
В данном техническом описании рассматриваются самые важные и наиболее серьезные факторы, влияющие на производительность приложений IBM Lotus Notes и Domino. Оно предназначено для разработчиков клиентских приложений Notes и поможет им максимально повысить производительность, идентифицируя проблемные области и предлагая решения.
Предполагается, что вы уже знаете, как создавать элементы дизайна Notes и как настраивать параметры форм, полей, представлений, столбцов и т.д. Здесь представлен материал для разработчиков любой квалификации.
Простые приложения в Lotus Notes разрабатывать легко, и если пользователей и документов в приложении не слишком много, у вас вряд ли возникнут какие-либо проблемы с производительностью. Однако если приложение окажется удачным, в нем может накопиться много данных и образоваться масса пользователей. Если приложение было спроектировано без учета вопросов производительности, оно будет работать медленно.
В данном техническом описании рассматриваются основные факторы, влияющие на производительность приложений Notes/Domino, и объясняется, что вы, как разработчик, можете сделать для максимизации производительности. Это руководство не является исчерпывающим; в нем уделяется внимание наиболее типичным и наиболее серьезным проблемам проектирования.
Цель данного описания - помочь определить проблемные области и указать решения проблем, главным образом для клиентских приложений Notes. Web-приложения имеют во многом аналогичные проблемы проектирования, но у них есть дополнительные возможности и решения для повышения производительности, рассматриваемые в "Приложении Group C" , документа IBM Redbooks "Обсуждение вопросов производительности для приложений Domino" (EN) и в документе для бизнес-партнеров IBM "Проектирование производительных приложений Notes/Domino" (EN).
На общую производительность приложений наибольшее влияние оказывают следующие факторы:
- Количество и сложность представлений (views). Удаляйте неиспользуемые представления или объединяйте похожие представления. Там, где возможно, используйте повторно сортируемый столбец для комбинирования представлений, содержащих одинаковые документы и отличающихся только порядком сортировки. Удалите необязательные столбцы и упростите формулы выбора и формулы столбцов в представлениях. Проверьте "server private" и другие представления, к которым, возможно, не имеете доступа.
- Использование @Today и @Now в формулах выбора или формулах столбцов. По возможности избегайте их. Просмотрите на Web-сайте службы поддержки IBM Techdoc статью "Представления с применением даты/времени в Notes: какие есть варианты?" (EN); также просмотрите раздел "Представления" данной статьи.
- Количество документов. Чем больше количество документов, тем медленнее открываются представления. Подумайте об архивировании старых документов или комбинировании документов "main and response" (основной и зависимый) в один документ. Например, если основным документом является заказ, возможно, будет неудачным решением создание отдельного документа для каждой позиции заказа. Lotus Notes - это не реляционная, а документо-ориентированная база данных.
- Количество итоговых полей, хранящееся в документах. Каждое поле, не являющееся форматированным текстом, называется "итоговым" ("summary") полем (хотя это чрезмерное упрощение). Индексация в представлениях документов с большим количеством итоговых полей происходит дольше (до 30% при наличии сотен полей). Это так, даже если поля в представлениях не используются. Иногда при использовании меньшего количества документов требуется больше полей и наоборот; правильный выбор для оптимальной производительности требует размышлений.
- Сложность форм. Попытайтесь ограничить формы таким количеством полей, которое действительно необходимо. Длинные формы открываются, обновляются и сохраняются значительно дольше (учитывая также большее количество полей, с которыми должна иметь дело система индексации представлений).
- Изменение документов. Изменение документов иногда замедляет индексацию представления, дополнительно нагружая механизм индексации, а также замедляет репликацию и полнотекстовую индексацию.
- Количество удаленных документов. При удалении документа он помечается маркером, называемым "остатком от удаления" (deletion stub). Он нужен для программы репликации, которая решает, удалять этот документ из другой реплики (replica) или копировать "отсутствующий" документ в эту реплику. "Остатки от удаления" со временем устаревают (по умолчанию через 90-120 суток), поэтому для базы данных с обычным числом удалений накапливается не то количество подобных документов, которое может вызвать проблемы.
Однако мы встречали приложения, содержащие намного больше остатков от удаления, чем документов. Обычно это происходит при работе агентского приложения, выполняющегося в ночное время, которое удаляет каждый документ и затем создает все новые документы из некоторого внешнего источника данных. Не делайте этого. Есть более эффективный алгоритм, сравнивающий документы с источником данных и определяющий, какие из них нужно обновить или удалить. Более подробная информация по этой теме приведена на странице Lotus Sandbox download (EN).
- Поля-считыватели. Если нужно использовать поля Reader, заменить их нечем - нет других способов получить необходимый уровень защиты. Но помните о влиянии на производительность в представлениях, особенно если пользователь имеет доступ только к небольшому подмножеству большого количества документов. В разделе "Представления" данной статьи приведены некоторые советы по минимизации данного влияния. Дополнительная информация содержится также в статье developerWorks "Производительность приложений Lotus Notes/Domino 7, часть 2. Оптимизация представлений базы данных" (EN).
- Количество пользователей. Большое количество пользователей на сервере снижает производительность приложения (и сервера). А если приложение уже имеет ограниченную производительность, добавление новых пользователей еще больше ухудшает положение. На помощь может прийти корректировка дизайна приложения, но можно также создать копии на других серверах, особенно кластерных, или поощрять использование пользователями локальных реплик, которые работают намного быстрее.
3. Производительность на уровне базы данных
Список параметров, которые можно использовать для настройки производительности базы данных, приведен в справочном документе Domino Designer "Свойства, повышающие производительность базы данных". В большинстве случаев эти параметры повышают производительность за счет функциональности; другими словами, если вам не нужна какая-либо функциональность для конкретного приложения, отключите ее.
Наиболее заметный эффект имеют следующие параметры:
- Don't maintain unread marks (Не поддерживать метки непрочитанных документов).
- Don't maintain the "Accessed (In this file)" document property (Не поддерживать свойство документов "Было обращение (в этот файл)"). При этом вы не сможете узнать, когда документ был прочитан последний раз. Эта информация удобна для архивирования документов, которые долго не читались.
- Disable specialized response hierarchy information (Запретить специализированную информацию по иерархии ответа). При этом вы не сможете использовать свойства NotesDocument.Responses, @AllDescendants или @AllResponses, которые иногда полезны в формулах выбора и формулах репликации.
- Disable transaction logging (Запретить регистрацию транзакций). Эффект этого параметра зависит от того, как администратор настроил сервер, а также от количества пользователей. Если есть много пользователей, использование регистрации транзакций может ускорить работу. Попробуйте и проанализируйте оба способа. Журналы регистрации транзакций используются для восстановления после сбоев.
- Optimize Document Table Map (Оптимизировать карту таблиц документа). Наиболее полезен в ситуациях, когда приложение содержит примерно равное число документов различного типа, и большинство представлений отображает только один тип (например, SELECT Form = "xyz" & ...). Если формула выбора записана именно таким образом (с предварительным тестированием формы), индексация представления работает быстрее, потому что она сразу же может не учитывать все документы, не использующие эту форму.
Использование NSFDB2 (сохранение Domino-данных в базе данных DB2) не способствует повышению производительности и обычно немного медленнее, чем традиционный NSF-файл. Цель NSFDB2 - дополнительная функциональность, а не повышение производительности.
Полнотекстовый индекс может потребовать много места на диске, но обычно это себя оправдывает. Операции поиска в агентских приложениях выполняются быстрее, и при отсутствии такого индекса пользователи вынуждены применять более медленные методы поиска, нагружающие сервер и выдающие результаты существенно позднее.
Примечание. Новое свойство базы данных в Notes версии 8.0 позволяет отключить "полнотекстовый" поиск в базе данных, если она не имеет полнотекстового индекса. Обычно это неплохая идея, даже если полнотекстовый индекс имеется; таким образом гарантируется, что при случайном удалении индекса пользователи увидят сообщение, а не просто неожиданное ухудшение производительности без объяснений.
Еще одно действие, которое можно выполнить на уровне базы данных, находится не в диалоговом окне свойств, а в диалоговом окне ACL. Ограничение доступа пользователей для создания персональных представлений и папок уменьшает нагрузку на север (см. рисунок 1).
Рисунок 1. Диалоговое окно ACL
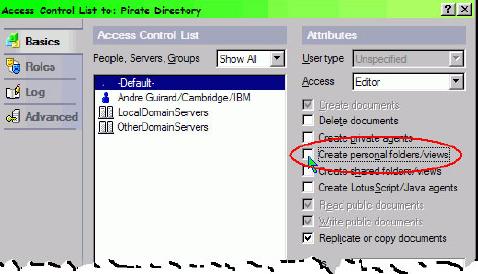
Если снять отметку с флажка "Create personal folders/views box", пользователи все равно смогут создавать рабочие индивидуальные (desktop private) представления, но они будут храниться локально, а не на сервере, поэтому не будут сильно влиять на производительность приложения.
Рабочие индивидуальные представления влияют на производительность, потому что для их индексации пользователи должны получать данные с сервера в режиме реального времени. Поэтому интенсивное применение рабочих индивидуальных представлений тоже может препятствовать работе сервера. По этой причине избегайте автоматического создания индивидуальных представлений для пользователя с настройкой "Private on first use" (индивидуальное при первом использовании). (Более подробно об этом ниже.)
Большинство функций @Functions работает довольно быстро, но есть несколько, которые вычисляются дольше. Помните о них и используйте благоразумно:
- @Contains - не очень затратная по ресурсам функция, но она часто используется для проверки наличия в списке точного значения, что является как неэффективным, так и некорректным. Например, выражение @Contains(Cities; "Lansing") возвращает значение True, если список городов Cities содержит значение "East Lansing". Если это то, что вам нужно, хорошо; но если вы на самом деле ищете записи, содержащие точное значение "Lansing", используйте вместо нее следующие функции: =, *= или @IsMember. Они работают быстрее, потому что не требуют сканирования всей строки при несовпадении первых символов.
- @For и @While часто можно заменить более эффективной функцией @Transform или другими функциями, работающими одновременно со всем списком.
- @Unique - поскольку данная функция должна сравнивать каждое значение в списке со всеми другими, время ее выполнения прямо пропорционально квадрату числа элементов в списке. Лучше было бы извлечь список, значения которого уже являются уникальными. Более подробно об этом ниже.
- @NameLookup аналогична @DbLookup, но только для информации в каталогах.
- @DbLookup, @DbColumn - чрезмерное и неправильное использование этих функций является причиной большинства задержек в работе форм. Дополнительная информация приведена в соответствующем разделе (ниже).
Функции организации циклов на макроязыке часто используются чрезмерно. Хотя в справочных документах Domino Designer это не отмечено , почти все макрофункции, принимающие строковые аргументы, могут также работать со списком. Например, функция @Left(x; ","), в которой x - это список, возвращает список, к каждому элементу которого применена функция @Left.
Примечание. Раньше функции @UserRoles и @UserNamesList сильно снижали производительность, но, начиная с версии Lotus Notes 6.0, результаты работы этих функций кэшируются.
Три главных фактора, оказывающих влияние на производительность @DbLookup и @DbColumn:
- используется ли кэш.
- является ли эффективным искомое представление.
- используются ли они слишком часто.
Многие разработчики слишком часто используют параметр "NoCache", особенно в формулах с ключевым словом. Легко увидеть, как это может случиться, поскольку во время разработки и первоначального тестирования ключевые слова часто изменяются, и параметр NoCache "заставляет их работать правильно".
Однако при нормальном использовании ключевые слова в приложении обычно не меняются ежедневно. Некоторая задержка доступности новых значений для пользователей является приемлемым компромиссом для улучшения производительности. Используйте NoCache только в случае реальной необходимости.
Есть три варианта кэширования:
- "Cache" (по умолчанию) - обращение к представлению осуществляется только в первый раз, когда выполняется операция поиска (lookup) во время сеанса работы приложения, и результаты этой операции запоминаются для последующего использования до завершения приложения.
- "NoCache" - кэш не используется, и обращение всегда происходит к представлению. Если для данной операции поиска имеется кэшированное значение, оно не обновляется.
- "ReCache" - забытый вариант, обращение всегда происходит к представлению, но кэш обновляется значением операции поиска. Используя ReCache, можно преднамеренно обновить кэш в определенное время, например когда сохраняется документ, к которому происходит обращение при поиске. В остальных случаях можно использовать кэшированное значение, поскольку известно, что это значение является обновленной информацией, введенной пользователем.
4.1.2. Выбор корректного представления для операции поиска
Иногда довольно эффективное представление все-таки не является наилучшим вариантом для функций @Db. Например, @Unique(@DbColumn("":"NoCache"; "":""; "InvoicesByCompany"; 1)) имеет несколько проблем:
- Она использует NoCache, когда, по всей вероятности, в этом нет необходимости. Вы не добавляете компанию каждый день, а когда делаете это, можете использовать вариант "ReCache" в форме Postsave of the Invoice, для того чтобы сделать новое название доступным сразу же.
- Текущая база данных указана с выражением "":"". Вместо этого используйте "", поскольку "":"" имеет не только запутывающую пунктуацию, но также медленнее вычисляется.
- Не выполняйте операцию поиска списка, содержащего дублированные значения, с последующим использованием @Unique для удаления дубликатов. Вместо этого выполняйте операцию поиска для просмотра столбца уже с уникальными значениями, поскольку они происходят из категоризированного столбца.
Последний момент особенно важен, поскольку операция поиска для столбца, прекрасно работающая с сотней документов тестовых данных, может быстро стать неэффективной, как только вы начнете использовать приложение на практике с тысячей документов. Особенно это проявляется в тех случаях, когда приложение используется на сервере - передача полного содержимого столбца представления по сети на рабочие станции пользователя занимает время. Чтение уже уникальных значений из представления выполняется значительно быстрее.
Примечание. Параметр "Generate unique keys in index" (генерировать уникальные ключи в индексе) может рассматриваться как альтернатива категоризированным столбцам для получения списка уникальных значений, но он имеет отрицательную сторону, делающую его непригодным для такого использования.
Также плохой идеей является операция поиска для долго индексирующегося представления и особенно для представления, использующего @Today или @Now в своей формуле выборки или формуле столбца. Если вам нужно найти только документы с конкретной датой, то вместо использования @DbColumn для представления, содержащего только такие документы, используйте @DbLookup для представления, содержащего все документы, отсортированные по дате, и предоставьте дату в качестве ключа просмотра.
4.1.3. Избегайте повторяющихся операций поиска
Функции @Db могут использоваться по разным причинам. Вот наиболее распространенные:
Повторение в формуле
@If(@IsError(@DbLookup("": "NoCache"; ""; "SomeView"; CustID; 3);
"";
@DbLookup("": "NoCache"; ""; "SomeView"; CustID; 3)) |
Эта формула не только использует NoCache там, где это необязательно, но и выполняет просмотр дважды там, где нужно делать это только один раз. Вот две альтернативы:
_tmp := @DbLookup(""; ""; "SomeView"; CustID; 3);
@If(@IsError(_tmp); ""; _tmp) |
или
@DbLookup(""; ""; "SomeView"; CustID; 3; [FailSilent]) |
Излишний поиск ключевого слова в режиме чтения
Когда документ открывается для просмотра, для некоторых типов полей с ключевыми словами, клиентское приложение Notes не нуждается в знании списка вариантов. Очевидными исключениями являются поля флажков и зависимых кнопок, в которых все варианты отображаются даже в режиме чтения, и все поля, использующие синонимы ключевых слов ("Display text/value"), поскольку документ хранит только "значение", а форма должна знать, что отображать в "Display text".
В других ситуациях, тем не менее, записывайте формулы ключевых слов так, чтобы отложить поиск до реальной потребности в списке вариантов:
_t := @If(@IsDocBeingEdited; @DbColumn(""; ""; "Customers"; 1);
@Return(@Unavailable));
@If(@IsError(_t); ""; _t) |
Возвращая @Unavailable в режиме чтения, формула указывает форме выполнить запрос снова, если ей в последующем потребуется список вариантов. Это происходит в том случае, когда пользователь переходит в режим редактирования и курсор попадает в это поле.
Поэтому не только избегайте выполнения операций поиска, когда пользователь всего лишь просматривает документ, но также рассредоточивайте задержку по процессу редактирования документа; восемь полусекундных задержек менее раздражают, чем одна четырехсекундная. И если пользователь не помещает курсор в это поле, он вообще не должен ждать завершения операции поиска.
Несколько операций поиска там, где можно использовать одну
Предположим, что имеется идентификатор клиента CustID, хранящийся в документе "invoice" (счет), и вы хотите использовать этот идентификатор для поиска и отображения имен клиентов, их адресов и имен покупателей для контактов. В вашей форме есть несколько полей Computed for Display (вычисляемое для отображения), каждое из которых содержит формулу, использующую функцию @DbLookup(""; ""; "CompanyByID"; CustID; x), где x - это номер столбца или имя поля.
Лучше иметь один столбец, содержащий все необходимые значения, которые затем можно извлекать для получения значений индивидуальных полей, т.е. формула столбца может выглядеть так:
CustName : StreetAddress : (City + " " + State + " " + Zip) : PurchasingContact |
В форме добавьте одно скрытое поле Computed for Display под названием CustDetails:
@DbLookup(""; ""; "CompanyByID"; CustID; 4) |
(предполагается, что комбинированным столбцом является столбец 4). Затем можно было бы использовать эту формулу для отображения имени:
CustDetails[1] |
и т.д.
Повтор операций поиска при обновлении
Предположим, что вам нужно подставить имя менеджера клиента в вычисляемое поле при составлении формы, например:
@DbLookup(""; "VOLE1": "EmpData.nsf"; "EmpByName"; @Name([CN]; @Username);
"Manager") |
Вычисляемые поля пересчитываются при каждом обновлении формы. Многие формы обновляются часто (поскольку разрешен параметр обновления полей при изменении поля ключевого слова), поэтому здесь может скрываться причина существенного снижения производительности. Более удачным вариантом было бы использование поля "Computed when Composed" (вычисляется при составлении).
Если поле в документе сохранять не нужно (помните о том, что сохраняемые поля - store fields - сохранять не нужно!), можно определить их как Computed for Display (вычисляемые для отображения), но в этом случае выполните следующее, для того чтобы исключить повторения операций поиска при обновлениях:
@If(@IsDocBeingLoaded;
@DbLookup(""; "VOLE1": "EmpData.nsf"; "EmpByName"; @Name([CN];
@Username); "Manager");
@ThisValue) |
Назначение последовательных номеров при помощи @DbColumn
Это часто встречающаяся ошибка. Когда разработчикам нужно создать уникальный идентификатор для каждого документа, они часто делают это путем добавления "1" к номеру последнего существующего документа, т.е. используют примерно такую формулу:
tmp := @DbColumn("":"NoCache"; ""; "RequestsByNumber"; 1);
nextNumber := @If(tmp = ""; 1; @ToNumber(@Subset(tmp; -1)) + 1);
@Right("000000" + @Text(nextNumber); 7) |
Это действительно плохой прием. По мере роста числа документов функция @DbColumn выполняется все дольше и дольше. Кроме того, она на самом деле не гарантирует уникальности идентификаторов при работе с приложением нескольких пользователей, особенно если имеется несколько реплик.
При сохранении номера, назначенного документу, он не будет доступен до завершения этой операции, что неудобно. Поскольку он назначается при формировании документа, создание и сохранение документа с таким же номером кем-нибудь еще займет много времени.
Следует пересмотреть ваши требования. Люди часто хотят использовать последовательную нумерацию там, где для приложения на самом деле нужен только уникальный идентификатор, который не обязательно должен быть числовым. Взгляните на функцию @Unique, которая генерирует довольно короткое значение, почти определенно являющееся уникальным (уникальность можно гарантировать путем выполнения дополнительных действий, например назначения каждому пользователю уникального "суффикса", для чего часто используются их инициалы).
Если вы решите, что последовательная нумерация действительно необходима, прочтите статью developerWorks "Генерирование последовательных чисел в реплицируемых приложениях", в которой рассматривается один из методов ее эффективной реализации. Дополнительная информация по этой теме будет приведена в готовящейся статье developerWorks.
В данном разделе мы рассмотрим некоторые типичные проблемы, о которых стоит упомянуть.
5.1. Не используйте вычисляемые поля, если работает Computed for Display
Поскольку сохранение полей замедляет работу приложения, имеет смысл избегать сохранения значений, если их можно легко вычислять при необходимости. Здесь имеет место компромисс - вычисляемое поле не пересчитывается при открытии документа в режиме чтения, поэтому, если формула является медленной, лучше сохранять ее для улучшения производительности в режиме чтения (с другой стороны, это означает также, что поле может быть устаревшим).
Но безусловно никогда не применяйте вычисляемое поле, которое просто повторно отображает значение другого поля - в этом случае будут сохраняться две копии одной и той же информации.
Самой типичной причиной наличия большого количества полей в одной форме является отображение таблицы с несколькими строками и столбцами, а также с полем в каждой ячейке таблицы. Это трудная ситуация, поскольку данный способ является самым простым для реализации такой функциональности.
Однако имеются альтернативные способы работы с таблицами значений. Самый очевидный способ - поместить таблицу в поле с форматированным текстом (rich text field) и разрешить пользователям вводить все, что они пожелают (используйте @GetProfileField в формуле поля с форматированным текстом по умолчанию для чтения "начальной" таблицы из документа profile). Отрицательным моментом является то, что пользователи не могут получить подсказки при заполнении ячеек, которые можно было бы реализовать при помощи списков ключевых слов, преобразований и проверок корректности вводимых значений в отдельных полях. Но иногда это допустимая альтернатива.
Имеется также несколько доступных средств и методик редактирования таблиц по одной строке в диалоговом окне и отображения результатов в таблице. Например, примеры Domino Design Library в Lotus Sandbox содержат набор элементов проектирования, которые можно использовать для редактирования и отображения данных в таблицах, не реализуя поле для каждой ячейки. Подробно эта система описана в документе "Table Editor" базы данных по документации. Ее реализация занимает некоторое время, но производительность впечатляет.
Иногда встречаются формы, содержащие много полей, остающихся пустыми в большинстве документов. Например, 5% документов нуждаются в разделе "regulatory approval" (официальное разрешение), содержащем 50 полей. В остальных 95% документах это место будет расходоваться зря, а производительность снижаться из-за сохранения всех этих пустых полей.
В этом случае лучше было бы иметь две различные формы - главную с полями, нужными всегда, и отдельную форму "Regulatory Approval", связанную с оригинальным документом и создаваемую только по необходимости. Это именно тот случай, когда лучше иметь несколько дополнительных документов, чтобы исключить большое количество дополнительных полей.
Помните о многозначных полях. Вместо применения пяти полей, позволяющих пользователю вводить пять отдельных значений, используйте одно поле, позволяющее вводить несколько значений. Нет ограничения на количество элементов (если вы не выбрали применить его), а получаемые значения намного легче использовать в представлениях и формулах.
Примечание. Если приложение уже работает медленно из-за слишком большого количества полей, редактирование элементов проектирования поодиночке не даст большого прироста скорости; нужно написать агенты для просмотра всех существующих документов и удаления дополнительных элементов, уже присутствующих в них. Для упрощения этой процедуры доступны продукты бизнес-партнеров. Однако если ваше изменение является серьезной реорганизацией, такие агенты могут быть довольно сложными. Вы сэкономите время, если предусмотрите все заранее и будете делать все правильно с самого начала.
Некоторые формы перегружены графическими элементами и используют большие побитные изображения для фонового рисунка и большое количество декоративных штучек. Загрузка больших изображений отнимает время и память кэша элементов формы. Время также расходуется на их прорисовку при просмотре формы. Некоторая осторожность при создании форм может привести к профессиональному внешнему виду без существенного снижения производительности. Вот некоторые советы:
- Никогда не вставляйте изображение в форму; вместо этого используйте либо элемент проектирования image resource, либо импортируйте изображение. Если планируется использование одного и того же изображения в нескольких формах, имеет смысл применять image resource, поскольку он позволяет кэшировать изображение в клиентском приложении отдельно от дизайна формы. Даже если вы не планируете использовать одно и то же изображение в нескольких формах, все равно неплохо оформлять его в виде image resource (источник изображения), поскольку никогда нет уверенности в том, что кто-то в дальнейшем не создаст еще одну форму с этим же изображением.
- Никогда не уменьшайте масштаб изображения до желаемых размеров после помещения его в форму. Используйте графический редактор (например GIMP) для масштабирования оригинального изображения до требуемых размеров, даже если это означает наличие нескольких источников одного и того же изображения с разными размерами.
Если изображение имеет формат JPEG, попробуйте другие настройки сжатия для уменьшения размера файла. JPEG-сжатие - это сжатие с потерей информации, поэтому сжатое изображение не будет идентично оригиналу. Но если вы сожмете его насколько можно сильнее без потери визуального качества, ваша форма будет загружаться быстрее. Имеются коммерческие инструментальные средства, помогающие определить этот баланс.
- Используйте корректный формат файлов для изображений. Если изображение использует ограниченную палитру цветов (как большинство логотипов), формат GIF обычно будет формировать файл меньшего размера. Если это полноцветная фотография или рисунок, JPEG обычно подходит лучше всего. Никогда не используйте BMP-файлы, поскольку они обычно вообще не сжаты.
- Прорисовка фона ячеек таблицы и графических ячеек занимает некоторое время. Скрытые границы ячеек визуализируются быстрее, чем видимые, особенно границы с 3D-эффектом. Таблицы со слитыми ячейками визуализируются быстрее, чем таблицы, вложенные внутрь других таблиц.
Не используйте сохраняемые формы. Просто не используйте.
5.5. Автоматически обновляемые поля
Параметр формы "Automatically refresh fields" (автоматически обновлять поля) должен использоваться редко. Он приводит к довольно частому обновлению формы во время редактирования, вызывая задержки при перерасчете вычисляемых полей и формул входного преобразования. Обычно лучше использовать параметр уровня поля "Refresh on keyword change" (обновлять при изменении ключевого слова) либо события поля Onchange или Onblur для выполнения обновления только при необходимости.
5.6. Излишнее количество общих элементов дизайна
Формы могут черпать информацию из других элементов дизайна, например источников изображений, общих полей, общих действий, подформ, иерархических структур, таблиц стилей, библиотек сценариев. Вполне возможно, что открытие одного документа вызовет чтение информации из дюжины элементов дизайна, помимо формы, что занимает некоторое время. Преимущество общих элементов дизайна состоит в том, что они облегчают обслуживание приложения. Недостаток - доступ к нескольким источникам во время загрузки выполняется дольше.
Lotus Notes поддерживает кэш информации о дизайне, поэтому ее не нужно читать из оригинальных элементов дизайна каждый раз, однако время начальной загрузки может быть проблемой. Кэширование означает также, что использование общих элементов дизайна может повысить производительность, если одна и та же подформа или изображение используются во многих других формах.
Общие действия не сказываются отрицательно на производительности, поскольку есть только одно замечание по дизайну, касающееся общих действий, т.е. вы можете включить несколько по цене одного. Общие столбцы представления не влияют на производительность.
Из-за преимуществ в обслуживании, рекомендуется снимать элементы дизайна с общего использования только после выполнения других действий, после которых производительность все равно осталась неприемлемой.
Неэффективные и ненужные представления могут приводить к задержкам по следующим причинам:
- время, требующееся на обновление индекса при открытии представления.
- время, требующееся на извлечение информации при использовании представления в функции @Db.
- периодическая проверка на сервере заданием Update каждого представления для определения необходимости обновления информации из недавно измененных документов. Следовательно, большее количество представлений (или большее количество сложных представлений) связывает сервер и замедляет все приложения.
Еще одной причиной медленного открытия представлений является большое количество документов в базе данных. При открытии представления Lotus Notes проверяет наличие каких-либо документов, измененных после времени последнего обновления индекса представления. Чем больше документов имеется, тем большее время занимает эта проверка, даже если возвращенным ответом будет "нет".
6.1. Функции @Now или @Today в представлениях
Много было написано о том, как реализовать представления, основанные на дате/времени, без использования @Today или @Now. Одним из примеров является статья на Web-сайте службы поддержки IBM Techdoc "Представления с применением даты/времени в Notes: какие есть варианты?", в которой рассмотрены альтернативные способы создания таких представлений.
Давайте обсудим несколько дополнительных моментов. Во-первых, часто повторяемый совет об использовании @TextToTime("Today") является неполным. Само по себе это работает только в начале. Необходимо выполнить дополнительную работу для корректного поведения этой функции.
Почему? Обычно при открытии представления Lotus Notes просматривает "индекс представления" (view index), отсортированный список документов и значений строк в представлении, и проверяет только документы, созданные или измененные после времени последнего обновления индекса. Это делается для того, чтобы определить, нужно ли их добавить или удалить из представления, либо пересчитать значения столбцов. Если такие документы отсутствуют, процесс выполняется очень быстро.
Однако если используется @Today, старый индекс представления больше не будет полезен. Например, предположим, что имеется следующая формула выбора:
SELECT Status = "Processing" & DueDate <= @Today |
Документы могут добавляться в это представление, даже если они не изменились , поскольку изменилось значение @Today после последнего использования представления. Поэтому при каждом использовании этого представления Lotus Notes отменяет старый индекс и ищет все документы в базе данных , для того чтобы определить, принадлежат ли они этому представлению, а также для пересчета значений столбцов.
При использовании @TextToTime("Today") вместо @Today можно "перехитрить" механизм индексации представления. Примите наши поздравления. Lotus Notes будет повторно использовать старый индекс и проверять только измененные документы. Это увеличивает скорость, но, к сожалению, приводит к некорректным результатам, поскольку при изменениях @Today необходимо опять просмотреть все документы.
Предположим, что имеется столбец, отображающий красный восклицательный знак, если документ "запроса" все еще остается открытым после истечения трех часов (тестирование и сравнение с @Now). Такая ситуация может произойти, даже если представление использовалось пять секунд тому назад. Хотя с @Today хорошо было бы просто обновлять индекс представления не так часто.
Можно действительно делать это, используя параметры индексации представления в окне Property представления. В закладке Advanced options можно указать, что данное представление обновляется "Auto, at most every x hours" (автоматически, не чаще одного раза в x часов), где x - это указанное вами число. Преимущество заключается в очень быстром открытии представления. Недостаток - представление не сразу отображает изменения даже для измененных документов. Пользователь должен вручную обновлять представление, чтобы увидеть последние данные.
Другим популярным альтернативным способом является создание запланированного агента (scheduled agent), выполняющегося еженощно и обновляющего формулу выбора представления (используя метод NotesView.SelectionFormula), для того чтобы она содержала формулу выбора дня. Например, такой агент может содержать выражение:
view.SelectionFormula = {SELECT Status="Processing" & DueDate=[} & Today & {]} |
Но этот способ имеет некоторые недостатки:
- Изменение дизайна представления должно быть реплицировано везде, чтобы все реплики показывали корректные документы.
- Администраторы серверов могут подозрительно относиться к агентам, меняющим дизайн рабочего приложения.
- Первый пользователь, открывающий представление следующим утром, все равно должен ждать завершения индексирования представления. Можно избежать этого, установив параметр индексации представления в значение "Automatic" или предоставив возможность агенту обновить представление.
- Если база данных берет свой дизайн из шаблона, ваше представление будет перезаписываться из данного шаблона. Во избежание этого можно либо осуществлять выполнение агента после еженощного обновления дизайна, либо изменить шаблон.
Еще одним решением является использование пользовательского интерфейса. Например, вместо представления "открыть просроченные запросы", можно было бы использовать представление "открыть запросы по сроку выполнения", для того чтобы просроченные запросы шли первыми в представлении. Их легко можно найти, а представление открывается значительно быстрее.
В некоторых случаях уместно использовать папку для отображения группы документов, категоризированных по дате. Еженощный агент может заполнять папку документами, соответствующими этой дате, а параметры доступа к этой папке могут запрещать ручное изменение пользователем ее содержимого. Это неудачный выбор, если содержимое папки должно меняться на протяжении дня при редактировании документов (можно также справиться с этим, используя специальное кодирование, хотя оно является несколько громоздким).
6.2. Необязательные представления
Многие приложения работают медленно по причине наличия большого количества представлений. Удаление любого необязательного представления принесет пользу. Это отразится на производительности сервера, а не конкретного приложения.
Примечание. Проектировщик базы данных не обязательно имеет доступ для просмотра всех представлений. Пользовательские представления "Server private" и другие представления со списком читателей, в который не входит разработчик, являются невидимыми, но они все равно влияют на производительность. Администратор сервера может увидеть эти представления, используя режим "Full access administration".
Настройки обновления представлений по умолчанию (Auto after first use, Discard index after 45 days - автоматическое при первом использовании, сброс индекса после 45 дней) означают, что индексы представлений, которые не использовались 45 дней, сбрасываются и больше автоматически не обновляются сервером. При этом их влияние на производительность минимально. Однако наличие представлений в иерархическом списке означает, что вероятно кто-то будет иногда использовать их непреднамеренно, выполняя поиск подходящего.
Следовательно, можно не только улучшить производительность, но также обеспечить набор представлений, который будет меньше обескураживать пользователей (и который ограничен только необходимыми вариантами выбора, предназначенными для конкретных задач), и назвать их таким образом, чтобы пользователи определяли подходящий им без серьезного поиска.
Часто представления создаются для специального одноразового использования, и не существует процесса для регистрации того, кто запрашивает их, кто использует и когда их можно безопасно удалить. Часто они являются представлениями "Server private", видимыми только человеку, создавшему их, но все равно влияют на производительность (если нужно увидеть эти представления, администратор сервера может использовать режим "Full access administration").
Мы рекомендуем использовать поле Comment (комментарий) представления для описания задачи, для которой оно было создано, пользователей, которые используют его, даты "устаревания", после которой его можно удалить. Тогда, если возникнет вопрос о необходимости какого-либо представления, будет хотя бы известно, кому его задать. Если вы хотите удалить представление и посмотреть, будет ли кто-то протестовать, переместите его в другую базу данных, не содержащую документов, просто для того, чтобы иметь резервную копию, которую при необходимости можно будет восстановить в основной базе данных.
Часто приложение содержит представления, которые отличаются только сортировкой. Такие представления следует комбинировать в одно, содержащее столбцы, которые можно пересортировать. Хотя затраты на добавление такого типа столбца велики, они все равно меньше затрат, связанных с наличием второго отдельного представления.
Это особенно справедливо при использовании нового параметра столбца в Lotus Notes 8.0 "Defer index creation until first use" (отложить создание индекса до первого использования). Данный параметр откладывает создание индекса для столбца с пересортировкой до тех пор, пока пользователь не запросит его. Это приведет к появлению продолжительной задержки для первого пользователя, но если больше запросов не будет, все будут радоваться повышенной производительности.
6.3. Индивидуальные представления
Когда вы будете искать ненужные представления, помните о том, что как разработчик вы можете не увидеть все представления в приложении. Если пользователь имеет индивидуальные представления (private views), сохраненные на сервере, или если имеются общие представления (shared views) со списком доступа, в который вы не входите, вы не сможете увидеть такие представления в Designer, хотя они все равно влияют на производительность. Администратор сервера может обойти проверки прав доступа, используя режим "Full access administration", и предоставить список всех таких представлений (и удалить любое, которое вы пожелаете).
6.4. Необязательные пересортировки
Поскольку сервер должен выполнять дополнительную работу, для того чтобы сделать альтернативную сортировку немедленно доступной по запросу, следует разрешать пересортировку только в том случае, когда она действительно полезна. Сортировки по убыванию и возрастанию считаются двумя отдельными пересортировками, поэтому не разрешайте их обе, если они на самом деле не нужны. В Lotus Notes 8.0, если вы не уверены в том, будет ли использоваться пересортировка, разрешите параметр "Defer index creation until first use" для такого столбца.
Отметим, что у вас есть также вариант перемещения пользователя к другому представлению по щелчку левой кнопкой мыши в заголовке столбца. Это представление уже отсортировано по этому столбцу, следовательно, вы можете предоставить удобную пересортировку без дополнительных усилий (если другое представление уже существует).
Заманчиво создать столбец для каждого поля, но не делайте этого. Ограничивайте информацию в представлении той, которая действительно нужна пользователю; экран будет менее загроможден, а все приложение будет работать быстрее и использовать меньший объем памяти.
Если формула столбца представления или формула выбора использует циклические функции (@For, @While, @Transform) или имеет длину больше, чем, например, 200 символов, не считая комментариев, попробуйте упростить ее. Если это сделать невозможно, подумайте о перемещении формулы в вычисляемое поле в форме, для того чтобы представление могло обращаться только к имени поля. Это особенно полезно для формул, использующихся в нескольких представлениях.
Даже если вы не выбираете использование вычисляемых полей, большинство длинных формул можно упростить, немного подумав. Рассмотрите вариант использования функции @Select или @Replace вместо длинных выражений @If и пересмотрите логику работы для возможного упрощения проверок посредством изменения порядка их выполнения.
Будьте осторожны с операторами и @Functions, работающими со всеми членами в списке. Нет необходимости писать цикл для многих простых манипуляций со строковыми списками; например, для получения первых трех символов каждого элемента используйте функцию @Left( listfieldname ; 3).
Также имеются "комбинаторные" операторы, такие как *=, которые можно использовать для сравнения всех комбинаций элементов из двух списков и которые помогут написать более лаконичные формулы.
Если вы программировали на других языках, возможно, вам знакомы логические операторы, вычисляющие только те выражения, которые необходимы для определения значения логического умножения. Например, выражение
Form = "Report" & ( Sections = "Financials" / Total > 10000) |
сначала проверяет, является ли форма отчетом, и только при истинности этого утверждения проверяет остальную часть выражения. В макроязыках (и в LotusScript) логические операторы так не работают. Всегда вычисляются обе части выражения. Поэтому, если вычисление второй части требует больших затрат, возможно лучше будет выполнить свою собственную формулу с "ленивой логикой" следующим образом:
@If(Form = "Report"; Sections = "Financials" / Total > 10000; @False) |
Функция @If выполняется дольше, чем оператор &, но если можно использовать ее, чтобы избежать ненужного вычисления каких-либо затратных функций, вы выиграете в конечном итоге.
6.7. Злоупотребление множественной категоризацией
Категории - это прекрасные элементы. Они могут разрешить указывать документ под несколькими заголовками в одном и том же представлении, что весьма полезно. Но не переусердствуйте, поскольку перечисление документа в представлении дважды замедляет представление примерно в два раза. Если каждый документ находится в пятидесяти категориях (и если это число умножить на количество документов), бедный сервер должен будет вычислять и сохранять слишком много строк.
Даже если вы не используете несколько категорий, категоризированные представления работают медленнее, чем соответствующие им представления с простой сортировкой. Время зависит от количества строк (не документов), а каждый документ и каждый заголовок категории является строкой.
Диалоговое окно View Properties содержит набор параметров, управляющих индексацией представления. Эти параметры используются редко, но выбор подходящего варианта индексации может иметь большое влияние на производительность.
Например, предположим, что база данных содержит специальные документы ключевых слов, часто просматриваемые для заполнения списков ключевых слов в форме. Такие документы меняются очень редко, но остальные документы в приложении редактируются постоянно.
Нам уже известно из обсуждения функции @DbLookup, что для поиска таких документов лучше всего использовать кэш, но все равно нужно обращаться к представлению первый раз, когда еще отсутствуют кэшированные значения. При этом Lotus Notes замечает существование документов, измененных после времени последнего использования представления, и тратит время на просмотр этих документов и обнаружение того, что они не входят в представление.
Представление, использующееся в функции @DbLookup для значений ключевых слов, переиндексировать при каждом его использовании не обязательно. Для такого представления имеет смысл выбрать вариант индексации "Auto, at most every x hours" (автоматически, не чаще одного раза в x часов) с соответствующим значением x (см. рисунок 2).
Рисунок 2. Параметры индексации представления
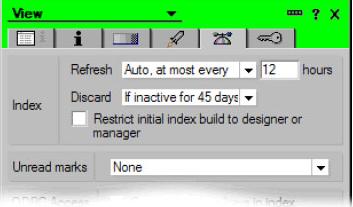
Такие представления все равно обновляются сервером, когда их никто не использует, но не слишком часто. Иногда "несчастливый" пользователь столкнется с обновлением индекса. Однако среднее время поиска будет значительно меньше, и маловероятно, что какой-нибудь пользователь пострадает от накладных расходов на все операции поиска в сложной форме. Иными словами, форма все равно будет открываться быстрее, чем в случае использования другого варианта индексации.
Если представление используется один день в каждом квартале для квартального отчета, нет смысла хранить индекс 45 дней. Настройте его на сброс после двух дней и разгрузите сервер.
Существуют другие ситуации, в которых можно улучшить производительность, выбирая подходящий вариант индексации. Есть смысл подумать о правильной настройке каждого представления.
Примечание. Имеется возможность программного обновления индекса в текущей реплике, используя метод NotesView.Refresh. Предположим, что есть индекс, который обычно обновляется редко, но при сохранении конкретной формы, данные которой участвуют в представлении, необходимо обновить это представление, для того чтобы можно было сразу же использовать новые данные. В коде Postsave этой формы используйте метод Refresh для представления. Также можно было бы использовать функции @Db с ReCache для обновления кэша специфических операций поиска в этом представлении.
Не существует замены для полей Reader, если они нужны, но они могут снижать производительность представления. При открытии представления, содержащего документы с полями Reader, Lotus Notes сканирует строки в поисках тех, к которым у вас есть доступ. Сканирование прекращается при наличии достаточного количества строк для заполнения экрана. Если вы имеете доступ только к одному документу, Lotus Notes должен просмотреть каждую строку, чтобы определить это, что может потребовать довольно много времени.
Есть несколько действий, которые можно выполнить для решения данной проблемы:
- Используйте короткие значения полей Reader. Членство в одной роли проверяется быстрее, чем сравнение их с длинным списком имен доступа (использование ролей также выгодно с точки зрения удобства эксплуатации).
- Избегайте использования представлений в таком приложении. Если пользователи имеют доступ только к одному или двум документам, предоставьте им этот доступ другими способами, например, автоматически отправляя им электронное письмо со ссылками на эти документы.
- Используйте встроенное представление с одной категорией, которая содержит "их" документы.
- Используйте категоризированное представление, настроенное на отображение пустых категорий (т.е. категорий, не содержащих документов, которые может видеть пользователь). Естественно, это также может усложнить пользователю поиск своих документов, пока вы не направите его к ним, поэтому вы можете использовать этот прием совместно с @SetViewInfo для отображения только "их" категории.
Примечание. Использование такого категоризированного представления влияет на систему защиты; т.е. вы показываете пользователю одно поле (категорию) в документах, к которым он не имеет доступа. Убедитесь в том, что это допустимо.
- Рекомендуйте пользователям применять локальные реплики. Поскольку локальная реплика содержит только те документы, к которым они имеют доступ, удаление остальных документов не требует каких-либо дополнительных действий.
Не используйте поля Reader исключительно для навигации, например, в качестве средства поиска "своих" документов, поскольку они являются в представлении единственными, которые могут видеть пользователи. Если информация в документе не является действительно частной, существуют лучшие способы помочь пользователям найти подходящие документы, как описано выше и в следующем разделе.
6.10. Индивидуально при первом использовании
@UserName и @UserRoles не дают желаемых результатов при использовании в формулах выбора или формулах столбцов общего представления. Это основная причина, по которой разработчики создают представления "Private on first use" (индивидуально при первом использовании) для отображения только "My Documents". Эти представления либо сохраняются на сервере, и в этом случае влияют на общую производительность приложения, либо сохраняются в локальном (настольном) файле пользователя.
Настольные (desktop) представления не влияют напрямую на производительность сервера, но когда кто-нибудь открывает одно из них, оно, как и остальные представления, переиндексируется для отображения последних изменений. Это означает, что компьютер пользователя должен запросить с сервера все документы, измененные после времени последнего использования данного представления. Это может занять время и, если такую операцию выполнило несколько пользователей, сервер может столкнуться с трудностями, обрабатывая многочисленные запросы на "передачу всех данных".
Отметим, что индексируемое представление использует только итоговые данные, поэтому большие поля с форматированным текстом и файловые вложения в данном случае не являются проблемой.
Кроме вопросов производительности, индивидуальные представления поднимают проблему обслуживания, поскольку для разработчика не существует простого способа обновить дизайн индивидуальных пользовательских реплик. Даже общие столбцы в данном контексте не работают, поскольку для их обновления человек, выполняющий его, должен иметь доступ к представлению.
Часто можно избежать использования Private on first use при помощи функциональности "single category" (одна категория) представлений Notes. Например, при отображении "My Documents" можно использовать представление, категоризирующее документы по владельцам, затем либо встраивать представление в форму или страницу с формулой "single category", либо использовать @SetViewInfo в событии Postopen представления для ограничения отображаемой текущему пользователю информации. Поскольку здесь имеется только одно общее представление, общие затраты на индексацию минимизируются, и отдельный пользователь не должен ждать, как в ситуации с настольным индивидуальным представлением, потому что индекс всегда находится в относительно обновленном состоянии.
Как только вы начнете писать код на LotusScript или Java™, перед вами откроется целый новый мир возможностей для создания программ с низкой производительностью. Ниже мы рассмотрим некоторые наиболее часто встречающиеся подводные камни.
Итерация по коллекции с использованием NotesDocumentCollection.GetNthDocument является очень медленной; вместо нее используйте GetFirstDocument и GetNextDocument. Существуют некоторые типы коллекций, для которых GetNthDocument эффективен, но легче просто не использовать его.
7.2. Слишком много кода действий в форме или представлении
Если в форме, представлении или папке имеется много кода действий, и вы пишете код для каждого действия в элементе дизайна (или даже при использовании общего действия), сохраняется много кода, который должен загружаться в память при каждом использовании элемента дизайна.
Основную часть времени будет использоваться только одно или два из многих действий, поэтому загрузка их всех является лишней тратой времени. Если действие появляется в нескольких местах, один и тот же код кэшируется несколько раз, используя память, которая, возможно, нужна для других целей.
Подумайте о перемещении части кода действий в приложения-агенты. Это позволит иметь только одну копию кода, загружаемого в память только в том случае, когда кто-то запросит его выполнение. Действие кнопки можно написать на макроязыке для вызова агента при помощи @Command([RunAgent]), т.е. вместе с элементом дизайна должен загружаться очень небольшой код.
Это особенно важно, если вы разрешаете пользователям создавать индивидуальные представления или папки, поскольку код действий будет дублироваться много раз в их папках, занимая пространство, и не может быть обновлен, пока пользователь вручную не удалит свое индивидуальное представление.
7.3. Слишком много библиотек сценариев
Время, необходимое для загрузки нескольких библиотек сценариев в одном и том же сценарии, увеличивается быстрее, чем в линейной прогрессии. Другими словами, загрузка десяти библиотек сценариев занимает значительно больше времени, чем удвоенное время загрузки пяти библиотек, особенно если библиотека использует ("Use") другие библиотеки.
Это может измениться в будущем, но все равно существует один беспроигрышный прием: доступ к двум элементам дизайна выполняется дольше, чем доступ к одному элементу, содержащему тот же объем кода. Комбинирование часто используемых библиотек сценариев экономит время загрузки, даже если в некоторых случаях вы можете включить код, не вызываемый в конкретном агенте.
Метод NotesDocument ComputeWithForm является простым способом обновить вычисляемые поля в документе без необходимости дублирования кода. К сожалению, он также является довольно медленным по сравнению с "ручным" вычислением и присвоением нового значения поля. Если ваш агент работает медленно и вы используете ComputeWithForm, вероятно, можно значительно ускорить его, выделив этот вызов и поместив пару строк кода для присвоения специфичных полей.
7.5. Автоматически обновляемые представления
По умолчанию объект NotesView при использовании реализует нормальные атрибуты обновления индексации. Например, предположим, что выполняется обновление коллекции документов "Овощ", и как часть данного процесса, необходимо найти вредителей этих овощей в представлении "Вредители" этой же базы данных. Но при сохранении документ "Овощ" считается измененным.
При переходе к следующему документу и выполнении поиска в представлении "Вредители" Lotus Notes замечает, что индекс представления не актуален, и обновляет его. Вам известно, что выполненное изменение не повлияло на представление "Вредители", но Lotus Notes не знает об этом, пока не протестирует измененный документ.
В этом случае имеет смысл использовать свойство AutoUpdate представления NotesView для указания системе Lotus Notes не беспокоиться об индексации представления до тех пор, пока вы явно не запросите ее при помощи метода Refresh. Это значительно ускорит работу приложения.
Также можно использовать этот метод даже в том случае, если выполняемые изменения влияют на содержимое NotesView. В данном случае вам должно быть известно, что эти изменения не будут иметь отношения к тому, что вы делаете. Например, известно, что обновление удалит документ из представления, но это не важно, поскольку вы переходите к следующему документу.
7.6. Неудачное применение эффективных методов, основанных на коллекциях
Класс NotesDocumentCollection имеет несколько методов, названия которых заканчиваются на "All", предоставляющих способ выполнять действия над всеми документами в коллекции. Познакомьтесь с этими методами, поскольку они работают намного быстрее, чем итерация по коллекции и работа с каждым документом по отдельности (естественно, если не нужно выполнять несколько действий с каждым документом; и потом, возможно, более быстрым будет выполнение итерации для сохранения каждого документа только один раз).
7.7. Повторяющиеся затратные операции
Некоторые методы и свойства во встроенных классах являются довольно медленными. Ваш код будет работать быстрее, если избегать периодического использования этих функций, когда это не нужно. Например, предположим, что по мере обработки документов в коллекции для каждого из них необходимо использовать одно из полей в качестве значения операции поиска для извлечения информации из другого представления:
Dim view As NotesView
Set docCur = coll.GetFirstDocument
Do Until docCur Is Nothing
Set view = db.GetView("CustomersByID") ' Вот! Не делайте этого в цикле!
Set docCust = view.GetDocumentByKey(docCur.CustID(0), True)
...
Set docCur = coll.GetNextDocument(docCur)
Loop |
Если бы в этом примере кода coll содержала 1000 документов, мы вызвали бы затратный метод GetView 1000 раз. Данный код будет работать значительно быстрее, если просто поменять расположение строк Do Until и Set view, так чтобы GetView вызывался только один раз.
Профилирование агентского приложения является хорошим способом поиска таких моментов. Оно рассматривается в статьях developerWorks "Диагностика производительности приложений, часть 1. Диагностика методики и советы по использованию кода" и "Диагностика производительности приложений, часть 2. Новые инструментальные средства в Lotus Notes/Domino 7".
7.8. Сохранение не изменившихся документов
Вспомните, что одним из факторов, воздействующих на производительность, является "взбалтывание" (churn), т.е. частота изменения документов. При написании приложений-агентов для обработки документов попытайтесь избегать лишнего сохранения изменений в документе. Перед присвоением значения элементу проверьте, не имеет ли уже элемент это значение. Если в конечном итоге вы ничего не изменили, не вызывайте метод Save. Часто можно использовать методы поиска для фильтрации из коллекций документов, которые не нужно обрабатывать.
Агентские приложения могут работать дольше, если постоянно проверять элементы с целью определения необходимости их изменения, а, возможно, и нет, поскольку сохранение документа выполняется намного дольше, чем сравнение информации в памяти. Но в любом случае остальные части вашего приложения будут работать эффективнее, от репликации до индексации представлений и до полнотекстовой индексации.
Исключение ненужных сохранений также уменьшает шанс возникновения конфликтов репликации. Репликация использует время изменения элемента; весь документ в другую реплику не передается, а передаются только изменившиеся элементы. Поэтому, даже при необходимости сохранения документа, время репликации уменьшается, если вы меняли только те элементы, которые должны иметь новое значение. Пользователи с локальными репликами будут вам благодарны.
Действием, которое должно делать большинство агентских приложений, является поиск набора документов для обработки. Существуют разные способы сделать это, каждый из которых подходит в разных ситуациях.
В статье developerWorks "Производительность приложений Lotus Notes/Domino 7, часть 1. Свойства базы данных и коллекции документов" рассматриваются различные способы поиска и обработки коллекций документов. Итак:
- Если имеется представление, содержащее нужные документы, отсортированные надлежащим образом, обычно можно быстрее прочитать документы из представления, например, используя метод GetAllDocumentsByKey.
- Для базы данных, содержащей большое количество документов, методы FTSearch работают более быстро, чем NotesDatabase.Search, при условии, что для базы данных выполнена полнотекстовая индексация. Отметим, что можно также выполнить полнотекстовый поиск, вводя его в событие Document Selection агентского приложения.
В обеих этих ситуациях вы экономите время благодаря использованию преимуществ индексации, которая уже была сделана сервером заранее. Поэтому меньше работы приходится на время исполнения по сравнению с методом NotesDatabase.Search, который должен тестировать каждый документ по отдельности.
Полнотекстовый поиск не позволяет выполнить фильтрацию документов с такой степенью детализации, как метод NotesDatabase.Search, но обычно он экономит достаточно времени для выполнения итерации по результатам поиска и пропуска ненужных элементов. Изучите полный синтаксис полнотекстовых запросов, документация по которому приведена в справочной системе Notes Client (не в справочной системе Designer) в разделе "Усовершенствование поисковых запросов с использованием операторов". Вы обнаружите, что можно сделать намного больше, чем вы думали.
Примечание. В зависимости от требований можно иногда комбинировать мощь формульного поиска и производительность полнотекстового поиска, выполняя полнотекстовый поиск в представлении, имеющем основанный на формулах критерий выбора.
7.10. Удаление неиспользуемых документов из кэша
В более ранних версиях Lotus Notes можно было лучше использовать память, удаляя объекты NotesDocument из памяти после завершения работы с ними при помощи выражения Delete. Однако в версиях 6.0 и старше это потеряло смысл (если вы знаете, о чем речь, больше этого делать не нужно, а если не знаете - не беспокойтесь).
Возможно, вы все еще используете Delete по иным причинам, нежели проблемы производительности, например, потому что считаете, что документ будет изменен другим процессом после последнего его открытия вами и хотите гарантировать получение самых новых данных.
7.11. Более эффективные циклы, присваивания и т.д.
В некоторых источниках предлагается сравнительная информация по времени работы циклов "for" и "while", сравнение использования глобальных и стековых переменных и т.д. Однако если ваше приложение не очень интенсивно использует вычисления, вы не увидите большого прироста производительности при использовании данной информации.
Большинство сценариев больше времени тратит на открытие документов и представлений, чем на манипуляцию со значениями переменных. Исключение необязательных ссылок на массив может сэкономить одну миллионную часть секунды, в то время как открытие необязательного представления может занимать время, измеряемое в секундах. Если вы собираетесь потратить время на повышение производительности, начните с самых весомых элементов.
Возможно, полезно знать о характеристиках производительности различных выражений и предложений LotusScript, но большую ценность имеет формирование хороших традиций написания оригинального кода - тогда редко приходится возвращаться назад и исправлять неэффективные выражения.
Единственные советы в этой области, которые мы считаем достойными упоминания:
- Не используйте GetNthDocument (как обсуждалось выше).
- Объявляйте переменные явно, чтобы исключить присваивания по умолчанию типа Variant. Это не только повысит производительность, но также поможет быстрее находить ошибки во время компиляции. Используйте параметр в свойствах панели программирования, автоматически вставляющий выражение Option Declare в код LotusScript.
При интегрировании с внешней реляционной базой данных или файлами данных LC LSX API обычно работает быстрее, чем встроенные классы ODBC. В публикации IBM Redbooks "Реализация IBM Lotus Enterprise Integrator 6" содержится много информации о том, как программировать на этом API и как максимизировать его производительность.
Как упоминалось в начале данной статьи, многие изящные небольшие приложения, отлично работающие с небольшим набором данных и небольшим количеством пользователей, перестают работать нормально, когда количество документов и пользователей резко возрастает. Имеет смысл протестировать ваш проект с большим количеством документов и проверить, что случится, когда с ним одновременно будет работать 50 человек (если у вас нет 50 друзей, имеющих свободное время, существуют автоматизированные инструментальные средства, способные имитировать такую ситуацию).
Не трудно также написать агентские приложения для извлечения небольшого набора тестовых данных и внесения их в тысячи документов, назначая случайные значения в выбранные поля. Это можно сделать даже с формульными агентами, если используется вариант с агентскими приложениями для создания новых документов (в нижней правой части экрана редактирования агента).
Но предупреждаем: если приложение уже находится в эксплуатации, выполняйте тестирование с копией базы данных (не с репликой базы данных) на свободном от работы сервере и предпочтительно с той, которая не реплицируется с рабочими серверами. Таким образом, вы исключите риск загрязнения рабочих данных, зависания или повреждения сервера, с которым работают пользователи.
9. Использование документов Profile
Документы Profile являются хорошим способом эффективно сохранять и извлекать информацию, которую не нужно часто менять. Поскольку весь документ кэшируется при первом использовании, довольно эффективным будет сохранение в нем всех ваших списков настраиваемых ключевых слов. Не будет проблем при индексации представления, и не нужно будет беспокоиться об управлении кэшированием. Они реплицируются аналогично обычным документам (за исключением того, что пользователи с формулами выбора репликации не смогут случайно нарушить работу приложения, исключив их, т.е. они и в этом смысле лучше документов с "обычными" ключевыми словами). Используйте их. Это легко и просто.
Данная статья, как бы длинна она ни была, не предоставляет исчерпывающей информации. В разделе "Ресурсы" предоставлены ссылки на дополнительную информацию и методики работы. Желательно также следить за различными блогами и wiki, посвященными Lotus, в которых часто приводятся советы, связанные с производительностью.