
Завершая серию, в этой статье я расскажу о некоторых общих возможностях Oracle Database 11g, которые очень вам понравятся, когда вы о них узнаете.
Новые Процессы
Каждая новая версия Oracle Database приносит с собой новый набор процессов, новых их аббревиатур. Вот этот список для Oracle Database 11g Release 1:
| Процесс | Имя | Описание |
| ACMS | Atomic Controlfile to Memory Server | Применим только для экземпляра RAC. Когда производится обновление распределенной SGA, процесс ACMS гарантирует, что это обновление произойдет на всех экземплярах. Если же обновление на одном из экземпляров не удалось, процесс обеспечивает откат на всех экземплярах. Процесс ACMS можно представить как координатор двухфазной фиксации (two-phase commit) для SGA в кластере RAC. |
| DBRM | Database Resource Manager | Менеджер Ресурсов Базы Данных реализует ресурсные планы и другие задачи управления ресурсами. |
| DIA0 | Diagnosibility process 0 | Диагностирующий процесс0 обнаруживает зависания и взаимные блокировки. Со временем, возможно, таких процессов будет больше. Поэтому имя - dia0. Другие процессы, если они появятся в будущем, получат назвния dia1, dia2 и т.д. |
| DIAG | Diagnosibility process | Диагностирующий процесс выполняет диагностику, при необходимости сбрасывает данные в трассовые файлы и выполняет общие команды утилиты oradebug. |
| FBDA | Flashback Data Archiver | Архиватор Ретроспективных Данных Oracle Database 11g содержит новую функциональность "Flashback Archive" для записи изменений, выполненных по отношению к таблице (см. статью "Transactions Management" в этой серии). Этот процесс формирует ретроспективные архивы. |
| GTX0 | Global Transaction Process 0 | Процесс Глобальных Транзакций0 - в кластере Oracle Database RAC предоставляет улучшенную обработку XA-транзакций. Он координирует XA-транзакции. Если на базу данных растет XA-нагрузка, автоматически создаются дополнительные процессы с именами GTX1, GTX2, вплоть до GTXJ. |
| KATE | Konductor (Conductor) of ASM Temporary Errands | Проводник Временных Заданий ASM Несомненно, лучшее имя из всех новых процессов. Процесс можно увидеть только на ASM-экземплярах, в базе данных его нет (обратитесь к статье об ASM, и, в частности, о новой функциональности Fast Disk Resync). Когда диск выключается (offline), этот процесс выполняет посреднический I/O от имени диска в метафайл ASM. |
| MARK | Mark AU for Resync Koordinator (coordinator) | Обратитесь к статье об ASM для получения дополнительной информации о гибкости дисковых групп ASM. Если происходит сбой диска, он становится недоступным (offline), тем самым, запись становится невозможной. В этом случае процесс MARK помечает единицы пространства ASM (AU) как неактуальные. Когда диск восстанавливает работоспособность, неактуальные сегменты обновляются. |
| SMCO | Space Manager | Менеджер Пространства (SMCO) является главным процессом управления, который, динамически добавляет и удаляет пространство. Порождает дочерние процессы Wnnn для выполнения задач. |
| VKTM | TiMe Virtual Keeper of TiMe process | Виртуальный Хранитель Процесса предоставляет собой эквивалент настенных часов (с обновлением 1 раз в секунду). Работая с повышенным приоритетом, предоставляет обновление раз в 20 миллисекунд. |
| W000 | Space Management Worker Processes | Рабочие Процессы Управления Пространством - выполняют инструкции, полученный от SMCO. При необходимости порождается необходимое количество процессов с именами W000, W001 и т.д. |
Подсвеченный SQL
Эта новая возможность не раскрашивает SQL-предложения разными цветами; наоборот, она сортирует и помечает их по их "важности" (as "important").
Представим ситуацию, что администратор исследует проблему с производительностью и находит подозрительное SQL-предложение, которое и является причиной проблемы. Теперь он хочет, чтобы это SQL-предложение захватывалось во время каждого снимка Automatic Workload Repository (AWR). Однако AWR-снимки не захватывают все SQL-предложения подряд; только топовые. Каким образом его принудить захватить конкретный SQL, вне зависимости, в топе он или нет?
Процедура add_colored_sql() из пакета dbms_workload_repository помечает SQL, как "цветной" или достаточно важный, чтобы быть захваченным каждым AWR- снимком, вне зависимости, попадает ли этот запрос в топ или нет. Для начала, найдем SQL-предложение и получим его SQL_ID. Для его маркировки, используем:
begin
dbms_workload_repository.add_colored_sql(
sql_id => 'ff15115dvgukr'
);
end;
Для того чтобы найти, какой SQL был помечен, обратимся к AWR-таблице WRM$_COLORED_SQL:
SQL> SELECT * FROM wrm$_colored_sql;
DBID SQL_ID OWNER CREATE_TI
---------- ------------- ---------- ---------
2965581158 ff15115dvgukr 1 05-APR-08
Это показывает, что SQL-предложение с ID ff15115dvgukr будет захватываться каждым снимком, даже если оно не в топе SQL-предложений (конечно, чтобы быть захваченным AWR-снимком, это SQL-предложение должно быть в библиотечном кеше).
Но что делать, если SQL перестает быть ценным, т.е. более нет необходимости в его захвате? Его можно исключить, вызвав противоположную процедуру:
begin
dbms_workload_repository.remove_colored_sql(
sql_id => 'ff15115dvgukr'
);
end;
Эта возможность является чрезвычайно удобной, когда требуется сфокусироваться на конкретном SQL во время задач по настройке.
Сжатие Таблиц в OLTP
С давних пор в той или иной форме сжатие было реализовано как возможность Oracle Database.
Сжатие - задача, всегда требующая ресурсов CPU и занимающая время. Обычно, если данные сжаты, их необходимо разжать, чтобы ими воспользоваться. В то время как это требование приемлемо в системах хранения данных, где SQL обычно оперирует с большим набором строк и достаточно долгие ответы в основном устраивают пользователей, в OLTP-средах это может быть неприемлемо.
Теперь, в Oracle Database 11g, можно сделать вот что:
create table my_compressed_table ( col1 number(20), col2 varchar2(300), ... ) compress for all operations
Предложение "compress for all operations" включает сжатие на все DML- предложения, такие как INSERT, UPDATE и т.д. Сжатие будет происходить на любой DML-активности, а не только на direct path вставках как в предыдущих релизах.
Будет ли это замедлять выполнение DML-предложения? Не обязательно. Вот где новая возможность работает лучшим образом. Сжатие не происходит в момент, когда строка вставляется в таблицу; строка вставляется несжатой и в обычном порядке. Когда определенное количество строк вставлено (или обновлено) в несжатом виде, в дело вступает алгоритм сжатия и сжимает все несжатые строки в блоке. Другими словами, сжат блок, а не строка. Порог, после которого происходит сжатие, определен внутри кода базы данных.
Механика Сжатия
Возьмем таблицу ACCOUNTS, содержащую строки:
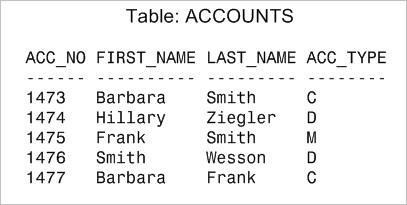
Представим, что внутри базы данных все эти строки хранятся в одном блоке данных.

Вот так выглядит несжатый блок данных: записи со всеми данными всех полей (столбцов). При сжатии блока база данных сначала определяет все повторяющиеся значения, найденные в строках, перемещает их из строк и помещает рядом с заголовком блока данных. Эти повторяющиеся значения в строках заменяются на символ, уникально определяющий каждое из таких значений. Этот алгоритм концептуально изображен на иллюстрации ниже - блок до и после сжатия:
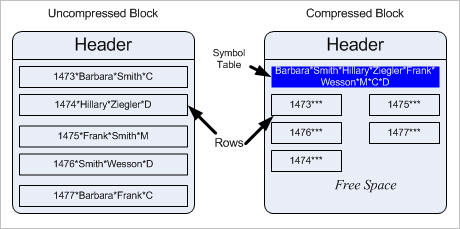
Обратите внимание, как значения изъяты из строк и вставлены в специальную область вверху, называемую "Symbol Table" (Таблица Символов). Каждому значению в столбцах присвоен символ, который замещает реальное значение в строке. Так как символы по размеру меньше реальных значений, размер записи существенно меньше оригинально размера. Чем больше повторяющихся значений в строке, тем более компактной получается таблица символов и, следовательно, блок данных.
В связи с тем, что сжатие происходит событийно, а не во время вставки строки, влияние на производительность равно нулю во время обычной DML-операции. Конечно, когда возникает событие сжатия, требования к CPU повышаются, но все остальное время влияние на CPU нулевое, тем самым делая сжатие приемлемым для OLTP-приложений - это главный факт для компрессии в Oracle Database 11g.
Другими немаловажными свойствами сжатия, кроме уменьшения потребления дискового пространства, является уменьшение времени передачи данных по сети, уменьшение места для резервных копий и возможность реально оперировать полными копиями промышленной базы данных для QA и тестирования.
COPY жив!
Вопреки слухам, команда COPY все еще тут. И она все еще является единственной возможностью копировать данные типа LONG. Однако в связи с тем, что эта команда является устаревшей, она не поспевает за новейшими разработками в Oracle Database.
Например, она не знает о существовании нового типа данных, называемого BFILE. Если попробовать скопировать таблицу DOCS, содержащую столбец BFILE, получится вот что:
SQL> copy to sh@oradba11 - &lgt; replace docs_may08 - > using select * from docs > where creation_dt between '1-may-08' and '31-may-08'; Enter TO password: Array fetch/bind size is 15. (arraysize is 15) Will commit when done. (copycommit is 0) Maximum long size is 80. (long is 80) CPY-0012: Datatype cannot be copied
Сообщение об ошибке говорит само за себя: команда COPY не может скопировать данные типа BFILE. Однако в случае с таблицей, содержащей столбец типа LONG, нельзя использовать операторы INSERT /*+ APPEND */ и CREATE TABLE ... NOLOGGING AS SELECT ... Вот пример, где мы попытаемся скопировать несколько строк из одной таблицы в другую и при этом один из столбцов будет типа LONG:
SQL>create table mytab1 as select * from mytab where col1 = 'A';
create table mytab1 as select * from mytab
*
ERROR at line 1:
ORA-00997: illegal use of LONG datatype
SQL> insert /*+ APPEND */ into mytab
2> select * from mytab where col1 = 'A';
select * from mytab
*
ERROR at line 2:
ORA-00997: illegal use of LONG datatype
Таким образом, единственным простым способом скопировать большой объем данных без заполнения undo-сегментов, является использование команды COPY.
Экспорт и Импорт
Когда в Oracle Database 10g появился механизм Data Pump, постепенное устаревание традиционных утилит Export и Import было ожидаемо. Однако, не торопитесь: в Oracle Database 11g эти старые утилиты очень нужны. Будучи "снятыми с производства", не получая никакого развития, тем не менее они далеки от бесполезности.
По количеству возможностей Data Pump во много раз обгоняет обычный Export/Import, однако в одном простом примере последний очень полезен: когда необходимо создать дамп-файл на стороне клиента, а не сервера. Нет нужды создавать директорию перед выполнением этой операции, поэтому в большинстве случаев простой экспорт данных проще выполнить с помощью стандартного Export/Import.
Однако, напоминаю еще раз - эти утилиты больше не развиваются, поэтому, используя их, существует три риска:
- Oracle больше не добавляет в них никакой функциональности, поэтому будущие типы данных и т.д., возможно, не будут поддерживаться.
- Они могут исчезнуть из будущих релизов без дополнительных уведомлений, тем самым заставив пользователей позже переписывать код.
- В случае обнаружения бага, Oracle Support может отказать в исправлении кода.
Таким образом, имеет смысл переписать существующий код на использование Data Pump, особенно в новых разработках.
Инкрементально Обновляемая Глобальная Статистика
В любой секционированной таблице по каждой секции может собрать статистику оптимизатора. К тому же существует глобальная статистика на всю таблицу, и она не зависит от секций, например, количество уникальных значений во всей таблице. По-умолчанию глобальная статистика не собирается - только в случае, если это делается умышленно с помощью процедур dbms_stats.gather_*_stats. Если параметр global_stats не указан, она не собирается, и оптимизатор получает ее из статистик секций. Конечно, собранная глобальная статистика всегда намного точнее, чем полученная из секций, поэтому всегда предпочтительнее собирать их обе.
Однако, есть одна проблема: когда данные в одной из секций изменяются и при этом остальные секции остаются без изменений, глобальная статистика становится устаревшей. Поэтому, процесс пересбора статистики должен пройти по всей таблице для сбора глобальной статистики, даже если изменения произошли лишь в одной секции.
Больше этого не будет. В Oracle Database 11g появилась возможность указать оптимизатору собрать глобальную статистику инкрементально, просканировав только изменившуюся секцию, тем самым избежав полного табличного сканирования. Достигается это путем указания параметра INCREMENTAL в значение TRUE для таблицы во время сбора статистики:
begin
dbms_stats.set_table_prefs(
'SH','SALES','INCREMENTAL','TRUE');
end;
/
Соберем статистику по таблице, а конкретно - по секции SALES_1995 с указанием параметра granularity (зернистость) равным AUTO:
begin
dbms_stats.gather_table_stats (
ownname => 'SH',
tabname => 'SALES',
partname => 'SALES_1995',
granularity => 'AUTO'
);
end;
Этот метод сбора статистики указывает базе данных инкрементально обновить глобальную статистику на основании той, что была собрана из новой секции.
DataPump Становится Лучше
Как я уже показывал выше, начиная с предыдущего релиза базы данных, Data Pump является лучшим инструментом для перемещения больших объемов данных или эффективного получения "логических" резервных копий данных. Аналогично утилитам Export/Import, Data Pump платформо-независим (например, можно экспортировать данные на Linux и импортировать их в Solaris). В Oracle Database 11g он получил несколько усовершенствований.
Одна из серьезных проблем с использованием Data Pump - невозможность сжатия получаемых файлов во время их создания. В тех же старых утилитах Export/Import это делалось просто. В Oracle Database 11g Data Pump умеет сжимать файлы дампов во время их создания. Достигается это указанием параметра COMPRESSION в командной строке expdp. Параметр имеет три опции:
- METDATA_ONLY - сжимаются только метаданные; данные остаются как есть (кстати, в Oracle Database 10.2 это также доступно)
- DATA_ONLY - сжимаются только данные; метаданные остаются без изменений.
- ALL - сжимается все - и данные и метаданные.
- NONE - значение по-умолчанию; сжатия не производится.
Вот пример того, как сжать экспорт таблицы UNITS_FACT:
$ expdp global/global directory=dump_dir tables=units_fact
dumpfile=units_fact_comp.dmp compression=all
Для сравнения, экспортируем ту же таблицу, но без сжатия:
$ expdp global/global directory=dump_dir tables=units_fact
dumpfile=units_fact_uncomp.dmp
Теперь сравним полученные файлы:
$ ls -l -rw-r----- 1 oracle dba 2576384 Jul 6 22:39 units_fact_comp.dmp -rw-r----- 1 oracle dba 15728640 Jul 6 22:36 units_fact_uncomp.dmp
Расчет степени сжатия: 100*(15728640-2576384)/15728640 или около 83.61%! Это действительно впечатляет: несжатый файл занимает 15 Мб, в то время как сжатый - 1.5 Мб.
Если сжать экспортный файл с помощью gzip:
$ gzip units_factl_uncomp.dmp -rw-r----- 1 oracle dba 3337043 Jul 6 22:36 units_fact_uncomp.dmp.gz
Сжатый файл занимает около 3.2 Мб, что в два раза больше сжатия, полученного с помощью Data Pump. Таким образом, в дополнение к потенциально более эффективному сжатию, разархивирование действительно имеет смысл. Во время импорта файла дампа, процессу импорта не нужно сначала разархивировать файл - это происходит по мере чтения, делая процесс действительно быстрым.
И еще два усовершенствования в Data Pump:
- Encryption (Шифрование): во время создания, файл дампа может быть зашифрован. Процесс шифрования использует ту же технологию, что и TDE (Transparent Data Encryption) - для хранения master key используется wallet (кошелек). Однако, в отличие от Oracle Database 10g, шифрованию подвергается весь файл экспорта, а не только зашифрованные столбцы таблиц.
- Masking (Искажение данных): во время импорта данных из промышленной среды в QA, бывает необходимо изменить чувствительную для бизнеса информацию (номера социального страхования, кредитных карт и т.д.) таким образом, чтобы она не представляла ценности. В Oracle Database 11g утилита Data Pump позволяет сделать это, создав функцию маскинга и использовав ее во время экспорта.
Почитать об этих возможностях можно в статье по безопасности.
Действенная оперативная перестройка индексов
Помните предложение ONLINE для перестройки индекса?
alter index in_tab_01 rebuild online;
Этот оператор перестроит индекс, не затрагивая DML-команды, использующие его. Достигается это отслеживанием, какие блоки индекса используются, и в конце работы по перестройке индекса эти блоки объединяются с только что построенным индексом. Для завершения этой задачи операция по перестройке индекса должна получить эксклюзивную блокировку в конце работы. Несмотря на то что она очень короткая, тем не менее ее не избежать и DML-операторы будут ждать.
В Oracle Database 11g online перестройка индексов действительно online: она не ставит эксклюзивную блокировку. DML-команды не затрагиваются.
Различные Табличные Пространства для Временных Таблиц
Создавая глобальную временную таблицу, где происходит выделение требуемого пространства? Оно берется из временного табличного пространства пользователя. Обычно это не является проблемой, однако в некоторых случаях бывает необходимо освободить временное табличное пространство от нужд, для которых оно предназначается (сортировки в основном). Иногда требуется создать временную таблицу в другом табличном пространстве, на более быстрых и эффективных дисках для ускорения доступа к данным. Другого выхода нет, кроме как назначить это табличное пространство временным табличным пространством пользователя.
В Oracle Database 11g можно использовать другое временное табличное пространство для глобальных временных таблиц. Посмотрим, как это делается. Для начала создаем еще одно временное табличное пространство:
SQL> create temporary tablespace etl_temp 2> tempfile '+DG1/etl_temp_01.dbf' 3> size 1G; Tablespace created.
Теперь создаем GTT с указанием нового табличного пространства:
SQL> create global temporary table data_load ( 2> input_line varchar2 (2000) 3> ) 4> on commit preserve rows 5> tablespace etl_temp; Table created.
Все, эта временная таблица создана в табличном пространстве ETL_TEMP вместо табличного пространства TEMP, назначенного пользователю по-умолчанию.
Запись Ошибок в SQL*Plus
Допустим, есть SQL-скрипт с именем myscript.sql:
set puase on set lines 132 pages 0 trimsppol on select * from nonexistent_table /
Обратите внимание, скрипт содержит несколько ошибок: опечатка в первой строчке в написании "pause", во второй строчке опечатка в написании "trimspool" и, наконец, третья строчка содержит выражение SELECT из таблицы, которой вовсе не существует. Запуская такой скрипт через командную строку SQL*Plus, если вывод (spool) не включен, обнаружить ошибку после работы скрипта невозможно. Даже в случае, если вывод все же был, необходим доступ к удаленному серверу для анализа spool-файла, что не всегда возможно.
Oracle Database 11g предлагает идеальное решение: теперь есть возможность фиксировать ошибки, идущие из SQL*Plus, в специальной таблице. Для этого необходимо первой командой выдать:
SQL> set errorlogging on
Теперь запускаем скрипт:
SQL> @myscript
Выполнение скрипта сформирует вот такое сообщение об ошибке:
SP2-0158: unknown SET option "puase"
SP2-0158: unknown SET option "trimsppol"
select * from nonexistent_table
*
ERROR at line 1:
ORA-00942: table or view does not exist
которое можно увидеть, а можно и не увидеть, в зависимости от того, каким способом был запущен скрипт - из командной строки SQL*Plus, или в фоне, как вызов скрипта. После того как скрипт отработал, авторизовавшись в базе данных, следует проверить таблицу SPERRORLOG:
sql> col timestamp format a15 sql> col username format a15 sql> col script format a10 sql> col identifier format a15 sql> col statement format a20 sql> col message format a20 sql> select timestamp, username, script, statement, message 2> from sperrorlog; TIMESTAMP USERNAME SCRIPT STATEMENT MESSAGE --------------- --------------- ---------- -------------------- -------------------- 05-JUL-08 06.08 SH myscript.s set puase on SP2-0158: unknown SE .41.000000 PM ql T option "puase" 05-JUL-08 06.08 SH myscript.s set lines 132 pages SP2-0158: unknown SE .41.000000 PM ql 0 trimsppol on T option "trimsppol" 05-JUL-08 06.08 SH myscript.s select * from nonexi ORA-00942: table or .41.000000 PM ql stent_table view does not exist
Обратите внимание, проверка ошибок была выполнена из другой сессии, а не той, в которой скрипт был выполнен. К тому же, скрипт отработал и сессия так и так прекратила существование. Таким образом, появляется мощное средство для проверки ошибок после того, как они возникли в сессиях SQL*Plus, что другим способом было невозможно, или, по крайней мере, сложно.
Таблица SPERRORLOG является специальной таблицей, созданной только для описанных целей. Можно также создать свою собственную таблицу и наполнять ее ошибками SQL*Plus. Таблица должна быть создана так:
SQL> create table my_sperror_log 2 ( 3 username varchar2(256), 4 timestamp timestamp, 5 script varchar2(1024), 6 identifier varchar(256), 7 message clob, 8 statement clob 9 ) 10 / Table created.
Теперь, вместо таблицы по умолчанию, можно использовать эту таблицу для фиксирования ошибок.
SQL> set errorlogging on table sh.my_sperror_log; SQL> @myscript
Теперь таблица MY_ERROR_LOG (а не SPERRORLOG) будет хранить журнал ошибок. Для усечения всех строк в таблице, выполним команду:
SQL> set errorlogging on truncate
Есть также дополнительный оператор IDENTIFIER, позволяющий отмечать ошибки из определенных сессий. Допустим, выдана команда:
SQL> set errorlogging on identifier MYSESSION1
Теперь, запустив скрипт, записи будут создаваться, заполняя столбец IDENTIFIER значением MYSESSION1. Получить только эти записи можно вот таким запросом:
select timestamp, username, script, statement, message from sperrorlog where identifier = 'MYSESSION1';
Таким образом будут отображены записи только из этой сессии. Это очень полезно, если необходимо изолировать ошибки во множестве скриптов и сессий.
Сжатие Временного Табличного Пространства
Скорее всего вам известно, временные табличные пространства особенные - обычные правила управления пространством для них могут не подходить. Когда выделяется временный сегмент, в последствии он не освобождается. Это не является проблемой, ведь временные сегменты (для которых и используются временные табличные пространства) не является частью схемы и не хранятся между циклами базы данных. Место используется повторно для другого пользователя или другого запроса. В любом случае, так как место не освобождается, временные табличные пространства со временем увеличиваются в размерах. Что делать, если необходимо обрезать их для освобождения места под другие табличные пространства?
До сих пор единственной возможность было удалить и пересоздать табличное пространство - в принципе тривиальная задача, практически всегда выполнимая на лету. Тем не менее, есть одно маленькое "но": что делать, если требуется 100% доступность системы и никак иначе? В Oracle Database 11g можно достичь этого просто уменьшив временное табличное пространство.
Вот каким образом сжимается табличное пространство TEMP1:
alter tablespace temp1 shrink space;
Этим действием освобождаются все незанятые сегменты из табличного пространства и оно сжимается. После этой операции можно посмотреть представление DBA_TEMP_FREE_SPACE для проверки, сколько свободного и занятого места сейчас есть.
SQL> select * from dba_temp_free_space; TABLESPACE_NAME TABLESPACE_SIZE ALLOCATED_SPACE FREE_SPACE ------------------------------ --------------- --------------- ---------- TEMP 179306496 179306496 178257920
В достаточно спокойной базе данных операция сжатия может уменьшить временное табличное пространство практически до нуля. Однако, это очень искусственная ситуация, последующая активность расширит табличное пространство, поэтому логичнее оставить какое-то место, например 100 Мб. Вот как это сделать:
SQL> alter tablespace temp shrink space keep 100m; Tablespace altered. SQL> select * from dba_temp_free_space; TABLESPACE_NAME TABLESPACE_SIZE ALLOCATED_SPACE FREE_SPACE ------------------------------ --------------- --------------- ---------- TEMP 105906176 1048576 104857600
Все пространство, за исключением 100 Мб, отдано. Так можно управлять объемом различных табличных пространств. Теперь можно позаимствовать место из временного табличного пространства и дать на время другим табличным пространствам (без шуток). Позже, когда место больше не нужно, его можно вернуть во временное табличное пространство. Совмещая эту возможность с табличным пространством для глобальных временных таблиц, можно решать множество сложных проблем с управлением объемом временных табличных пространств.
SQL*Plus показывает BFILE
В Oracle Database тип данных BFILE хранит указатель на внешний файл, а не содержимое самого файла. Он выполняет специфическую функцию: сохраняется место в базе данных, в то время как пользователи имеют доступ к данным в файлах. Это удобно для некоторых приложений, например, использующих базы данных с мультимедийным содержимым.
Если в таблице существует столбец с типом данных BFILE, попытка выбрать из него данные через SQL*Plus завершится получением ошибки. Однако, в Oracle Database 11g утилита SQL*Plus в качестве значения столбца покажет путь к файлам.
Посмотрим пример. Для начала необходимо создать объект directory для размещения BFILE.
SQL> create directory doc_dir as '/u01/oracle/docs';
Directory created.
Теперь сама таблица.
SQL> create table docs
2 (
3 doc_id number(20),
4 doc_file bfile,
5 doc_type varchar2(10)
6 );
Table created.
Создаем строку.
SQL> insert into docs values
2 (
3 1,
4 bfilename('DOC_DIR','metric_daily_report.pdf'),
5 'PDF'
6 );
1 row created
Теперь, если выбрать эту строку через SQL*Plus:
SQL> col doc_file format a50
SQL> select * from docs;
DOC_ID DOC_FILE DOC_TYPE
---------- -------------------------------------------------- ----------
1 bfilename('DOC_DIR', 'metric_daily_report.pdf') PDF
Вывод в столбце DOC_FILE, который является BFILE, показывает место расположения файла, а не ошибку.
Параметрические Файлы в Памяти
Представим ситуацию: в процессе диагностики какой-либо проблемы с базой данных, было модифицировано множество параметров, все в памяти. Позже можно забыть, какие именно параметры были изменены. Если забыть записать эти параметры в файл параметров (pfile или spfile), эти изменения будут потеряны. Так как происходили эксперименты со значениями, они не были внесены в файл параметров, ведь было неясно, какое именно значение использовать для того или иного параметра. Конечно, можно пройти по журналу alert.log и вытащить все измененные значения, но эта процедура не только болезненна, но и потенциально может содержать ошибки.
В Oracle Database 11g можно использовать очень простую команду для создания pfile или spfile на основании значений параметров в памяти.
SQL> create spfile from memory; File created. SQL> create pfile from memory; File created.
Этой командой будет создан pfile или spfile со значениями из памяти. В самом верху pfile будет расположена строка, подобная этой:
# Oracle init.ora parameter file generated by instance ODEL11 on 08/28/2007 14:52:14
Этот метод избавляет от усилий и риска во время поиска параметров, измененных в памяти. Также эта возможность позволяет создать pfile с другим именем и затем сравнить текущий pfile с только что сгенерированным на предмет обнаружения параметров, которые изменены.
SQL> create pfile='/tmp/a' from memory;
Эта команда создаст pfile в виде /tmp/a. Теперь в Unix простая команда diff покажет различия в этих двух файлах.
Сброс с Оглядкой
Во время процесса настройки производительности проводится анализ влияния некоторых динамических параметров инициализации, и значения меняются сразу в spfile. К несчастью, администратор забыл, что именно и на что он менял. Так как изменения были внесены сразу в spfile, на основании его уже нельзя сказать, что именно было изменено.
И вот тут появляется кавалерия: команда ALTER SYSTEM RESET сбрасывает значение на значение по-умолчанию, не смотря на то, что используется spfile.
alter system reset license_max_sessions;
В предыдущих релизах эта команда также была доступна, но с одним большим отличием: требовалось указывать SID при использовании в конфигурации RAC. Если было необходимо сбросить параметр на всех экземплярах, указывалось SID='*'. В Oracle Database 11g конструкция SID является необязательной и значением по-умолчанию являются все экземпляры. Таким образом, если забыть указать эту конструкцию, раньше команда завершалась с ошибкой; теперь она выполнится, но эффект может быть не тем, который от нее ждут. Будьте внимательны.
Мониторинг SQL в Реальном Времени
С этой возможностью диагностика производительности получила огромный скачок. Представим: кто-то запустил набор SQL-запросов (возможно, внутри блока PL/SQL). Каким образом узнать, сколько ресурсов (CPU, I/O и т.д.) потребляет каждый шаг на пути доступа? Можно трассировать сессию или анализировать трассовый файл с помощью Trace Analyzer или старого tkprof, но все это уже будет после случившегося. Было бы неплохо иметь возможность заглянуть, что именно сейчас происходит в сессии, не правда ли?
В Oracle Database 11g новая возможность, Real Time SQL Monitoring, делает именно то, что сказано в ее названии: позволяет видеть различные метрики выполняемого SQL в реальном времени. Статистики становятся доступными через динамическое представление производительности V$SQL_MONITOR, которое обновляется раз в секунду.
Для демонстрации запустим большой запрос и будем наблюдать за статистиками в реальном времени. Мы знаем, что SID запущенной сессии равен 103. Для запроса из представления я использовал знаменитый инструмент Томаса Кайта print_table, позволяющий видеть результат в вертикальном формате для лучшей восприимчивости.
SQL> exec print.tbl('select * from v$sql_monitor where sid = 103')
KEY : 476741369968
STATUS : EXECUTING
FIRST_REFRESH_TIME : 07-jul-2008 14:13:38
LAST_REFRESH_TIME : 07-jul-2008 14:26:27
REFRESH_COUNT : 48043
SID : 103
PROCESS_NAME : ora
SQL_ID : 2xj1nram1k1x0
SQL_EXEC_START : 07-jul-2008 14:13:31
SQL_EXEC_ID : 16777216
SQL_PLAN_HASH_VALUE : 1759042790
SQL_CHILD_ADDRESS : 38837734
SESSION_SERIAL# : 32668
PX_SERVER# :
PX_SERVER_GROUP :
PX_SERVER_SET :
PX_QCINST_ID :
PX_QCSID :
ELAPSED_TIME : 42638722
CPU_TIME : 9199624
FETCHES : 48032
BUFFER_GETS : 3238
DISK_READS : 12096
DIRECT_WRITES : 13419
APPLICATION_WAIT_TIME : 0
CONCURRENCY_WAIT_TIME : 134534
CLUSTER_WAIT_TIME : 0
USER_IO_WAIT_TIME : 148436
PLSQL_EXEC_TIME : 0
JAVA_EXEC_TIME : 0
-----------------
Названия большинства столбцов говорят сами за себя: SQL_ID - sql_id выполняемого SQL пользователем SID; STATUS - статус SQL прямо сейчас, показывающий, что SQL выполняется прямо сейчас; SQL_EXEC_START - время начала; и т.д. столбцы типа CPU_TIME, DISK_READS и DIRECT_WRITES отображают одноименные метрики. Если продолжить исполнение запроса будет видно, как эти метрики обновляются.
Еще одно представление, V$SQL_PLAN_MONITOR, показывает обновляемый в реальном времени план выполнения запускаемых SQL запросов. Вот каким образом можно использовать это представление, чтобы увидеть всевозможные шаги в плане и связанную статистику в реальном времени.
select plan_line_id,
plan_operation,
plan_options,
output_rows
from v$sql_plan_monitor
where sid = 103
order by plan_line_id;
PLAN_LINE_ID PLAN_OPERATION PLAN_OPTIONS OUTPUT_ROWS
------------ ------------------------------ ------------------------------ -----------
0 SELECT STATEMENT 809994
1 HASH GROUP BY 809994
2 HASH JOIN 918845
3 PART JOIN FILTER CREATE 1826
4 TABLE ACCESS FULL 1826
5 HASH JOIN 918845
6 TABLE ACCESS FULL 503
7 HASH JOIN 918845
8 TABLE ACCESS FULL 72
9 HASH JOIN 918845
10 TABLE ACCESS FULL 5
11 HASH JOIN 918845
12 TABLE ACCESS FULL 55500
13 PARTITION RANGE JOIN-FILTER 918845
14 TABLE ACCESS FULL 918845
Аналогично предыдущему представлению, если перезапустить запрос будет видно, как обновляются метрики. Эти два представления позволяют углубиться в обработку SQL в реальном времени.
Другой полезной частью мониторинга SQL в реальном времени является SQL Monitor Report. Используя этот инструмент можно получить визуальный отчет о различных метриках SQL и шагов плана. Отчет генерируется как вывод типа CLOB из функции REPORT_SQL_MONITOR из пакета DBMS_SQLTUNE. Вот как вызывать эту функцию:
SQL> set long 99999 lines 3000 pages 0 trimspool on SQL> select dbms_sqltune.report_sql_monitor ( 2 event_detail => 'YES', 3 report_level => 'ALL', 4 type => 'HTML' 5 ) 6 from dual;
Направим вывод в файл rep1.html и запустим SQL. Через какое-то время выполним этот SQL еще раз, направив вывод в новый файл - re2.html. И в конце, после того как запрос отработал, запустим еще раз, направив вывод в rep3.html. Каждый отчет является снимком метрик SQL в реальном времени за отчетный период. Создавая отчет в трех разных моментах времени позволяет отследить изменения. Открыв один из отчетов в Web браузере, будет виден отчет, похожий на этот:
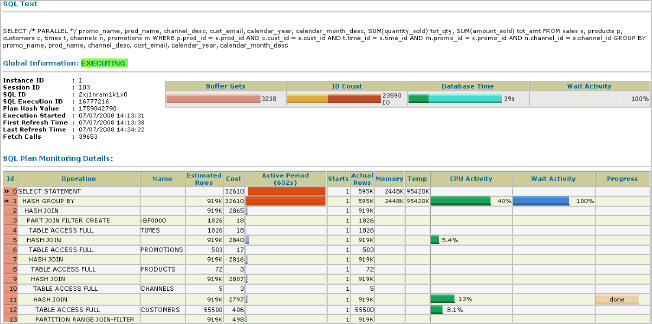
На нем отображено SQL-предложение вместе с метриками. В левом верхнем углу расположены метаданные об этом SQL - время запуска, последнего обновления и т.д. Правее расположены несколько цветных графиков, отображающих разные метрики. При наведении курсора мышки на эти графики, будет показано их описание вместе со значениями, которые они иллюстрируют.
Нижняя часть экрана содержит план оптимизатора для этого запроса вместе со временем, затрачиваемым на каждый шаг и разбитым по таким категориям, как Активность CPU, Ожидания (Waits) и т.д. Цветные графики показывают относительные значения для каждой метрики. При наведении курсора мышки над этими графиками, будут показаны значения и интервалы времени для каждой метрики.
Этот отчет является не более чем снимком рассмотренного ранее представления Монитора SQL в Реальном Времени, показанного в графическом виде. Представленные в графическом виде данные помогают понять составные части запроса и измерить время, проведенное в каждой из этих частей, тем самым делая диагностику производительности проще.
Заключительная Заметка
Этим завершается 20-недельный ураганный тур по новым возможностям, представленным в Oracle Database 11g. Как и любой автор, я старался сохранить деликатный баланс между глубиной и шириной. В прошлой серии статей об Oracle Database 10g Rel 1 и Rel 2, отзывы читателей были громкими и ясными: вам нравится стиль изложения основанный на примерах, поэтому я не отошел от такого формата и в этой серии.
Мои искренние благодарности уходят рецензентам, которые утверждали эту серию. Я не могу не поблагодарить Джастина Кестелина (Justin Kestelyn) за поддержку и помощь в приведении этого проекта к успеху. И спасибо тебе, дорогой читатель, за придание смысла всему этому.