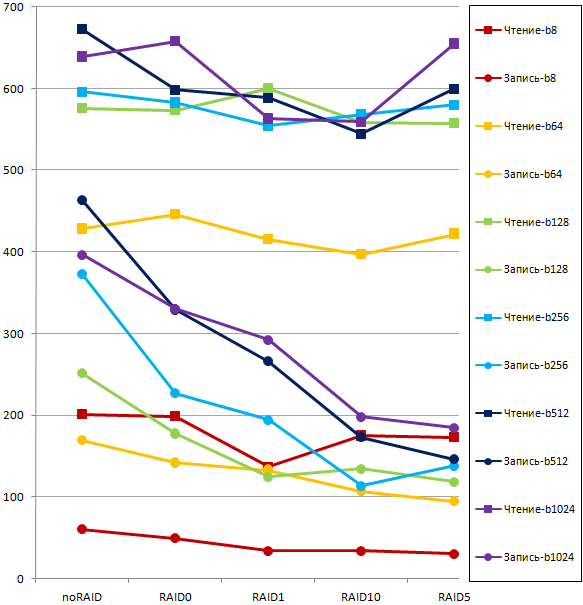
Рис.15.
Анализируя подобные графики, вы без труда поймёте, какие уровни RAID для каких файлов и типов рабочей нагрузки вам следует использовать, чтобы обеспечить требования к производительности, предъявляемые бизнес - правилами для ваших приложений. Получив данные об эффективности различных уровней RAID в ваших условиях, вы можете провести тестирование окончательного варианта промышленной системы, смонтировав все необходимые дисковые массивы. Получив такую оценку, вы будете точно знать, чего следует ожидать от вашей дисковой подсистемы.
Выводы
Сегодня типичные объёмы обслуживаемых СУБД данных настолько велики, что для дисковых подсистем уже недостаточно нескольких дисков, всё чаще, типовое приложение оперирует дисковой полкой в 14 или 15 дисков, а объёмы дисковых массивов достигают Терабайта. В таких условиях задачи сайзинга становятся очень важны, и грамотное распределение файлов вкупе с правильным выбором дисковых массивов позволяют существенно повысить производительность приложений, а также добиться требуемых значений производительности без лишних издержек энергопотребления.
В технических изданиях и в документации вендоров часто можно видеть рекомендации по выбору разных уровней RAID, и сайзингу файлов. Как правило, предлагаются универсальные решения, не позволяющие достичь максимальной эффективности вложений в аппаратные средства. Кроме того, в случае использования бюджетных контроллеров и дисков высока вероятность того, что их реальные характеристики будут сильно отличаться от ожидаемых или максимальных значений, используемых веднорами для рекламы своих продуктов. Предлагаемая методика даст вам возможность более реалистично оценить возможности предоставленной в ваше распоряжение дисковой подсистемы.
Одно из практических наблюдений при тестировании бюджетных дисковых контроллеров я хотел бы выделить особо. Как показывает практика многочисленных тестов, возможности балансирования нагрузки ввода вывода между физическими дисками у SQL Server лучше, чем у аппаратных средств. Т.е. часто отказ от использования RAID-массивов позволяет в итоге получить более высокую производительность, чем на том же количестве шпинделей, но собранных в RAID любого уровня.