
Data Mining - современная технология анализа информации с целью нахождения в накопленных данных ранее неизвестных, нетривиальных и практически полезных знаний, необходимых для принятия оптимальных решений в различных областях человеческой деятельности.
Microsoft SQL Server 2005 предоставляет интегрированную среду для создания моделей Data Mining и работы с ними. В курсе описаны четыре сценария (адресная рассылка, прогнозирование, анализ покупательской корзины и анализ последовательности покупок) для демонстрации методов использования алгоритмов Data Mining, а также сопутствующего инструментария, входящего в состав SQL Server Analysis Services 2005.
Средства анализа данных OLAP и Data Mining объединены в две среды разработки: Business Intelligence Development Studio и SQL Server Management Studio. В Business Intelligence Development Studio можно создавать отсоединенные от сервера проекты. В этом случае готовый проект можно загрузить на сервер, но ничто не мешает работать с проектом, работающим с сервером напрямую.
Все средства для управления моделями Data Mining доступны в редакторе моделей. С его помощью можно создавать, просматривать, сравнивать разные модели, а также создавать на их базе прогнозы.
После создания модели можно провести ее анализ на предмет выявления интересных для нас шаблонов (паттернов) и правил. В зависимости от применяемого алгоритма в среде разработки используется различные представления просматриваемой модели.
Поскольку зачастую проект содержит несколько моделей Data Mining, предварительно созданных на основе наших предположений, то возникает задача определения наиболее адекватной из них. Для решения этой задачи в редакторе присутствует средство сравнения моделей Mining Accuracy Chart. С использованием этого инструмента можно предсказать точность модели и выбрать лучшую их них.
Для создания прогнозов используется язык Data Mining Extensions (DMX), который является расширением SQL и содержит команды для создания, изменения и осуществления предсказаний на основании различных моделей. Создание таких прогнозов может быть сложной задачей, поэтому в редакторе присутствует инструмент под названием Prediction Query Builder, которых представляет собой визуальное средство создания DMX-запросов.
Кроме инструментария для работы с моделями, не менее значимыми являются и способы создания моделей. Ключевым моментом создания модели является выбор алгоритма обнаружения данных. SQL Server 2005 Analysis Services включает в себя следующие девять алгоритмов:
- Дерево решений (Microsoft Decision Trees)
- Кластеризация (Microsoft Clustering)
- "Наивный" Байес (Microsoft Na?ve Bayes)
- Кластеризация последовательностей (Microsoft Sequence Clustering)
- Временные ряды (Microsoft Time Series)
- Ассоциативные правила (Microsoft Association)
- Нейронная сеть (Microsoft Neural Network)
- Линейная регрессия (Microsoft Linear Regression)
- Логистическая регрессия (Microsoft Logistic Regression)
Используя комбинацию этих алгоритмов можно создавать решения для большей части встречающихся задач по обнаружению скрытых закономерностей в больших объемах данных.
Наиболее важные шаги создания модели Data Mining состоят в получении, объединении, очистке и предобработке данных для дальнейшего использования алгоритмом. В состав SQL Server 2005 входят средства преобразования данных - SQL Server Integration Services (SSIS), которые позволяют объединять, очищать, проверять и проводить предварительную обработку данных.
Для демонстрации возможностей SQL Server мы будем использовать демо-проект AdventureWorksDW. Эта база включена в поставку SQL Server 2005 и спроектирована должным образом для работы с OLAP и моделями Data Mining. Чтобы эта база была доступна следует выбрать опцию установки этого проекта во время инсталляции SQL Server.
Проект Adventure Works
Проект AdventureWorksDW описывает работу производителя велосипедов - компании "Adventure Works Cycles". Компания занимается производством и реализацией велосипедов из металлических и композиционных материалов на территории Северной Америки, Европы и Азии. Головное производство, которое располагает 500 сотрудниками, находится в городе Bothell, штат Вашингтон. Несколько региональных офисов находятся непосредственно на территории рынков сбыта.
Компания реализует продукцию оптом для специализированных магазинов и в розницу через интернет. Для решения демонстрационных задач мы будем использовать в базе AdventureWorksDW данные об интернет продажах, поскольку они содержат данные, хорошо подходящие для анализа.
База данных
В базе интернет продаж содержатся сведения о 9 242 клиентах, которые живут в 6 странах, относящихся к трем регионам:
Данные относятся к периоду с 2002 по 2004 годы. Вся продукция классифицирована по категориям, моделям и товарам.
Среда разработки - Business Intelligence Development Studio
Среда разработки "Business Intelligence Development Studio" представляет собой интегрированную среду разработки для создания проектов анализа данных (business intelligence) и включает в себя множество инструментов. Она позволяет работать с моделями в отсоединенном от сервера режиме, а затем развертывать обновленный проект на сервере.
Можно отметить следующие преимущества работы в единой среде:
- Среда является мощным средством управления проектами
- Вы можете объединять несколько проектов в одно решение (solution) и использовать для них общее представление.
- Полная интеграция с системой хранения исходного кода позволяет удобно организовывать совместную работу над проектом.
Проект Analysis Services является центральным в решении business intelligence. Проект включает в себя модели Data Mining и кубы OLAP, а также вспомогательные объекты наполнения аналитической базы данных. Из студии можно создавать проекты анализа данных и развертывать их на множестве серверов.
При работе с ранее созданным проектом, который уже находится на сервере, можно работать с ним напрямую.
Среда управления - SQL Server Management Studio
Среда SQL Server Management Studio является оболочкой для множества административных функций для управления компонентами SQL Server. Эта среда отличается от Business Intelligence Development Studio в первую очередь тем, что изменения сохраняются на сервер в реальном времени.
После предварительной очистки и предобработки данных большая часть всех дальнейших действий по созданию модели выполняется в среде Business Intelligence Development Studio. В ней выполняются действия по созданию и проверке моделей, а также итеративное тестирование для выявления наиболее адекватной модели. После получения нужной модели ее можно развернуть на сервере. После этого фокус смещается с разработки на поддержку и использование модели для чего подходит SQL Server Management Studio. С ее помощью можно администрировать базу данных и выполнять просмотр и создание предсказаний аналогично тому, как это выполняется в среде Business Intelligence Development Studio
Сервисы интеграции - Integration Services
Integration Services (сервисы интеграции, SSIS) включают в себя средства получения (Extract), преобразования (Transform) и загрузки (Load) (ETL) данных из различных источников. Они используются для некоторых очень важных задач в проектах извлечения данных, таких как извлечение, объединение, очистка и предобработка данных, предшествующие созданию модели. В проектах извлечения данных и в процессе настройки моделей обычно необходимо проводить неоднократную предобработку и очистку данных. С помощью SSIS можно объединить задачи предобработки данных в единый пакет.
Среда SSIS содержит визуальный редактор, с помощью которого удобно создавать и отлаживать пакеты преобразования данных. Из него можно загрузить пакеты на сервер и настроить планировщик для их выполнения. Это удобно использовать, к примеру, для автоматической предобработки новых поступающих данных.
Алгоритмы Data Mining
Оглавление
Алгоритмы Data Mining являются основой для создания моделей. Набор алгоритмов Data Mining, входящих в SQL Server 2005, позволяют производить различные виды анализа данных.
Дерево решений - Microsoft Decision Trees
Алгоритм "Дерево решений" предназначен для решения задач классификации и регрессии и хорошо подходит для прогнозирования. В алгоритме Microsoft Decision Trees используются как дискретные, так и непрерывные атрибуты.
В процессе построения модели алгоритм итеративно вычисляет степень влияния каждого входного атрибута модели на значения выходного атрибута и использует атрибут, влияющий на выходную переменную в наибольшей степени для разбиения узла дерева решений. Узел верхнего уровня описывает распределение значений выходного атрибута по всей совокупности данных. Каждый последующий узел описывается распределением выходного атрибута при соблюдении условий на входные атрибуты, соответствующие этому узлу. Модель продолжает расти до тех пор, пока разбиение узла на последующие узлы увеличивает вероятность того, что выходной атрибут будет принимать какое-то определенное значение по сравнению со всеми другими значениями, т.е. разбиение увеличивает качество прогноза. Алгоритм осуществляет поиск атрибутов и их значений, разбиение по которым позволяет с большей вероятностью правильно предсказать значение выходного атрибута.
Кластеризация - Microsoft Clustering
Алгоритм кластеризации использует итеративный метод группировки записей набора данных в кластеры, обладающие сходными характеристиками. Используя разбиение на кластеры можно выявить в исследуемом массиве данных такие связи, которые невозможно обнаружить простым просмотром этих данных. Кроме того, с помощью алгоритмов кластеризации можно осуществлять прогнозирование. К примеру, объединить в группу людей, которые живут в одном районе, водят одну марку машин, имеют сходные предпочтения в пище и покупают один тип продукции. Такое объединение и есть кластер. Другой кластер может включать в себя людей, посещающих один ресторан, имеющих один уровень дохода и ездящих дважды в год в отпуск в другие страны. Оценивая распределение данных в этих кластерах, можно лучше понять взаимосвязи различных характеристик исследуемых объектов, а также как эти взаимосвязи влияют на значение прогнозируемого атрибута.
В Microsoft Analysis Services 2005 для кластеризации используется модификации алгоритмов максимизации ожидания (Expectation Maximization) и K-ближайших соседей (K-Means).
В первом случае каждый кластер характеризуется своей функцией распределения атрибутов входных данных, которые вычисляются в ходе итеративного процесса. В процессе выполнения алгоритма итеративно максимизируется функция правдоподобия на пространстве параметров функций распределения для каждого кластера. При этом предполагается, что непрерывные атрибуты имеют совместное многомерное нормальное распределение, а дискретные - совместное дискретное распределение.
Во втором случае итеративно минимизируется сумма квадратов расстояний (в различных метриках) от каждого элемента данных до центра соответствующего кластера.
Наивный алгоритм Байеса - Microsoft Na?ve Bayes
Наивный алгоритм Байеса предназначен для решения задач классификации и прогнозирования. В процессе его реализации вычисляются вероятности состояний входных атрибутов для каждого состояния выходного атрибута. Эти значения используются для вычисления вероятности того, что выходной атрибут принимает то или иное состояние при заданных значениях входных атрибутов. Алгоритм принимает только дискретные или дискретизированные атрибуты модели, а также исходит из предположения о стохастической независимости входных атрибутов ("наивность" алгоритма как раз обусловлена этими предположениями). Алгоритм Microsoft Na?ve Bayes представляет собой простую модель для анализа данных, которую можно рассматривать как средство первоначального разведочного анализа. Вследствие того, что большинство требуемой для построения модели информации вычисляется в процессе обработки соответствующего куба, результаты алгоритма Байеса возвращаются очень быстро. Это служит еще одним преимуществом использования алгоритма в качестве оптимального разведочного механизма для классификации и прогнозирования.
Временные ряды - Microsoft Time Series
Алгоритм Microsoft Time Series создает модели, предназначенные для прогнозирования значений непрерывных переменных по времени и использованием как OLAP, так и реляционных источников данных. Например, можно использовать этот алгоритм для прогнозирования объема продаж и прибыли по историческим данных в разрезе регионов продаж.
Алгоритм позволяет осуществлять прогнозирование по нескольким непрерывным переменным. Временной ряд должен характеризоваться временной характеристикой по которой осуществляется прогноз, а также может содержать произвольный набор других характеристик, разделяющий ряд на несколько (например, регион, продавца и т.д.).
Алгоритм Microsoft Time Series может анализировать и использовать корреляции между различными прогнозируемыми характеристиками. В этом случае результат прогнозирования будет зависеть не только от исторических значений той же переменной, но и значений других прогнозируемых переменных. Например, продажи в определенном магазине могут зависеть от прошлых продаж в другом магазине.
Алгоритм Microsoft Time Series является разновидностью алгоритмов ART (Autoregressive Trees - деревья авторегрессии). В процессе реализации алгоритма строится дерево решений, листьям которого соответствуют функции линейной регрессии.
Ассоциативные правила - Microsoft Association
Алгоритм Microsoft Association предназначен в первую очередь для анализа покупательских корзин. Анализируется каждая пара атрибут=значение (например продукт=велосипед) как значение некой логической переменной. Алгоритм сканирует транзакции в базе данных для определения "частых" наборов таких пар. Набор считается "частым" если его support (поддержка, т.е. число транзакций, в которые входит данный набор) превышает определенный порог. Например, частым набором может быть {Пол="мужской", Семейный статус = "женат", Возраст="30-35"}. Каждый набор имеет размер, например, в этом случае, он составляет 3.
Часто транзакции описываются вложенными таблицами, например, строками заказа продажи в заказе. В этом случае ключ вложенной таблицы служит названием атрибута, а факт его наличия - значением. Например {Товар("Велосипед")=existing, Товар("Велосипедная кепка")=existing}.
Алгоритм Microsoft Association помимо выявления частых набор предназначен для выявления правил вида A, B=>C, характеризуемых вероятностью выполнения (confidence), где {A, B}, {C} частые наборы. Символ '=>' означает, что появление набора C в транзакции можно предсказать из факта появления наборов A и B. Например, {Фотокамера=exisiting, Батарейки=existing}=>{Фотопленка=existing}. Порог значения вероятности соблюдения правила является параметром модели, определяющим факт рассмотрения каждого правила.
Ассоциативные правила используются для оптимизации кросс-продаж, целевых рекламных кампаний, определения политики скидок, в оптимизации размещения товаров на товарных полках в супермаркетах и т.д.
Кластеризация последовательностей действий - Microsoft Sequence Clustering
Алгоритм Microsoft Sequence Clustering анализирует последовательности каких-либо фактов, представляющих собой временные последовательности дискретных переменных. Обычно такие последовательности атрибутов рассматриваются как происхождение событий в определенном порядке (например, порядок просмотра страниц сайта). Алгоритм предназначен для прогнозирования наступления последующих событий на основании уже осуществленного перехода между состояниями.
Алгоритм Microsoft Sequence Clustering является гибридом алгоритма последовательностей действий и алгоритмом кластеризации. В процессе реализации алгоритма выполняется группировка последовательности переходов в типичные кластера, характеризующиеся паттернами переходов. Каждый из этих кластеров анализируется с точки зрения распределения вероятности переходов отдельно. Типичным сценарием использования для этого алгоритма является задача анализа клиентов web-портала. У web-портала имеется набор связанных доменов, таких как новости, погода, финансы, почта, спорт и т.д. Каждый web-посетитель характеризуется последовательностью "кликов" - переходов в рамках каждого из этих доменов. Алгоритм Microsoft Sequence Clustering может сгруппировать этих web-посетителей в более-менее однородные группы на основании их паттернов навигации по порталу. Эти группы могут быть визуализированы, обеспечивая представление шаблонов использования портала каждой группой посетителей.
В алгоритме используется алгоритм Expectation Maximization для выявления кластеров, а также Марковские процессы первого порядка для моделирования переходов между состояниями (событиями).
Нейронные сети - Microsoft Neural Network
Алгоритм Microsoft Neural Network предназначен для создания моделей классификации и регрессии путем конструирования многослойной нейронной сети перцептронов. Как и в случае алгоритма дерева решений, для каждого состояния выходного атрибута алгоритм вычисляет распределение вероятности входных атрибутов. Обрабатывается полный набор записей, при этом итеративно сравниваются предсказанные значения классификатора с известным значением. Ошибки классификации на первой итерации подаются на вход сети для изменения параметров на следующей итерации и т.д. Впоследствии, полученные вероятности используются для прогнозирования значения выходного атрибута на основании значений входных атрибутов. Одно из самых значительных отличий между этим алгоритмом и алгоритмом дерева решений состоит в том, что процесс обучения заключается в оптимизации параметров сети для минимизации ошибки классификации, в то время как алгоритм дерева решений осуществляет разбиение узлов для максимизации информации (минимизации энтропии). Алгоритм поддерживает как непрерывные так и дискретные типы атрибутов.
Линейная регрессия - Microsoft Linear Regression
Алгоритм Microsoft Linear Regression представляет собой алгоритм регрессии являющийся частным случаем алгоритма Microsoft Decision Trees, получаемый в случае запрета на разбиение узлов в дереве решений. Формула регрессии определена на всем объеме данных, т.е. на корневом узле дерева. Алгоритм предназначен для прогнозирования непрерывных атрибутов.
Логистическая регрессия - Microsoft Logistic Regression
Алгоритм Microsoft Logistic Regression представляет собой алгоритм регрессии являющийся частным случаем алгоритма Microsoft Neural Network, получаемый в случае удаления скрытого слоя нейросети. Алгоритм поддерживает прогнозирование значений как непрерывных, так и дискретных атрибутов.
Описание работы с курсом
В ходе данного курса вы будете работать в среде разработки Business Intelligence Development Studio (рис.1).
Крус разделено на три части: подготовка базы данных SQL Server, подготовка базы данных Analysis Services и построение и работа с моделями Data Mining.
Подготовка базы данных SQL Server
База данных AdventureWorksDW, которая используется в этом обзорном курсе, устанавливается вместе с SQL Server (по умолчанию эта опция отключена) и уже содержит представления (views), которые будут использованы для создания моделей.
В дополнения к ним необходимо будет импортировать в базу данных таблицу prospective customers (в виде плоского файла). Один из сценариев, который мы рассмотрим, анализирует целевые рассылки с использованием построителя запросов для прогнозов.
Импорт таблицы Prospective Customers
Вы будете использовать таблицу prospective customer в сценарии целевой рассылкидля проверки качества прогнозирования модели. Вы можете скачать эту таблицу с сайта Betaplace (www.Betaplace.com). Сначала необходимо импортировать плоский файл в базу данных AdventureWorksDW и назвать колонки этой таблицы так же как и в представлении, служащем источником данных для целевой рассылки.
В приложении А содержится сценарий импорта данных и переименования колонок. Загрузите плоский файл на ваш локальный диск. Запустите SQL Management Studio и откройте окно нового запроса к серверу БД AdventureWorksDW. Скопируйте SQL-запросы из приложения A в окно запросов. Измените значение переменной @data_path так, чтобы она содержала путь к файлу "Prospect.csv". Выполните запрос.
Будет создана таблица Prospects, которая будет содержать ту же структуру столбцов, как и представление vTargetedmail , за исключением следующих столбцов:
- Age
- Bike Buyer
- Region
Так же, ключи клиентов (CustomerKey, CustomerAlternateKey) заменены на ключи перспективных клиентов (ProspectKey, ProspectAlternateKey).
Подготовка базы данных Analysis Services
Прежде чем вы начнете создавать и работать с моделями Data Mining, вы должны выполнить следующие действия:
- Создать новый проект Analysis Services.
- Создать новый источник данных (data source).
- Создать новое представление данных (data source view).
Создание проекта Analysis Services
Каждый проект Analysis Services определяет схему объектов для единственной базы данных Analysis Services, которая описывается моделями Data Mining, OLAP-кубами и дополнительными объектами.
- Откройте Business Intelligence Development Studio.
- Выберете New и Project из меню File.
- Выберете проект Analysis Services в качестве типа нового проекта и назовите его AdventureWorks.
- Нажмите Ok.
Новый проект откроется в Business Intelligence Development Studio.
Создание источника данных
Источник данных - это данные о соединении с внешним источником данных, которые хранятся в проекте и в базе данных Analysis Services. В источнике данных хранится информация об имени сервера, базы данных, где хранится информация, используемая в проекте, а так же другие свойства соединения.
- Правой кнопкой мыши щелкните по узлу Data Source вашего решения и выберете New Data Source.
- На первой странице мастера выберете Next.
- Щелкните New чтобы добавить соединение к базе данных AdventureWorksDW.
- В диалоговом окне Connection Manager выберете провайдер данных Microsoft OLE DB Provider for SQL Server, имя сервера - AdventureWorksDW, введите данные о пользователе, под учетной записью которого будет производиться соединение.
- Щелкните OK.
- Щелкните Next.
По умолчанию источник данных будет назван Adventure Works DW. Щелкните Finish
Новый источник данных Adventure Works DW появится в папке источников данных в дереве решения.
Создание представления данных
Представление данных (Data Source View) обеспечивает уровень абстракции для источника данных, позволяя вам менять структуру исходных данных для удобства вашего проекта. Используя представление данных, вы можете выбрать только относящиеся к вашему проекту таблицы и представления, определить связи между таблицами, добавить вычисляемые поля, а также именованные запросы без необходимости вносить модификации в исходные данные.
- В дереве решения щелкните правой кнопкой мыши на Data Source View и выберете New Data Source View.
- На первой странице щелкните Next.
- Выберете источник данных Adventure Works DW, который вы создали на прошлом шаге в окне Relational data sources. Нажмите Next.
- Если вы хотите создать новый источник данных, нажмите New Data Source.
- Выберете таблицы из списка нажмите на правую стрелку для включения их в представление данных:
- Prospect
- vAssocSeqLineItems
- vAssocSeqOrders
- vTargetMail
- vTimeSeries
- Нажмите Next.
- По умолчанию представление данных будет названо Adventure Works DW. Нажмите Finish.
Откроется окно представления данных как показано на рис. 2. Далее можно производить изменения в представлении источника данных.
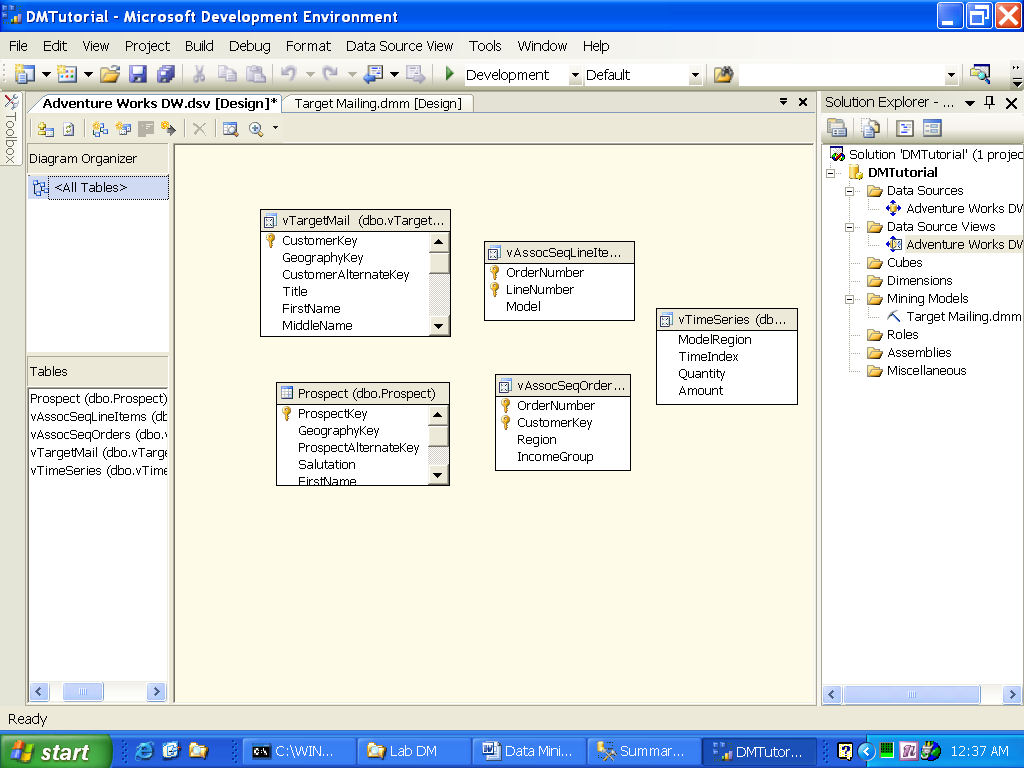
Редактирование представления источника данных
Используя редактор представления источника данных (Data Source View Editor), вы можете вносить изменения в представление данных. Например, вы можете переименовать объект, если его новое название будет больше подходить к модели. При этом оригинальное название не изменится, но появится возможность обращаться к объекту через новое более удобное имя.
Для создания сценариев анализа рыночной корзины или кластеризации последовательностей необходимо создать новое соединение многие-к-одному между vAssocSeqOrders и vAssocSeqLineItems. Используя эту связь можно сделать vAssocSeqLineItems вложенной таблицей по отношению к vAssocSeqOrders, что необходимо для создания модели.
- В окне просмотра выбрать поле OrderNumber из таблицы vAssocSeqLineItems
- Перенести выбранную колонку в таблицу vAssocSeqOrders и поместить ее на колонку OrderNumber
Новая связь многие-к-одному между vAssocSeqOrders и vAssocSeqLineItems создадна.
Построение и работа с моделями Data Mining
Редактор Data Mining (показан на рисунке 4) содержит все инструменты и средства отображения для построения и работы с моделями Data Mining. Дополнительная информация по редактору доступна в разделе "Using the Data Mining Tools" в SQL Server Books Online.
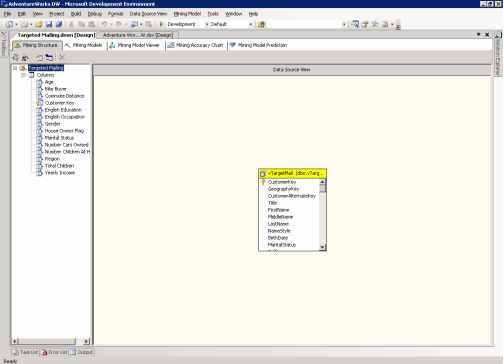
На протяжении этого руководства вы будете работать со следующими сценариями:
- Целевая отправка писем (Targeted mailing)
- Прогнозирование (Forecasting)
- Рыночная корзина (Market basket)
- Кластеризация последовательностей (Sequence clustering)
В сценарии Целевая отправка писем вы будете заниматься построением моделей, сравнением их ожидаемых возможностей (при помощи окна Mining Accuracy Chart), а также созданием прогнозов с использованием Prediction Query Builder.
Адресная рассылка
Кроме того, отдел маркетинга намеревается выявить логические группы среди уже существующих в их базе данных клиентов. Например, группа может содержать покупателей, объединённых по демографическому признаку, обладающих схожим набором покупок.
Adventure Works располагает списком как бывших, так и потенциальных клиентов.
В процессе решения этой задачи, отделу маркетинга потребуется выполнить следующие действия:
- Установить модели, способные выявить наиболее вероятных клиентов из списка потенциальных покупателей
- Кластеризовать своих существующих клиентов
Для выполнения этого сценария вам потребуется использовать Microsoft Na?ve Bayes, Microsoft Decision Trees, и Microsoft Clustering алгоритмы. Сценарий содержит в себе 5 задач:
Описание структуры модели Data Mining
- В Solution Explorer кликните правой кнопкой мыши на Mining Models, выберите New Mining Model. Откроется Mining Model Wizard.
- Нажмите Next на странице приветствия.
- Выберите From existing relational database or data warehouse, затем Next.
- В разделе Which data mining technique do you want to use? выберите Microsoft Decision Trees. Вы создадите несколько моделей, опирающихся на эту начальную структуру, в основе которой лежит алгоритм Microsoft Decision Trees.
- Нажмите Next. По умолчанию в качестве источника данных здесь выбран Adventure Works DW.
- Нажмите Next.
- Пометьте флагом Case таблицу vTargetMail, затем нажмите Next.
- Пометьте флагом Key столбец CustomerKey. Если в исходной таблице присутствует ключевое поле, Mining Model Wizard автоматически выберет его в качестве ключевого для модели.
- Пометьте флагом Input и Predictable столбец BikeBuyer. В результате столбец становится доступным для прогнозирования в новых наборах данных. После того как вы помечаете столбец подобным образом, становится доступной кнопка Suggest. Нажатие на эту кнопку вызывает диалоговое окно со списком наиболее связанных с данным полем столбцов, расположенных в порядке корреляции с прогнозируемым. Столбцы со значением больше 0.05 автоматически добавляются в модель. Если вы согласны с предлагаемым вариантом, нажмите кнопку OK или определите нужные поля вручную.
- Пометьте флагом Input столбцы, перечисленные в таблице.
| Age | YearlyIncome | Region |
|---|---|---|
| CommuteDistance | HouseOwnerFlag | TotalChildren |
| EnglishEducation | LastName | |
| EnglishOccupation | MaritalStatus | |
| FirstName | NumberCarsOwned | |
| Gender | NumberChildrenAtHome |
Вы можете выбрать несколько столбцов, удерживая клавишу SHIFT.
- Нажмите Next.
- В поле Specify Columns' Content and Data Type нажмите Detect. При этом автоматически определяется, содержат ли столбцы с численными данными дискретные, либо непрерывные значения. Например, столбец может содержать информацию о заработной плате с непосредственными значениями сумм (непрерывные значения) или в нём могут содержаться целые числа, отвечающие неким диапазонам значений (1 = <$25,000; 2 = от $25,000 до $50000 и так далее), то есть дискретные значения.
- В поле Structure Name введите Targeted Mailing и нажмите Finish
- Нажмите Finish. При этом откроется редактор Data mining, отображающий структуру Targeted Mailing, которую вы только что создали, см. Рисунок 5.

Рисунок 5 Страница структуры Targeted Mailing
Редактирование Data Mining моделей
- Нажмите на закладку Mining Models.
- Кликните правой кнопкой по Targeted Mailing и выберите New Mining Model.
- В поле Model Name введите TM_Clustering.
- В поле Alogithm Name выберите Microsoft Clustering.
- Нажмите OK.
Новая модель появится на странице Mining Models. Модель Microsoft Clustering позволяет группировать и прогнозировать непрерывные и дискретные атрибуты. Вы можете изменить используемые столбцы и свойства для новой модели.
Установка столбца как Predict (прогнозируемого) не оказывает никакого эффекта на этапе обучения модели; но позволяет вам указать этот столбец в запросе на прогнозирование PREDICTION JOIN. При создании кластеров алгоритм игнорирует столбцы, помеченные как PredictOnly. Статистика для PredictOnly столбцов в кластерной модели определяется на финальном шаге, после того как операция кластеризации завершена. Это имеет смысл, если вы хотите видеть распределение атрибута по кластерам, созданным на основании других атрибутов и позволяет выявить более глубокие взаимосвязи.
- Кликните правой кнопкой по Targeted Mailing и выберите New Mining Model.
- В поле Model Name введите TM_NaiveBayes.
- В поле Algorithm Name выберите Microsoft Na?ve Bayes. После чего появится диалоговое окно с текстом, объясняющим, что алгоритм Microsoft Na?ve Bayes не поддерживает работу с столбцами Age, Geography Key и Yearly Income, содержащими непрерывные значения, и они будут проигнорированы.
- Нажмите Yes.
- Нажмите OK.
- После чего, новая модель появится на странице Mining Models. Хотя вы можете менять используемые столбцы и свойства для всех моделей на этой странице, в данном случае оставьте всё без изменений.
Обработка Data Mining моделей
Теперь, после того как структура и параметры моделей определены, вы можете осуществить развёртывание и обработку моделей.
- Нажмите F5.
Теперь база данных Analysis Services выложена на сервер и модели обработаны. Если база данных уже была на сервере, вы можете осуществить только обработку моделей, следуя следующему алгоритму.
- В меню Mining Model выберите пункт Process All Models.Откроется диалоговое окно Process Targeted Mailing.
- Нажмите Run.
- Откроется диалоговое окно Process Progress, отображающее информацию об обработке модели. В зависимости от производительности вашего компьютера, процесс может занять некоторое время.
- После того как завершится обработка, закройте оба диалоговых окна.