
Автор: Томас Грохсер (Thomas H. Grohser)
При содействии: Линдсей Аллен (Lindsey Allen)
Техническая экспертиза статьи: Sanjay Mishra, Lubor Kollar, Stuart Ozer, Thomas Kejser, Juergen Thomas, James Podgorski, Burzin Patel
Перевод: Александр Гладченко, Ирина Наумова
Редактура перевода: Алексей Халако
Дата издания: июнь 2009г.
Тематика статьи: SQL Server 2008
Резюме: Размер баз данных непрерывно растёт, так же, как и растут требования к надежности и доступности баз. Одновременно с этим как никогда важным становится требование быстрого и надежного восстановления данных. Этот документ посвящён проблемам проектирования устойчивого резервного копирования и решений по восстановлению очень больших баз данных (VLDB). В этой статье на реальном примере демонстрируется как лучше всего использовать функциональность SQL Server 2008 для осуществления резервного копирования и восстановления, которыми обладает SQL Server 2008, а также создание планов резервного копирования и восстановления VLDB по сети.
Введение
Резервное копирование и восстановление баз данных в SQL Server похожи на многие другие, окружающие нас в реальном мире вещи; Вы сможете не понять их ценность, когда столкнетесь с ними впервые. За эти годы все мы сталкивались с такими ситуациями, когда не оказывалось под рукой нужной резервной копии; следствием этого становилась потеря бизнеса компанией, потеря работы для людей и потери данных. Компании находят оправдания, для того, чтобы не делать резервное копирование и не создавать план восстановления. Часто слышно фразы, подобные этим: "У нас есть кластер, так что нам не нужна резервная копия", или "Нам не нужен план восстановления, потому что мы делаем резервные копии каждый день". Что мы поняли за эти годы, так это то, что резервные копии и план восстановления нужны во всех случаях.
Краткий обзор Решения
Соглашение о качестве сервиса
Самый важный шаг для создания успешной стратегии резервного копирования, это разработка и утверждение правильного соглашения об уровне сервиса (SLA). Если требования SLA неизвестны, невозможно организовать верную стратегию резервного копирования и восстановления.
SLA должно ответить на следующие вопросы:
- Размер базы данных. Определяется начальный размер и ожидаемый прирост в месяц или в год.
- Объем рабочей нагрузки. Характеризуется тем, какого размера достигает активная часть журнала транзакций в среднем и во время пиковых нагрузок.
- Время, необходимое для восстановления. Время восстановления, это максимальное время, необходимое для восстановления из резервной копии после отказа. Не путайте время восстановления и высокую доступность"; высокая доступность характеризуется ситуацией с отказом оборудования, когда восстановление из копии будет единственной возможностью восстановления данных.
- Сценарий полного отказа. Этот сценарий для самого худшего из возможных сбоев, касающегося задействованного оборудования и программного обеспечения организации в целом. Это может быть отказ всего центра данных, потеря всех данных из-за отказа единственного сервера и т.п.
Есть много других положений SLA, которые нужно не забыть согласовать, но мы не станем останавливаться в этой статье на абсолютно всех положениях возможного варианта соглашения.
Для рассматриваемого в настоящей статье варианта стратегии, требования в SLA были следующие:
- Размер базы данных был 2 Терабайта, ожидаемый прирост доходил до 4 Терабайт за всё время жизни решения.
- Объем рабочей нагрузки: очень большой, до 5 Гигабайт в минуту в пиковой загрузке, и приблизительно 0.5 Гигабайта в минуту во время выделенного для резервирования окна.
- Время восстановления: не более четырёх часов.
- Сценарий полного отказа: потеря всех данных в результате сбоя в масштабах целого центра данных, а также отказ оборудования центра.
Краткое описание
Функции резервного копирования и восстановления предоставляемые SQL Server достаточно просты Основной задачей становится проектирование решений, способных обеспечить исполнение всех требований бизнеса и заданный уровень эффективности даже в случае серьёзного отказа оборудования или программных систем.
Очень большие базы данных (VLDB) привносят свою специфику и дополнительные проблемы в процесс резервного копирования, особенно если эти базы находятся под большой нагрузкой. В целях обеспечения возможности восстановления после аварий вполне резонной мерой является размещение резервных копий баз данных в разных местах. Копирование их по сети привносит дополнительную сложность реализации, по сравнению с резервированием на локальные устройства долговременного хранения. Представьте себе задачу по резервному копированию OLTP базы данных, размером в пару Терабайт; с высокой рабочей нагрузкой; с жёсткими требованиями к производительности обслуживания транзакций и доступности; в данной ситуации абсолютно нереально использовать для резервирования программные интерфейсы (API) виртуальных устройств резервирования (Virtual Backup Device Interface - VDI), позволяющие задействовать имеющиеся в современных системах хранения (SAN) возможности резервирования, пригодные для использования с SQL Server. Кроме того, если задача осложняется ещё и тем, что соглашение о качестве сервиса требует полного восстановления системы менее чем через четыре часа (включая применение всех файлов копий журнала транзакций). Эта техническая статья как раз и посвящена описанию возможного варианта решения именно такой задачи, реализуемой с помощью средств SQL Server 2008.
Полное решение резервного копирования должно включать в себя как полную резервную копию, так и возможно, разностные резервные копии и множество резервных копий журнала транзакций. В описываемой тут стратегии, разностные резервные копии приводили бы к фактическому увеличению суммарной продолжительности процедуры восстановления баз данных, так что они в предлагаемом решении использоваться не будут. Резервные копии журнала транзакций в решении присутствовать будут, и выполняться они будут с частотой - один раз в минуту. Внедрение и настройка решений, когда резервные копии журнала транзакций доставляются и восстанавливаются на другом сервере, для баз данных большого размера само по себе достаточно сложное дело, так что описание подобных решений будет сделано в других статьях. Эта же статья сосредоточена на описании высокопроизводительных и хорошо масштабируемых методов создания полных резервных копий.
Как использовать данный документ
Вам предлагается краткий обзор того, как надежно и быстро создавать по сети полные резервные копии баз данных. Помимо формализации требований SLA, в статье показано, как задача была реализована и какие варианты решения и параметры были избраны для возможных настроек команд резервного копирования и восстановления. В тексте также встречаются разнообразные советы и рекомендации, которые могут вам помочь при проектировании подобных решений в промышленной среде.
Эта статья нацелена на описание эффективной стратегии резервного копирования и восстановления, и полагается на те возможности, которыми располагает SQL Server 2008 (большинство возможностей также доступны в SQL Server 2005, но все примеры сценариев используют синтаксис и возможности SQL Server 2008). Те же самые принципы подходят и для разностных резервных копий и копий журнала транзакций, но углублённое описание этих стратегий выходит за рамки настоящей статьи.
Эта статья не ставит целью описать пригодный на все случаи жизни процесс резервного копирования или план восстановления, она ограничивается описанием того, как реализовать надежное резервное копирование, и подобные реализации применимы для промышленных стратегий защиты от потери данных. Поскольку частота копирования данных зависит от бизнес-требований, вопрос частоты создания резервных копий баз данных также выходит за рамки этой статьи.
Реализация надежного резервирования по сети
Прежде всего, решение должно быть надежно. Надежное резервное копирование подразумевает что резервная копия должна восстанавливаться успешно и это не должно приводить к потере целостности данных с точки зрения приложения.
Когда резервную копию можно считать правильной?
Это один из таких вопросов, которые, будучи заданы десяти разным людям, в итоге выдадут одиннадцать непохожих друг на друга ответов. В рамках этой статьи, мы будем придерживаться следующих критериев:
- она должна находиться в другом месте, например, в другом центре данных.
- она должна успешно восстанавливаться.
- восстановленная база данных не должна показывать ошибки при запуске DBCC CHECKDB.
В итоге, полный цикл резервирования состоит из следующих шагов:
- Резервное копирование базы данных.
- Копирование файлов на хранение в удаленную область. В качестве хранилища может использоваться файловый сервер, ленточное устройство или их комбинация (этот шаг может быть объединен с первым, когда резервное копирование осуществляется непосредственно на устройство в сети).
- Восстановление базы данных из удаленной области.
- Выполнение проверки восстановленной базы средствами DBCC CHECKDB.
- Выполнение проверки корректности самих данных, чтобы удостовериться в их логической правильности с точки зрения приложения и пользователей. Этот шаг является дополнительным, но мы рекомендуем не исключать его из цикла. Основная часть проверки с прикладной точки зрения затрагивает трансформацию (ETL) данных из восстановленной базы данных в информационное хранилище, затем выполняется заранее продуманный набор отчётов, позволяющих убедиться в целостности данных.
Обратите внимание: Не все компании имеют удаленный центр данных и, если невозможно выполнить восстановление в другом месте, храните резервные копии в разных местах, не там, где исходные базы данных. Никогда не размещайте резервные копии в той же самой стойке, или на том же самом сервере, или на том же диске где размещены исходные данные.
Основные опции встроенного механизма резервирования и восстановления
Встроенные средства резервного копирования и команды восстановления в SQL Server 2008 предоставляют следующие возможности:
- Резервное копирование на локальный диск и последующее копирование файлов по сети.
- Резервное копирование непосредственно на ресурс для хранения резервных копий в сети.
Если резервное копирование выполняется на локальный диск, такая стратегия фактически работает быстрее, но требует дополнительного дискового пространства на сервере баз данных. Если резервное копирование выполняется на ресурс в сети, может подняться производительность стратегии в целом, не потребуется дополнительного дискового пространства на сервере баз данных. Вторая стратегия проще первой и поэтому в меньшей мере подвержена ошибкам. Если нет требований по хранению файлов резервных копий на локальных дисках, стоит выполнять копирования на распределённый ресурс в сети. Далее в этой статье пойдёт речь только об этой стратегии.
Что может пойти не так?
Для того чтобы понять, как все сделать правильно, необходимо для начала рассмотреть все возможные варианты отказов. Необходимо определить все возможные условия сбоя, а затем спроектировать способы защиты организации от этих состояний. Например, могут возникнуть следующие проблемы:
- Некорректная запись бит данных в файл резервной копии во время исполнения команды резервного копирования.
- Обслуживающий базу данных сервер выходит из строя во время операции резервного копирования.
- Хранилище резервных копий выходит из строя во время операции резервного копирования.
- Сбои в работе хранилища резервных копий после завершения резервного копирования.
Следующие подразделы статьи описывают те меры, которые были предприняты для защиты резервных копий от этих четырех проблем.
Выполнение надежного резервного копирования по сети
Допустим, имеется база данных с именем MyVLDB, которую нужно сохранить. База данных MyVLDB находится на сервере с именем SQL01. Файл-сервер, на котором мы хотим разместить резервную копию, называется BAK01. Полностью квалифицированное имя файлового ресурса \\backup. На рисунке 1 проиллюстрирована эта конфигурация.

Рисунок 1: Резервное копирование по сети
Следующая команда выполняет резервное копирование базы данных на файловый сервер.
BACKUP DATABASE MyVLDB
TO DISK = '\\BAK01\backup\MyVLDB.bak'
WITH INIT
Хотя это вполне допустимая команда, она не обеспечивает никакой защиты от перечисленных выше проблем. Далее представлены некоторые решения, которые помогут в случае нештатного поведения систем, и которые можно будет использовать в промышленной среде.
Защита от некорректной записи в файл резервной копии
Файлы могут оказаться испорченными в процессе записи. Первый и самый простой шаг, который Вы можете предпринять для защиты от подобной проблемы, это генерация контрольной суммы файла резервной копии, которая позволит потом удостовериться, что будет обнаружен любой возможный вид искажения файла резервной копии. Внесём соответствующие изменения в сценарий:
BACKUP DATABASE MyVLDB
TO DISK = '\\BAK01\backup\MyVLDB.bak'
WITH CHECKSUM, INIT;
Опция WITH CHECKSUM помещает контрольную сумму на каждую страницу файла резервной копии, что позволяет обнаруживать повреждения страниц файла резервной копии во время её восстановления. Резервное копирование с опцией CHECKSUM будет потреблять всего на 2%-3% больше ресурсов, чем предыдущий вариант резервирования, но это с лихвой окупается повышением надежности резервирования.
Защита от отказа сервера баз данных во время резервирования
Решение следующей проблемы зависит от того, что случится после отказа сервера баз данных в тот момент, когда он был занят созданием резервной копии. Если сбой сервера произошёл во время создания резервной копии, это приводит к невозможности использования файла этой резервной копии. Единственным способом устранить подобную проблему является повторная попытка создания резервной копии, которую следует предпринять сразу после того, как нормальная работа сервера будет восстановлена, например, после перезагрузки. В случае отказа резервного копирования, нужно избегать перезаписи резервной копии поверх уже существующих её файлов, чтобы на всякий случай была возможность восстановиться из последней успешной копии.
Одним из решений является добавление в имя файла резервной копии её порядкового номера. Можно хранить текущее значение номера, и увеличивать его каждый раз, когда выполняется резервная копия.
BACKUP DATABASE MyVLDB
TO DISK = '\\BAK01\backup\MyVLDB<BackupSequenceNumber>.bak'
WITH CHECKSUM, INIT;
Другой способ заключается в добавлении к имени файла даты и времени резервного копирования, и этот способ применим, если копирование достаточно делать раз в час или один раз в день. Следующий пример создает порядковый номер резервной копии, используя для этого функцию вычисления универсального времени (UTC):
-- использование GETUTCDATE() в качестве порядкового номера копии
DECLARE @FileName AS nvarchar(4000) = '\\BAK01\backup\MyVLDB' +
CONVERT(nvarchar(32), GETUTCDATE(), 112 )+ '.bak';
BACKUP DATABASE MyVLDB
TO DISK = @FileName
WITH CHECKSUM, INIT;
Альтернативный пример представлен ниже, в нём порядковый номер резервной копии создаётся путём приращения единицы к текущему порядковому номеру каждый раз, когда выполняется резервное копирование:
-- для нумерации копий используется возрастающая последовательность чисел
-- представленный ниже сценарий должен существовать отдельно для каждой БД,
-- каждая нумерация должна иметь свою создаваемую специально таблицу
USE MyVLDB;
GO
CREATE SCHEMA DBBackup;
GO
CREATE TABLE DBBackup.Sequence(
Number int NOT NULL,
ID int NOT NULL,
CONSTRAINT PK_Seq PRIMARY KEY CLUSTERED (ID ASC)
);
ALTER TABLE DBBackup.Sequence WITH CHECK ADD CONSTRAINT CK_Seq CHECK (ID=1);
ALTER TABLE DBBackup.Sequence CHECK CONSTRAINT CK_Seq;
INSERT INTO DBBackup.Sequence (Number) VALUES (1,1);
-- это соответствующая команда резервного копирования
DECLARE @SeqNumber AS int;
UPDATE MyVLDB.DBBackup.Sequence SET @SeqNumber= Number= Number+ 1 WHERE ID=1;
DECLARE @FileName AS nvarchar(4000) = '\\BAK01\backup\MyVLDB'
RIGHT('0000000' + CAST(@SeqNumber AS NVARCHAR(8)), 8) + '.bak';
BACKUP DATABASE MyVLDB
TO DISK = @FileName
WITH CHECKSUM, INIT;
Хотя этот метод выглядит более сложным, он более гибок. Следующие ниже примеры будут основываться на этом методе нумерации копий.
Защита от отказа сервера хранения копий
Файловые серверы для хранения резервных копий также могут отказать и от этого необходимо предусмотреть защиту. Способ предотвращения подобного отказа состоит в том, чтобы использовать дополнительный сервер (в нашем примере это BAK02). Размещение этого сервера ещё в одном центре данных (отличном от двух рассмотренных выше) обеспечивает ещё большую защиту в случае отказа.
На следующем рисунке показана последовательность резервного копирования, которая использует запасной резервный сервер и применяет другие методы, которые были рассмотрены ранее.
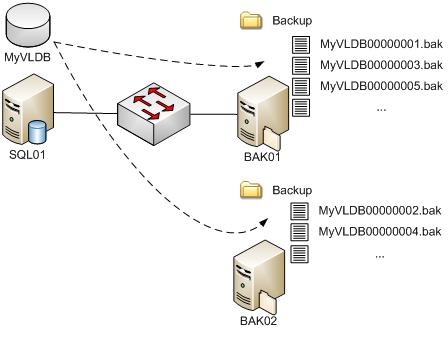
Рисунок 2: Защита от отказа сервера резервных копий
Резервная копия делается поочерёдно на двух серверах, и после двух полных циклов резервного копирования становится устойчивой к отказам, поскольку будут существовать две полные резервные копии на двух разных серверах в разных центрах данных.
Если запасного файлового сервера нет, желательно попробовать разделить логические диски (LUN) так, чтобы при хранении нескольких клонов резервной копии, частичный отказ дисковой подсистемы затронул бы только один набор файлов резервных копий.
Проверка восстанавливаемости резервной копии
Следующим логическим шагом после создания резервной копии должна быть проверка на возможность воспользоваться файлами резервной копии для восстановления базы данных. Лучшим способом проверить это является восстановление базы данных из сохранённого файла резервной копии.
Восстановление в базу данных Test Backup
Для того чтобы восстановить из копии тестовую базу данных, нужно иметь ещё один экземпляр SQL Server, установленный на резервном сервере, и ещё один логический диск - LUN, доступный серверу резервных копий. На втором сервере во время восстановления будут временно размещены файлы базы данных (диск должен быть достаточно большим, чтобы поместились файлы базы данных, размер которых может быть максимально возможным в обозримой перспективе). Для этих целей дисковый массив RAID0 является приемлемым компромиссом между производительностью, уровнем затрат и доступностью. Избыточность дисковых массивов тут не нужна, потому что база данных будет существовать временно. Уровень RAID 1/0 также допустим, если вы можете это себе позволить.
Ниже показана схема каталогов файловой системы сервера хранения резервных копий. Схема предусматривает место для размещения файлов восстанавливаемой базы данных.
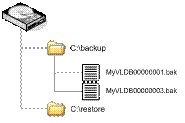
Рисунок 3: Файловая система сервера хранения резервных копий.
Для того чтобы получить из файла резервной копии MyVLDB00000001.bak информацию о схеме размещения базы данных по дискам, нужно выполнить следующую команду:
RESTORE FILELISTONLY FROM DISK = 'c:\backup\MyVLDB00000001.bak';
После извлечения из первого файла резервной копии информации об используемых исходной базой данных дисках, нужно создать команду восстановления базы, которая восстановит файлы данных базы в предназначенное для этого место на резервном сервере. При этом сохраняются те же самые логические имена файлов, какие были получены из файла копии предыдущей командой. Сделать это можно с помощью следующего запроса:
RESTORE DATABASE MyVLDB
FROM DISK = 'C:\backup\MyVLDB00000001.bak'
WITH
MOVE 'MyVLDB' TO 'C:\restore\MyVLDB.mdf',
MOVE 'MyVLDB_log' TO 'C:\restore\MyVLDB.ldf',
CHECKSUM;
Если процесс восстановления завершится без ошибок, можно считать, что файлы резервной копии не были повреждены.
Выполнение DBCC CHECKDB
Чтобы проверять целостность восстановленной базы данных, выполните следующую команду:
DBCC CHECKDB(MyVLDB) WITH NO_INFOMSGS, EXTENDED_LOGICAL_CHECKS, DATA_PURITY
Если эта команда не возвратит ошибок, можно быть уверенным, что резервная копия базы данных пригодна для восстановления базы в случае необходимости.
Автоматизация описанного процесса
Ниже представлен сценарий, который автоматически извлекает имена файлов из первого файла резервной копии и передаёт их на вход команды восстановления базы, выполняя затем инструкцию DBCC CHECKDB.
DECLARE @dbName AS sysname = 'MyVLDB';
DECLARE @BackupFileName AS nvarchar(4000) = 'C:\backup\MyVLDB00000001.bak';
DECLARE @DBFiles AS TABLE
(
LogicalName nvarchar(128),
PhysicalName nvarchar(260),
Type char(1),
FileGroupName nvarchar(128),
Size numeric(20,0),
MaxSize numeric(20,0),
FileID bigint ,
CreateLSN numeric(25,0),
DropLSN numeric(25,0) NULL,
UniqueID uniqueidentifier,
ReadOnlyLSN numeric(25,0) NULL,
ReadWriteLSN numeric(25,0) NULL,
BackupSizeInBytes bigint,
SourceBlockSize int,
FileGroupID int,
LogGroupGUID uniqueidentifier NULL,
DifferentialBaseLSN numeric(25,0) NULL,
DifferentialBaseGUID uniqueidentifier,
IsReadOnly bit,
IsPresent bit,
TDEThumbprint varbinary(32) NULL
);
INSERT INTO @DBFiles
EXEC sp_executeSQL N'RESTORE FILELISTONLY FROM DISK = @FileName',
N'@FileName NVARCHAR(4000)', @FileName = @BackupFileName;
-- Ищем выполненную последней, завершённую резервную копию
DECLARE @lastRestoreID AS bigint = ISNULL(
(SELECT TOP(1) restore_history_id FROM msdb.dbo.restorehistory
WHERE restore_type = 'D' and destination_Database_Name = @dbName
ORDER BY restore_history_id DESC), 0);
-- Создаём сценарий проверки восстанавливаемости
DECLARE @sqlcmd AS nvarchar(4000) =
'RESTORE DATABASE @RestoreName FROM DISK = @FileName WITH ';
DECLARE @IsFirst AS tinyint = 1;
WHILE ((SELECT COUNT(*) FROM @DBFiles) > 0)
BEGIN
DECLARE @LN AS sysname = (SELECT TOP(1) LogicalName FROM @DBFiles ORDER BY LogicalName);
SET @SQLcmd+='MOVE '''+@LN+''' TO ''C:\Restore\'+@dbname+@LN+'.dbf''';
DELETE @DBFiles WHERE LogicalName = @LN;
SET @SQLcmd += ', ';
END
SET @SQLcmd += ' CHECKSUM';
DECLARE @RC AS int;
EXEC @RC = sp_executeSQL @SQLCmd,
N'@RestoreName sysname, @FileName nvarchar(4000)',
@RestoreName = @dbName, @FileName = @BackupFileName;
IF (@RC <> 0 OR NOT EXISTS(SELECT TOP(1) *
FROM msdb.dbo.restorehistory
WHERE restore_type = 'D'
AND destination_Database_Name = @dbName
AND restore_history_id > @lastRestoreID))
RAISERROR ('Database restore NOT sucessfull', 16, 0);
DBCC CHECKDB(@dbName) WITH NO_INFOMSGS, EXTENDED_LOGICAL_CHECKS, DATA_PURITY
IF @@ERROR <> 0 RAISERROR ('Database restore NOT sucessfull', 16, 0);
Высокая производительность резервирования по сети
Копирование двухтерабайтной базы данных на локальные жесткие диски и затем её восстановление удовлетворяет временным требованиям на восстановление нашей системы SQL Server. Однако, этот простой процесс не может обеспечить адекватную защиту от сценариев полного отказа ,формализованных в соглашении SLA. С другой стороны, копирование базы данных по сети в удаленное хранилище защиту от полного отказа обеспечить может. Проблему может создать ограничение, накладываемое полосой пропускания сети, которое обычно не превышает обычно 1 Гигабита в секунду (Gbps). Когда мы изучали данную ситуацию, основным критерием для сравнения производительности было копирование данных по сети 1-Gbps на расстояние в 10 миль в другой центр данных. Этот процесс занимал более 24-х часов, что было совершенно неприемлемо. Необходимо было найти такое решение, которое давало бы возможность выполнять резервное копирование в рамках того окна времени восстановления, которое было указано в SLA.
Всесторонне переосмыслив все грани проблемы резервирования по сети и проведя множество испытаний, мы смогли сократить резервное копирование базы в 2Тб до 36 минут. Решение, которое мы назвали "многопоточным резервированием по сети" (в оригинале: "multistreamed backups over the network"), использовало восемь сетевых подключений, по 1-Gbps каждое. Увеличенный до гигантского размер фрейма был указан в настройках каждой сетевой платы, и каждая сетевая плата была соединена с задублированным по второму уровню коммутатором линией 10GE (10Gbit Ethernet), которая протянулась до второго сайта. Само резервное копирование заняло 2 часа 25 минут. Появившееся в SQL Server 2008 сжатие резервных копий позволило ещё сократить это время до 36 минут. База данных состояла из 32 файлов данных и одного файла журнала транзакций, которые занимали приблизительно 2,5 Терабайта на 9 логических дисках (файлы данных размещались на дисковом хранилище корпоративного класса - SAN, а журнал транзакций на локальных дисках - DAS). В таблице ниже показана продолжительность резервного копирования обычным способом и два наиболее быстрых подхода к резервированию по сети. Подробное описание каждой из реализаций приведено ниже.
| Попытка | Сеть | Продолжительность |
| Обычным способом | Одна 1Gbps сетевая плата, конфигурация по умолчанию | >24 часов |
| Многопоточное резервирование по сети | 8x1Gbps сетевых плат, гигантский фрейм | 2 часа 25 минут |
| Многопоточное резервирование по сети со сжатием | 8x1Gbps сетевых плат, гигантский фрейм | 36 минут |
Таблица 1: Продолжительность резервирования 2Tб на сервер в 10 милях по сети
Сокращение времени резервного копирования
Есть два способа повышения скорости выполнения резервирования: оптимизация и распараллеливание.
Сначала давайте рассмотрим внутреннее устройство резервного копирования. Число потоков, обслуживающих резервное копирование, зависит от числа логических дисков - томов, используемых для файлов базы данных, и от числа устройств резервирования. Это - очень важно знать, потому что этот факт позволяет управлять степенью параллелизма резервного копирования. До сих пор мы опирались на ту схему размещения файлов, которая показана на рисунке ниже. Одним из способов повышения производительности этой схемы является увеличение числа дисков и размещаемых на разных дисках файлов, как это будет описано в следующем разделе.
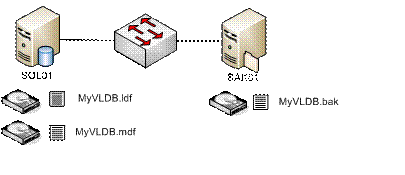
Рисунок 4: Типичное размещение файлов резервной копии базы по дискам
Параллельное использование нескольких дисков и файлов
Одним из подходов к повышению производительности является увеличение числа дисков и размещаемых на них файлов. Давайте посмотрим что получится, если добавить логические диски (отдельные LUN) для каждого из серверов, и разместить файлы базы данных и резервной копии на этих дополнительных логических дисках.
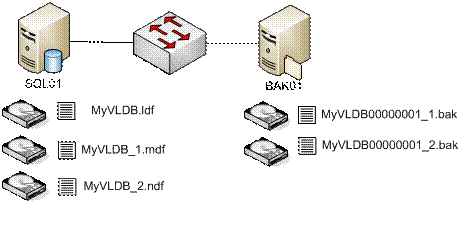
Рисунок 5: Добавление логических дисков
Ниже показана команда, которая выполняет резервное копирование в два файла.
BACKUP DATABASE MyVLDB
TO DISK = '\\BAK01\backup\MyVLDB00000001_1.bak',
DISK = '\\BAK01\backup\MyVLDB00000001_2.bak'
WITH CHECKSUM, INIT;
Такое использование команды резервного копирования приводит к некоторому выигрышу в производительности, но не к четырехкратному её увеличению, которое можно было бы ожидать (двойной выигрыш при чтении плюс двойной выигрыш на записи). Чтобы полностью представить себе возможный выигрыш, нужно учесть пропускную способность сети.
Использование нескольких сетевых плат
При резервном копировании по сети узким местом часто становится сеть. Увеличение пропускной способности сети больше чем 1 Gbps недешево, однако увеличение числа гигабитных сетевых плат в сервере относительно недорогая опция.
Если для резервного копирования добавить две сетевые платы на сервере базы данных и две на файловом сервере, где резервная копия будет храниться, конфигурация примет вид, показанный на рисунке 6.

Рисунок 6: Добавление сетевых плат
Многие производители сетевого оборудования предлагают сегодня решения, позволяющие объединять несколько сетевых плат в один логический сетевой интерфейс. Это решение хорошо работает на серверах, имеющих сотни клиентских подключений из сети, это решение позволяет использовать алгоритмы балансировки нагрузки, в зависимости от того, какие клиенты работают с сервером. В нашем случае нужно увеличить скорость между двумя узкоспециализированными серверами. Для этого мы использовали разделение сети на логические подсети. В таблице ниже показаны подсети для каждой сетевой платы двух серверов.
| Сетевая плата | Сервер SQL01 | Сервер BAK01 |
| Access | 192.168.1.1 МАСКА 255.255.255.0 | 192.168.1.2 МАСКА 255.255.255.0 |
| Backup 01 | 192.168.2.1 МАСКА 255.255.255.0 | 192.168.2.2 МАСКА 255.255.255.0 |
| Backup 02 | 192.168.3.1 МАСКА 255.255.255.0 | 192.168.3.2 МАСКА 255.255.255.0 |
Таблица 2: Подсети
Каждая сетевая плата находится в своей подсети (192.168.1.0/24, 192.168.3. 0/24). Теперь можно внести небольшие изменения в команду резервного копирования, указав там IP - адреса вместо имён серверов. Таким способом становится легко управлять тем, какая подсеть, а, следовательно, и какая сетевая плата будет использоваться для транспортировки данных. Тот факт, что все логические подсети будут находиться на одном и том же втором физическом уровне сети, не будет иметь никакого отрицательного влияния на это решение.
BACKUP DATABASE MyVLDB
TO DISK = '\\192.168.2.2\backup\MyVLDB00000001_1.bak',
DISK = '\\192.168.3.2\backup\MyVLDB00000001_2.bak'
WITH CHECKSUM, INIT;
В случае восстановления, это работает по той же схеме.
RESTORE DATABASE MyVLDB
FROM DISK = '\\192.168.2.2\backup\MyVLDB00000001_1.bak',
DISK = '\\192.168.3.2\backup\MyVLDB00000001_2.bak'
WITH CHECKSUM, NORECOVERY;
Точно также всё будет работать и с большим числом сетевых плат. В описываемых в статье экспериментах проверялась параллельная работа 16 сетевых плат.
Увеличение производительности будет наблюдаться и от передачи по сети нескольких файлов одновременно с помощью одной сетевой платы.
BACKUP DATABASE MyVLDB
TO DISK = '\\192.168.2.2\backup\MyVLDB00000001_1.bak',
DISK = '\\192.168.3.2\backup\MyVLDB00000001_2.bak',
DISK = '\\192.168.2.2\backup\MyVLDB00000001_3.bak',
DISK = '\\192.168.3.2\backup\MyVLDB00000001_4.bak'
WITH CHECKSUM, INIT;
Эмпирическим путём было показано, что в зависимости от производительности используемых ресурсов (главным образом серверов и сетевых плат), от двух до четырёх файлов через одну сетевую плату передаются довольно хорошо. Однако, только тесты в конкретных условиях заказчика могут помочь найти оптимальное число передаваемых через сетевую плату файлов.
Рекомендации по общему числу используемых файлов
На основании результатов множества экспериментов, были выработаны рекомендации по оптимизации резервного копирования. Подспудно было также выяснено, что резервное копирование работало лучше в тех случаях, когда все ресурсы загружались равномерно. Для получения оптимальных результатов, все представленные ниже равенства должны выдерживаться. Уравнения перечислены в порядке их значимости, с представлением рекомендованных значений для n, которые выделены жирным шрифтом.

Файлы базы данных должны быть равномерно распределены по логическим дискам, а файлы резервных копий должны равномерно распределяться между сетевыми платами.
В Таблице 3 показаны примеры сбалансированного размещения файлов и использования дисков, которые обеспечивают хорошую производительность резервного копирования. Эти значения оптимальны только для повышения производительности резервного копирования. Подобного увеличения производительности ввода-вывода обычной базы данных не произойдёт, если вместо четырёх файлов данных, на одних и тех же логических дисках будет размещено восемь файлов данных.
В контексте представленных выше формул, можно выделить несколько примеров хороших сочетаний процессорных ядер, файлов, логических дисков и сетевых плат.
| Процес- сорные ядра |
Логические диски для файлов данных |
Сетевые платы для резервного копирования |
Файлы данных |
Файлы резервных копий |
| 2 | 1 | 1 | 2 | 2 |
| 4 | 2 | 2 | 2 | 4 |
| 4 | 4 | 2 | 4 | 4 |
| 8 | 2 | 2 | 2 | 8 |
| 8 | 4 | 2 | 4 | 8 |
| 16 | 2 | 2 | 8 | 8 |
| 16 | 4 | 4 | 8 | 8 |
| 16 | 4 | 4 | 16 | 16 |
| 16 | 8 | 4 | 16 | 16 |
| 32 | 8 | 4 | 16 | 16 |
| 32 | 8 | 8 | 16 | 32 |
| 32 | 16 | 8 | 16 | 32 |
| 64 | 16 | 8 | 32 | 32 |
| 64 | 32 | 16 | 32 | 64 |
Таблица 3: Сбалансированное распределение файлов по дискам
Дополнительные способы оптимизации и рекомендации
Разделение сетей для резервного копирования и общего доступа
Всегда можно рассчитывать на хороший эффект от разделения сети общего доступа и сети для резервного копирования по физически независимым, разным сетям. Из-за разной природы трафика сетей общего доступа и сети резервного копирования, коммутаторы не всегда могут оптимально обслуживать одновременно два этих вида трафика. Кроме того, для достижения высокой пропускной способности трафика резервного копирования часто требуется большая часть ресурсов коммутатора.
Вообще, всегда было хорошей практикой не выпускать большой трафик за пределы одного коммутатора (если коммутатор имеет несколько модулей, не выпускайте трафик за пределы одного модуля, если это возможно).
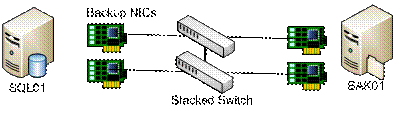
Рисунок 7: Эффективное использование аппаратных средств сетевого коммутатора
Конфигурация на Рисунке 7 использует аппаратные средства сетевого коммутатора существенно эффективнее, чем на рисунке 8.
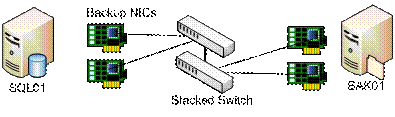
Рисунок 8: Менее эффективное использование аппаратных средств сетевого коммутатора
Большие фреймы
Максимальный размер пакета сети Ethernet в нормальных условиях составляет 15000 байт (равен размеру фрейма). Это означает то, что для передачи по сети 1 Мегабайта, его придётся разбить на 700 пакетов, которые будут переданы один за другим.
Сегодня можно приобрести такие сетевые платы и коммутаторы, которые поддерживают пакеты Ethernet с большими размерами фрейма. Для таких фреймов сетевых плат и коммутаторов даже существует специальное название - " jumbo frames ".
Чем больше размер фрейма, тем быстрее передача данных, потому что для обмена между серверами потребуется меньше итераций.
Наиболее распространёнными размерами больших фреймов являются величины около 4088 и 9016 Байт (включая заголовки Ethernet и большого фрейма). Например, если размер фрейма будет 9016 Байт, тогда для передачи 1 Мегабайта понадобится всего 117 пакетов.
Эмпирические исследования показали, что при увеличении размера фрейма до 9016 Байт, производительность сети практически удваивается.
BLOCKSIZE
Параметр, который задаёт используемый командой BACKUP размер блока, должен соответствовать размеру блока записи устройств долговременного хранения. Когда запись осуществляется на отдельный диск, будет работать достаточно хорошо даже используемое по умолчанию для размера блока значение равное 512. Если же запись направлена на RAID - массив или на SAN, стоит убедиться в том, что используемое по умолчанию значение не окажется меньше, чем, например, 65536.
При резервном копировании по сети нужно подобрать такое значение, которое бы позволило заполнять сетевые пакеты наиболее плотно. Имейте также в виду, что разбиение данных на пакеты работает в обоих направлениях. Выбор в качестве размера блока 512 Байт приведет к тому, что в сетевой пакет будет помещаться два блока (принимая во внимание то, что размер фрейма Ethernet равен 1500 Байт). Т.о. для передачи одной страницы базы данных понадобится 8 сетевых пакетов. С другой стороны, запись блоками по 4096 Байт будет помещаться в 3 сетевых пакета, а для передачи одной страницы базы данных понадобится 6 сетевых пакетов.
Можно привести ещё дополнительные примеры, полученные в результате проводимых при написании настоящей статьи тестов; при использовании больших фреймов размером 9016 Байт наилучшие результаты получались при размере блока 8192 Байт, а при использовании больших фреймов размером 4088 Байт, наилучшие результаты получались при размере блока 65536 Байт.
BUFFERCOUNT и MAXTRANSFERSIZE
Из параметров команды BACKUP можно выделить такие, которые также очень сильно влияют на производительность резервного копирования, это параметры BUFFERCOUNT и MAXTRANSFERSIZE. К сожалению, даже недели тестов не смогли помочь составить правило подбора оптимальных значений для этих параметров, поэтому Вам также необходимо будет выяснять оптимальные значения тестированием в Вашей среде. В качестве совета. для значения параметра MAXTRANSFERSIZE если у Вас система x64 или IA64 с достаточным объёмом оперативной памяти, можно начать тестирование со значения максимального размера буфера 4 Мб (4194304). Для получения более подробной информации о параметре BUFFERCOUNT и о других оптимизирующих параметрах, обратитесь к рекомендациям по настройке производительности сжатия резервных копий в технической статье: Tuning the Performance of Backup Compression in SQL Server 2008
В некоторых случаях, при проведении тестов для этой статьи, лучшие результаты получались при существенно меньших значениях параметров, но выбор значений был непредсказуем. Для промышленного применения стоит выполнить всестороннее тестирование разных вариантов, и убедиться, что лучшие результаты хорошо воспроизводятся. Если же нет возможности провести такую работу - лучше сохранить параметры по умолчанию.
Сжатие резервной копии
Сжатие резервных копий (новая функция, появившаяся в SQL Server 2008) предоставляет возможность увеличить производительность резервирования и в то же время существенно сократить потребляемое копией дисковое пространство, которое выделено для хранения резервных копий. Для включения сжатия резервной копии, в команде BACKUP нужно добавить опцию WITH COMPRESSION.
В представленном ниже примере запроса показано, как включить сжатие резервной копии.
BACKUP DATABASE MyVLDB
TO DISK = '\\BAK01\backup\MyVLDB.bak'
WITH CHECKSUM, INIT, COMPRESSION;
Степень сжатия в действительности зависит от данных, которые хранятся в базе. Для большинства баз данных (цифровая информация, денежно-кредитные операции, дата и время, простой текст), коэффициент сжатия будет находиться между 1:4 и 1:6. Для баз данных содержащих некоторые другие типы данных, например, картинки, которые уже в сжатом формате, можно ожидать результаты похуже. Для получения более подробной информации об использовании сжатия с разными типами данных, смотрите статью в SQL Server Books Online: Сжатие резервных копий.
В проводимых для этой статьи тестах, наблюдалось сокращение времени резервного копирования с 125 до 36 минут, при сжатии файла на 20 процентов от первоначального размера.
У сжатия данных есть один недостаток- повышение утилизации процессорных ресурсов.
SQL Server производитт сжатие в одном потоке, который пишет данные в файл резервной копии, так что число файлов резервных копий определяется числом процессорных ядер, которые будут выполнять сжатие параллельно. Чтобы ограничить использование процессоров для резервного копирования, можно использовать Регулятор Ресурсов (Resource Governor), с помощью которого можно отдавать другим подключениям больше ресурсов.
Если используется прозрачное шифрование базы данных (TDE), не следует пытаться использовать для шифруемой базы ещё и сжатие, потому что зашифрованные данные сжиматься достаточно плохо. Если указание опции сжатия при формировании каждой команды резервного копирования неудобно, можно с помощью системной хранимой процедуры sp_configure установить автоматическое сжатие при создании всех резервных копий на сервере:
sp_configure 'backup compression default', 1
reconfigure
Тут следует быть осторожным, поскольку если сжатие включается на уровне всего сервера, оно будет применяться и для разностных копий и для копий журнала транзакций. И если повышенная утилизация процессоров из-за сжатия не будет проблемой для полных резервных копий (такие копии обычно не планируют на время пиковых нагрузок), использование сжатия копий журнала может вызвать проблемы во время активной работы пользователей.
Рекомендации по аппаратным средствам файловых серверов, предназначенных для хранения копий
Дисковые устройства
К дискам, используемым для хранения и проверки восстанавливаемости файлов резервных копий, не применяются такие же высокие требования, как к дискам промышленных серверов. Так происходит потому, что у них почти все операции ввода-вывода выполняются последовательно и не носят случайный характер. Поэтому SATA диски в большинстве случаев очень хорошо подходят для этих целей.
Настройка RAID-контроллера
Для создания массивов логических дисков, на которых решено хранить файлы резервных копий, стоит выбрать большой размер сегмента (64 Кб, 128 Кб, 256 Кб и выше). Также, стоит установить полное кэширование записи, а кэширование чтения можно полностью отключить. Можно ещё активизировать кэш записи отдельных шпинделей, так как если во время резервного копирования произойдёт сбой по питанию, резервная копия так и так станет непригодной, и в таком случае не имеет значения, были ли потеряны какие-либо байты в кэше записи или нет.
Для тех логических дисков, которые будут задействованы в пробном восстановлении базы из копии, размер сегмента устанавливается в 64 Кб, применяется политика 100-процентного кэширования записи, а кэширование чтения выставляется на 0 процентов.
Выбор уровня RAID (1, 10, 5, 6 …) зависит от возможностей используемого RAID-контроллера или используемой системы хранилища. Поскольку нагрузка на файловом сервере при резервном копировании/восстановлении является последовательной записью и чтением данных, контроллер будет кэшировать данные, пока он не закончит запись всего страйпа целиком, в этом случае можно использовать любой уровень RAID. Если контроллер ведёт себя по-другому, и производительность является критическим параметром, массивы RAID1 или RAID10 будут единственным возможным вариантом.
Настройка HBA
Если в качестве дисков для файлов резервных копий используется дисковая подсистема типа SAN, максимальную глубину очереди для адаптеров, которые используются в подключении SAN, нужно увеличить настолько, насколько это возможно. Значение по умолчанию составляет 32, но резервное копирование и восстановление будут работать намного лучше при значениях близких к 256. Более подробную информацию можно найти в статье Настройка Windows Server 2008/2003 x64 для обслуживания SQL Server 2008, в разделе "NumberOfRequests и MaximumSGList".
Сетевые платы
Следует очень разборчиво подходить к выбору сетевых плат, которые будут использоваться на серверах. Число портов ещё не гарантирует адекватную производительность ввода-вывода для всех этих портов в одно и то же время. Бывает так, что два четырехпортовых адаптера могут оказаться более производительными, чем один адаптер с четырьмя портами. Количество процессорного времени, используемого драйвером сетевого интерфейса, также очень важно. Бывают такие сетевые платы, которые используют до 50 процентов ресурсов одного процессора, и в то же время есть другие, которые используют всего 3 - 5 процентов.
Если для резервного копирования используется несколько сетевых плат, очень важно, чтобы они использовали разные процессоры, т.е. чтобы их прерывания были привязаны к разным процессорным ядрам.
Системы на основе NUMA
Если сервер использует архитектуру с неоднородным доступом к памяти (NUMA), необходимо убедится в том, что все адаптеры ввода-вывода (например, NIC, RAID и HBA) распределены между всеми NUMA - узлами системы.
Вычисление времени, необходимого для резервного копирования и восстановления базы данных
Одним из ключевых элементов SLA является тот интервал времени, который закладывается на задачи резервного копирования, т.е. нужно будет рассчитать и запланировать время, которое займёт весь этот процесс. Это поможет выполнить требования спецификации ко времени восстановления работоспособности, а также, это помогает сформировать другие важные моменты аварийного плана, такие как частота выполнения резервных копий и параметры сжатия. Определение времени, занимаемого процессами резервного копирования и восстановления, выполняется в несколько шагов. Вначале необходимо вычислить объём копируемых данных:
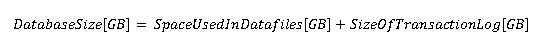
Если ожидается постоянный рост объёма данных во времени, размер файла полной резервной копии по истечении заданного периода времени может быть определен по следующей формуле:
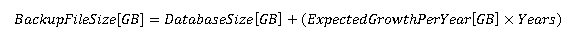
С другой стороны, если прирост относителен, для оценки будущего размера можно воспользоваться другой формулой:
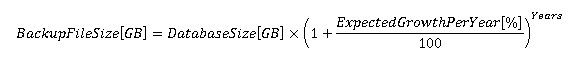
К полученному по формуле значению всегда стоит добавлять не меньше 10 процентов, в качестве буфера безопасности.
Далее, нужно определить максимальную продолжительность параллельного, последовательного чтения и записи используемых дисковых подсистем. Для того чтобы измерить эти значения при тестировании резервного копирования и восстановления, можно использовать системную утилиту Performance Monitor (известную ещё в некоторых версиях операционной системы Windows как System Monitor).
В результате, должно получиться 5 значений. Если имеется несколько логических дисков и сетевых плат, эти значения могут отличаться, и всегда нужно использовать самые худшие результаты вычислений.
- Производительность сетевого адаптера (МБ/сек);
- Производительность логического диска хранилища копий при последовательном чтении (МБ/сек);
- Производительность логического диска хранилища копий при последовательной записи (МБ/сек);
- Производительность логического диска файла базы данных при последовательном чтении (МБ/сек);
- Производительность логического диска файла базы данных при последовательной записи (МБ/сек).
После этого, опираясь на данные о числе логических дисков для параллельной работы с файлами базы данных, на число логических дисков, используемых для параллельной работы с файлами резервных копий и число используемых сетевых плат, можно ввести следующие индикаторы производительности:

Коэффициент сжатия резервной копии определяется так:
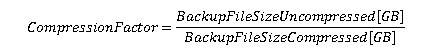
Если сжатие не используется, это приведет к тому, что коэффициент сжатия станет таким: CompressionFactor = 1.
Производительность резервного копирования будет ограничена следующим значением:

В большинстве случаев, без сжатия резервной копии производительность сети будет наименьшей по сравнению с производительностью дискового чтения и записи, но когда сжатие включено, основным ограничением может стать чтение из базы: DatabaseReadPerformance, или другие, не учтенные пока компоненты, такие как загруженные сжатием процессорные ядра.
В простом случае, для оценки времени копирования базы данных можно использовать следующую формулу:
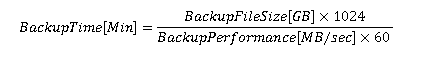
Вычисления для расчета времени восстановления будут сложнее. Сначала нужно узнать, поддерживает ли используемая система мгновенную инициализацию файлов. Эта возможность позволяет SQL Server создавать файлы данных на томах NTFS без обнуления занимаемого файлами места во время создания или расширения файла. Поскольку у этого механизма существуют связанные с безопасностью риски, такой возможностью можно воспользоваться, только если учетной записи, под которой запущена служба SQL Server предоставить в локальных политиках право "Perform Volume Maintenance". Если учетная запись пользователя входит в группу локальных администраторов, это право ей будет предоставлено по умолчанию (Примечание: время инициализации файла журнала транзакций может ограничивать производительность, так как занимаемое этим файлом место не может не заполняться нулями).
Если разрешена мгновенная инициализация файлов, а значение FileInitFactor равно коэффициенту сжатия резервной копии, мы получим следующую формулу:

И точно так же, как в случае с расчетом времени резервного копирования, оценить время на восстановление из копии можно так:

В случае если RestoreTime или BackupTime выше заданных SLA значений, можно воспользоваться изложенными ранее рекомендациями по уменьшению этих значений. Распараллеливание операций обычно ускоряет процесс больше чем попытка ускорить работу одного из компонент во всей цепочке. В сценариях с очень высокой производительностью стоит задуматься о применении обоих подходов.
Для расчета времени выполнения полного цикла резервирования (включая проверку), можно использовать следующую формулу:
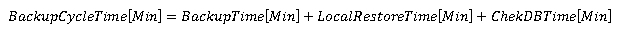
Значение BackupTime тут используется такое, как было описано ранее, а две другие переменные вычисляются так:

Обратите внимание: на исполнение команды CHECKBD может потребоваться больше времени, чем время, которое необходимо для чтения с диска. Оно зависит от сложности схемы базы данных, и оно точно не будет меньше времени чтения.
Заключение
Microsoft и, непосредственно команда SQL Server постоянно совершенствуют технологии обеспечения живучести систем, которые призваны помочь клиентам и партнерам решать задачи резервного копирования и восстановления в масштабах предприятия. SQL Server 2008 обеспечен для этих задач всем необходимым функционалом, на который могут положиться специалисты и который помогает успешно справляться с присущими сегодняшнему дню требованиями по управлению и защите данных. За счёт усовершенствований в ключевых областях, SQL Server 2008 стал надёжной платформой для обслуживания очень больших баз данных.
Эта техническая статья предоставляет только краткий обзор возможностей резервного копирования и восстановления, а также некоторых функциональных возможностей SQL Server 2008.
Если эта статья помогла Вам, пожалуйста, сообщите автору о Ваших впечатлениях. Пришлите условную оценку статьи по пятибалльной системе и напишите, почему Вы дали такую оценку?
Вот пара вопросов, которые помогут Вам оценить материал статьи:
- Является ли оценка высокой из-за хороших примеров, хороших снимков с экрана, понятного изложения или по другим причинам?
- Является ли оценка низкой из-за неудачных примеров, некачественных снимков с экрана или плохого изложения материала?
Приложение: Используемые аппаратные средства
Сервер баз данных:
- HP Superdome с 16 двуядерными процессорами, 1.6 ГГц, 24 Мб кэш, 256 Гб ОЗУ;
- 8 двухпортовых HBA для подключения к SAN файлов данных БД;
- 8 RAID контроллеров SAS для журнала транзакций;
- 32 сетевые платы;
- Логические диски SAN были каждый по 512Гб, составленные из 256 шпинделей 15K RPM, собранные в RAID10.
Файловые серверы копий:
- HP Integrity rx 7640 Servers с 8 двуядерными процессорами, 1.6 ГГц, 8 Мб кэш, 32Гб ОЗУ;
- 4 RAID контроллера SAS (каждый с кэшем 512 Мб);
- 96 SATA дисков 7,200 RPM, собранные в 32 логических диска RAID1;
- Остальные диски использовались для создания 4 логических дисков RAID0, использовавшихся для восстановления базы данных;
- 8 двухпортовых сетевых плат (8 портов использовались для файлового ресурса резервных копий).
Сетевое оборудование:
- Коммутатор Cisco C3750E с размером фрейма 4 088 байт
Параметры настройки резервного копирования:
- BLOCKSIZE: 65536
- BUFFERCOUNT: 256
- MAXTRANSFER: 4 Мб
- Число файлов резервной копии: 32 (по 4 на сетевую плату)
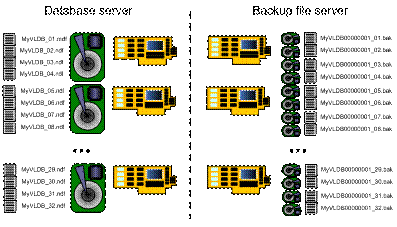
Рисунок 9: Сайзинг дисков и распределение файлов на сервере баз данных и файл-сервере резервных копий.
Сетевые платы, которые использовались для резервного копирования, были равномерно распределены внутри сервера, а процессорные ядра, обслуживающие прерывания сетевых плат, были выбраны с учётом топологии узлов NUMA, чтобы ввод-вывод каждой сетевой платы обслуживался оптимальными процессорами.
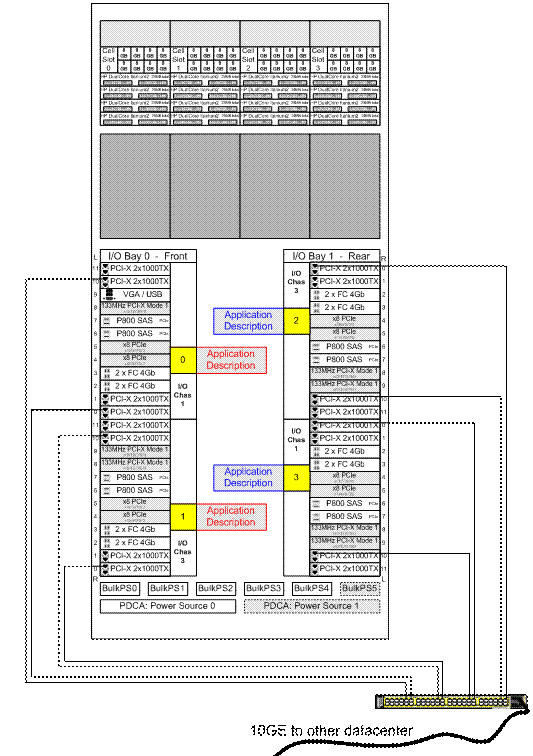
Рисунок 10: Конфигурация сети сервера баз данных для резервного копирования.
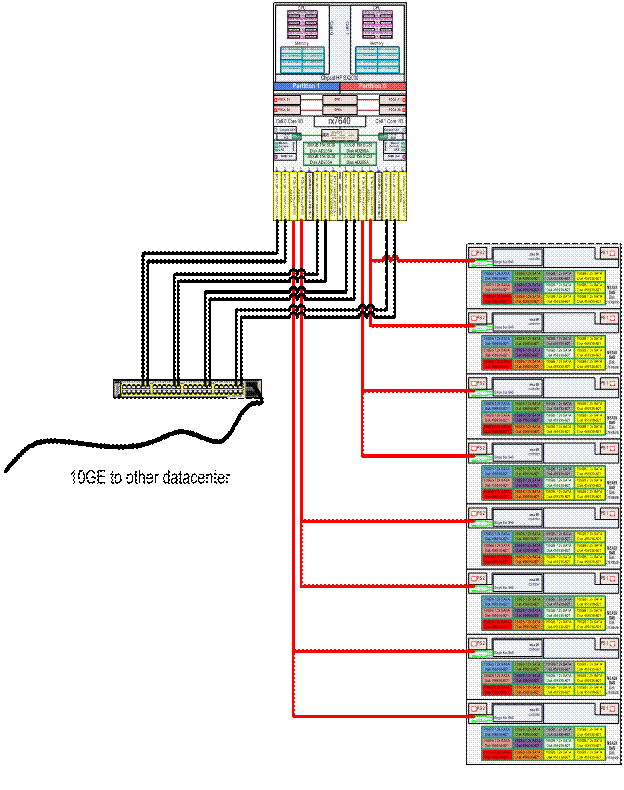
Рисунок 11: Конфигурация сети и дисковой подсистемы файлового сервера резервных копий