
Micro Focus Data Express - утилита для подготовки качественных тестовых данных, позволяющая использовать их при тестировании разрабатываемых приложений.
Преимущества
Обеспечение регулятивного и юридического соответствия требованиям приватности данных тестирования
Законодательные требования к приватности данных и отраслевые нормативы, такие как PCI, HIPAA, Basel II, Sarbanes Oxley и др., требуют защищенности информации по персональной идентификации. Хотя эксплуатационные данные обычно имеют тщательно разработанные уровни защиты как на логическом, так и на физическом уровне, среда разработки может вообще не иметь подобной защиты. Data Express предоставляет централизованный автоматизированный механизм для маскирования источников корпоративных данных и согласованного создания защищенных деидентифицированных, но при этом реалистичных данных, которые могут использоваться во время разработки и тестирования, что дает соответствие нормативам и снижает риск утечки данных. Кроме того, Data Express также может предоставить важную и безопасную тренировочную среду для конечных пользователей, в то время как использование реальных эксплуатационных данных для тестирования или обучения может нарушить законодательные требования к приватности данных.
Повышение производительности тестирования и ускорение времени выхода на рынок
Предоставление правильной среды данных тестирования может значительно улучшить процесс поставки приложений, что окажет положительное влияние на качество бизнес-приложений и на общую быстроту адаптации к инициативам модернизации. Громоздкие, ручные или плохо интегрированные процессы тестирования добавят к решаемой задаче значительное количество затраченного времени, издержек и рисков. Тестирование может стать обязанностью, не являясь ИТ-ресурсом, при этом тестирование часто лимитирует ИТ-процессы. Data Express позволяет организациям улучшить процесс тестирования, быстро и согласованно предоставив данные тестирования тогда, когда они потребуются и в том формате, в котором они необходимы. Это поможет разработчикам, группам обеспечения качества и администраторам баз данных работать эффективно с защищенными, полными и совместимыми корпоративными данными.
Снижение затрат и повышение качества
Процесс тестирования является главным элементом жизненного цикла разработки, при этом критически важна доступность подходящих и точных данных для системного, модульного и приемочного тестирования. Ручные процессы для безопасности и сокращения размера данных тестирования могут потребовать как недопустимо высокого уровня использования ресурсов, так и слишком больших затрат времени, при этом сохраняется потенциальная возможность получения неподходящих результатов. Предоставляя автоматизированное и воспроизводимое решение, Data Express снижает необходимость в ресурсах за счет создания данных тогда, когда они необходимы, что сберегает время и финансы в цикле тестирования и позволяет улучшить качество.
Благодаря предоставлению централизованного подхода, в котором учитываются отношения между данными, Data Express значительно снижает объем данных тестирования, при этом объем типичных данных тестирования может быть снижен более чем на 90%. За счет такого значительного снижения объема данных время, требуемое для цикла тестирования, может быть сокращено, в частности может быть достигнута экономия времени обработки и дискового пространства в средах универсальных компьютеров. Благодаря своему последовательному и повторяемому процессу, Data Express может гарантировать повторяемую надежность данных для тестирования, что устраняет риск "ложного тестирования".
Доступ, анализ, кодирование и тестирование - исчерпывающий подход к модернизации приложений
Data Express можно комбинировать с другими инструментами для модернизации и разработки приложений от Micro Focus, что сформирует исчерпывающий подход к модернизации приложений и к ведению соответствующих проектов. Например, Micro Focus Modernization Workbench создает постоянно актуальное хранилище данных для бизнес-анализа и технического анализа приложений, выполняемых в компании. Полученные данные позволяют идентифицировать и выполнить операции разработки, согласующие приложения с бизнес-приоритетами. Предоставляемая информация, такая как программные взаимоотношения использования данных и потоков данных, может использоваться в Data Express.
Модернизация и сопровождение корпоративных приложений может быть реализована в Micro Focus Mainframe Express Enterprise Edition, Micro Focus Studio Enterprise Edition и в Micro Focus Net Express . Эти продукты позволяют корпорациям создавать, сопровождать и улучшать приложения, с предоставлением среды для разработки и тестирования, что может выполняться с использованием функциональности по сокращению и защите данных тестирования в Data Express.
На рисунке: Реляционные базы данных. Иерархические базы данных. Последовательные файлы. Подмножества данных. Правила извлечения данных. Приватные данные. Правила маскировки.
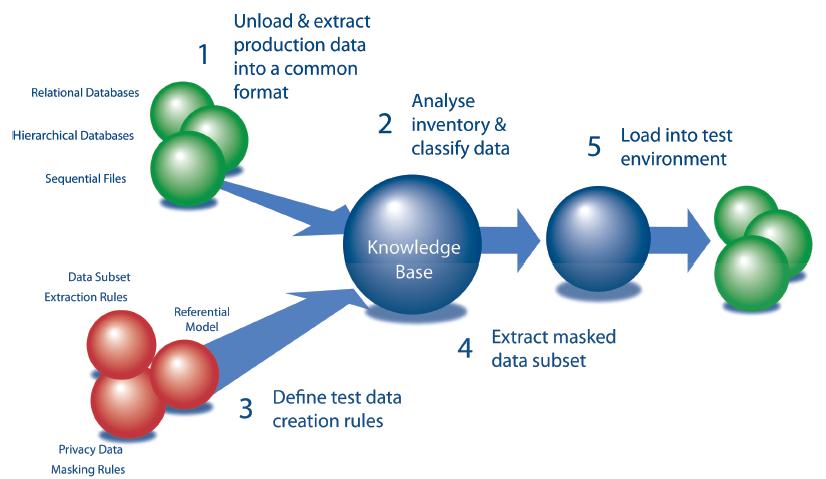
- Выгрузка и извлечение эксплуатационных данных в общем формате
- Анализ хранилища и классификация данных
- Определение правил создания данных для тестирования
- Извлечение замаскированных подмножеств данных
- Загрузка в среду тестирования
Функции и возможности
Стратегическая центральная база знаний обеспечивает целостность, повторяемость и генерацию отчетов для различных платформ и хранилищ данных
Формирующий компонент Data Express позволяет хранилищу организационных данных извлекаться, сортироваться и централизованно храниться в базе знаний, в едином репозитории метаданных. Могут быть упорядочены в едином местоположении такие стратегические и бизнес-критические хранилища данных приложений, как IMS DB, DB2, VSAM, ADABAS, Oracle, SQL Server, Sybase, а также любое ODBC-доступное хранилище данных. Результирующая централизованная информация затем может быть проанализирована с одиночного компьютера администратора, что дает единое представление о критически важных данных, единую базу, из которых можно извлекать подмножества данных, и единый массив информации для составления отчетов. После того как база знаний будет сформирована, нет необходимости повторять этот процесс даже при изменении критериев маскирования и извлечения подмножеств. Поддержка в течение всего жизненного цикла системы упрощает сопровождение базы знаний по мере вовлечения новых хранилищ данных.
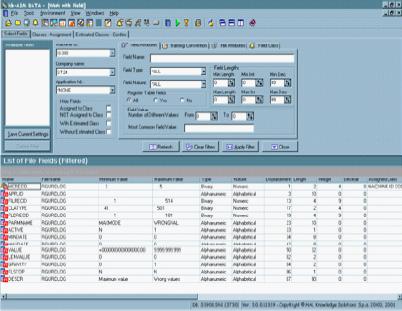
Формирование базы знаний
Исчерпывающее и настраиваемое маскирование обеспечивает приватность данных для тестирования
Модуль маскирования данных Data Masking поддерживает быструю деидентификацию или искажение данных согласно предопределенному набору правил и критериев. После того как компонент Builder создаст центральное хранилище данных, данные систематизируются и инвентаризируются. Это позволяет давать определения и выполнять набор правил и действий по деидентификации данных согласно требуемым критериям. Модуль Data Masking обеспечивает быструю генерацию согласованных сред тестирования. Он устраняет такие элементы данных, которые могут использоваться для получения дополнительных знаний о секретной информации, и делает невозможным отслеживание персональной информации.
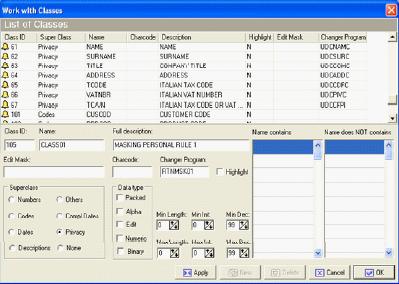
Определение классов с помощью Data Express
Для выполнения деидентификации данных модули Builder и Data Masking позволяют:
- создавать хранилище из данных, полученных из баз данных
- выполнять быструю классификацию и находить секретные данные, включая возможность работы с отпечатками пальцев, что позволяет принимать за образцы выбранные известные поля персональной идентификации для нахождения неизвестных секретных полей с теми же самыми характеристиками
- Маскирование персональной информации, кодов и т.д. обеспечивает анонимность секретных данных в средах тестирования.
- Создание деидентифицированной ссылочной целостности полностью маскирует данные в хранилищах данных, но при этом не снижает их полноценности и точности, что необходимо для точного и эффективного тестирования
- Совместимость с европейскими, американскими и английскими законами о персональной информации и с такими регулятивными стандартами, как PCI, BASEL II, MIFID, Sarbanes-Oxley, HIPAA и другими.
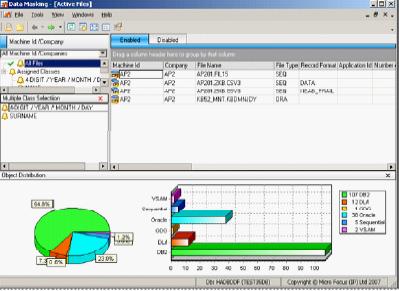
Маскирование данных с выбором множественных классов
Возможности процесса Data Masking:
- Использование поставляемых процедур изменения позволяет настроить процесс деидентификации в соответствии с индивидуальными требованиями и при необходимости встраивать уже имеющиеся процессы маскирования
- Предопределенные процедуры маскирования преобразуют в значимую информацию фамилии, адреса, даты, телефонные номера, региональные форматы, такие как номера SSN для США и налоговые коды для Италии, IP-номера и другие уникальные идентификаторы
- Применение тех же полей для ключевых отношений
- Общие мобильные платформы маскирования
Механизм классов данных в Data Express предоставляет мощный способ классификации и обеспечивает быстрое внедрение.
Каждое данное поле может быть каталогизировано как член класса данных. Класс идентифицирует группу полей со сходными характеристиками. Определение классов позволяет заказчикам фокусироваться на полях со сходными характеристиками и создавать общие процедуры для согласованного маскирования данных в рамках всех экземпляров данного типа данных независимо от платформы или хранилища данных.
Быстрое определение и создание подмножеств данных обеспечивает ускоренное и более гибкое тестирование
Модуль Data Subset Extraction позволяет организациям извлекать согласованные и конгруэнтные подмножества данных, что снижает объемы данных в среде тестирования. Этот процесс ускоряет выполнение схем контроля качества с последующим изменением приложений за счет создания точного и репрезентативного тестового образца среды приложения. Эта методология включает анализ среды, параметров для множественных определений, каталогизацию файлов и разметки, конструирование словаря данных и определение главной базы данных. Клиентское приложение извлекает информацию из репозитория и определят логическую модель данных и правила для формирования подмножеств. Впоследствии базовый процессор работы с подмножествами применяет правила, которые позволяют ревизовать набор данных для записи в новую базу данных.
Отзывы:
"Центральным вопросом для нас является безопасность, и это решение выглядит имеющим все нам необходимое для того, чтобы сделать наше жизненно важное тестирование системы защищенным и соответствующим регулятивным нормам". Руководитель ИТ-отдела, организация финансового обслуживания
"С помощью этого решения мы смогли удалить все дубликаты и ошибки из нашей среды тестирования. Это позволило нам сберечь терабайты дискового пространства, и сократить до 90% наш общий объем работ по генерации тестов". Руководитель отдела тестирования ведущего итальянского банка.
"Мы смогли завершить работу за недели без компрометации качества или нарушения законодательных норм. Эта технология реально помогла". Директор ИТ-отдела ведущего испанского банка
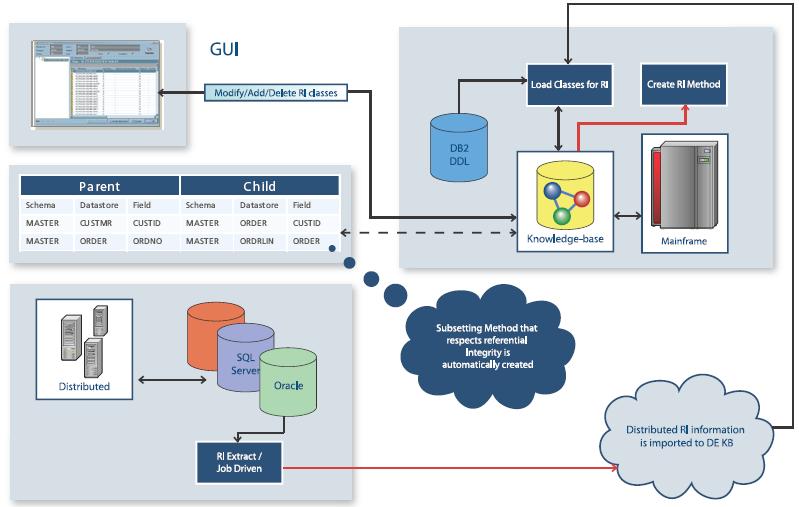
На рисунке: Пользовательский интерфейс. Модификация / Добавление / Удаление RI-классов. Родитель. Схема. Хранилище данных. Поле. MASTER CUSTMR CUSTID. MASTER ORDER ORDNO. Потомок. Схема. Хранилище данных. Поле. MASTER ORDER CUSTID. MASTER ORDRLIN ORDER. Распределенное. SQL Server. Oracle. Извлечение RI / направление заданием. DB2. DDL. Загрузка классов для RI. Создание метода RI. База знаний. Универсальный компьютер. Автоматически создается метод формирования подмножества, учитывающий ссылочную целостность. Распределенная информация RI импортируется в DEKB
Кросс-платформенные сложные подмножества
Возможности процесса Data Subset Extraction:
- Определение множественных правил извлечения, поддерживающих создание различных компактных наборов данных для специфических целей, таких как системное тестирование, модульное тестирование и тестирование производительности
- Многократно повторяемые схемы извлечения дают согласованные результаты
- Мастер правил извлечения для генерации определений сложных шаблонов извлечения, что позволяет формировать подмножества наборов данных в соответствии с множественными критериями
- Автоматизированное извлечение взаимосвязанных записей с использованием тех же самых значений ключей.
Исчерпывающее покрытие операционных систем и платформ хранения данных
Data Express может использоваться как на платформах универсальных компьютеров, так и на других платформах (Windows, UNIX и Linux) для широкого диапазона хранилищ данных.
Data Express для z/OS
Data Express для z/OS позволяет централизованному хранилищу знаний Data Express располагаться в среде IBM Mainframe z/OS, что формирует стратегическую центральную точку формирования подмножеств и маскирования для множественных источников данных и для распределенных данных (через ODBC и расширения Oracle).
- Платформы: IBM eServer System z, работающий под OS/390 2.6 или более старшей версии; или под z/OS 1.1 или более старшей.
- Форматы данных для универсального компьютера: mSequential, GDG, VSAM, DB2, ADABAS, DLI
Поддерживаемые входные форматы:
- Последовательная выгрузка
- Выгрузка DB2 поддерживается в форматах DSNTIAUL, REORG и UNLOAD (утилиты IBM), и в FIXED, EXTERNAL, VARIABLE и CSV (утилиты CA)
- Прямой доступ (для DB2, VSAM, GDG, последовательных файлов)
- Копии образа DB2
Data Express для распределенных систем
Data Express для распределенных систем позволяет центральной базе знаний Data Express располагаться на платформе Windows, что снимает требования по использованию универсального компьютера IBM.
База знаний под Windows дает стратегическую центральную точку для формирования подмножеств и маскирования множественных распределенных источников данных через ODBC и расширения Oracle, которые включены в комплект Data Express для распределенных систем.
Data Express с расширением ODBC
Data Express с расширением ODBC работает как с Data Express для z/OS, так и с Data Express для распределенных систем, что обеспечивает прямой доступ к доступным через ODBC хранилищам данных, располагающихся или доступных из Windows, UNIX и Linux.
• Платформы:
- Windows XP, Windows Vista, Windows Server 2003, Windows Server 2008
- IBM System p под AIX 5.3, 6.1
- Itanium под HP/UX 11i V2, 11i V3
- PA-RISC под HP/UX 11.11, 11i V2, 11i V3
- x86-64 под Red Hat 4.0 Update 1, 5.1 и 5.3
- x86-64 под SuSE Linux ES 10 SP1
- SPARC под Solaris 9, 10
- zSeries под SuSE Linux ES 10
• Форматы данных :
- Хранилища данных, доступные через ODBC, включая Oracle, SQL Server, Sybase, MySQL,DB2 LUW (UDB), Teradata, Ingres, Informix, Progress и другие
- Файлы COBOL ISAM (доступ через Micro Focus XDBC)
- Форматы последовательных данных
Data Express с расширением Oracle
Data Express с расширением Oracle работает как с Data Express для z/OS, так и с Data Express для распределенных систем, что обеспечивает встроенный прямой доступ к хранилищам данных под Oracle, располагающимся или доступным из Windows, UNIX и Linux.
• Платформы:
- Windows XP, Windows Vista, Windows Server 2003, Windows Server 2008
- IBM System p под AIX 5.3, 6.1
- Itanium под HP/UX 11i V2, 11i V3
- PA-RISC под HP/UX 11.11, 11i V2, 11i V3
- x86-64 под Red Hat 4.0 Update 1, 5.1 и 5.3
- x86-64 под SuSE Linux ES 10 SP1
- SPARC под Solaris 9, 10
- zSeries под SuSE Linux ES 10
• Форматы данных:
- Oracle