
Автор: Владимир Паранин ©
В этой статье рассказывается о том, что Вам нужно сделать, чтобы подготовить свой код к Delphi 2009.
В Части I этой серии было сказано, что Delphi 2009 по умолчанию будет использовать строку, основанную на UTF-16. В результате некоторые части существующего кода могут потребовать изменений. В основном, большая часть существующего кода будет прекрасно работать в Delphi 2009. Как Вы увидите, основные изменения в коде касаются только очень специфических, даже эзотерических, моментов. Как бы там ни было, нужно рассмотреть те особые части кода, которые, скорее всего, придется редактировать. Также нужно будет проверить результаты работы такого кода, чтобы убедиться, что он правильно работает с UnicodeString.
Например, любой код, работающий со строками и выполняющий операции с указателями на них, должен быть изучен на совместимость с Юникодом. Говоря более конкретно, любой код:
<!--[if !supportLists]-->· <!--[endif]-->считающий, что SizeOf(Char)=1;
<!--[if !supportLists]-->· <!--[endif]-->считающий, что длина строки равна количеству байт в строке;
<!--[if !supportLists]-->· <!--[endif]-->который пишет и читает строки из какого-либо постоянного хранилища или использует строку как буфер для данных
должен быть проанализирован, чтобы убедиться, что эти особенности не влияют на работу. Код, который пишет и читает из какого-либо постоянного хранилища, должен быть проверен на то, что считывается или пишется правильное количество байт, так как один байт больше не является одним символом.
Как правило, любые изменения в коде являются достаточно простыми и могут быть сделаны с минимальными усилиями.
Части, которые должны "работать прямо так"
Здесь рассказывается о тех частях кода, которые будут продолжать работать и не потребуют никаких изменений для корректной работы с новой UnicodeString. VCL и RTL были полностью обновлены, чтобы работать в Delphi 2009 так, как и всегда. С маленькими-маленькими оговорками так оно и есть. К примеру, TStringList теперь полностью поддерживает Юникод, и весь существующий код, в котором используется TStringList, должен работать так же, как и раньше. Кроме того, TStringList был улучшен для работы специально с Юникодом, поэтому если Вы хотите использовать новую функциональность, Вы можете это сделать, но если это Вам не нужно - можете вообще о ней не думать.
Обычное использование строковых типов
В основном, код, использующий строковый тип, будет работать, как и прежде. Нет необходимости переобъявлять строковые переменные в тип AnsiString, за исключением тех случаев, которые описаны ниже. Объявления строк должны быть изменены на AnsiString во всех местах, где строки используются в качестве буфера для данных.
Runtime Library
Дополнения к Runtime Library были подробно рассмотрены в Части II.
В той статье не упоминался новый модуль, добавленный в RTL - AnsiString.pas. Этот модуль существует для обратной совместимости с кодом, который использует или требует для своей работы AnsiString.
Код Runtime Library выполняется как обычно, и в основном не требует изменений. Части, которые нужно изменить, описаны ниже.
VCL
Вся VCL поддерживает Юникод. Все существующие VCL-компоненты работают с момента установки, как всегда и было. Практически весь код, использующий VCL, будет нормально работать. Мы проделали огромную работу, чтобы быть уверенными, что VCL совместим как со старым кодом, так и с Юникодом. Обычный VCL-код, не выполняющий никаких особенных манипуляций со строками, будет работать как и раньше.
Индексация в строках
Индексация в строках работает точно так же, как и прежде, поэтому код, индексирующий элементы строк, не требует изменений:
var
S: string;
C: Char;
begin
S := "This is a string";
C := S[1]; // C будет содержать "T", но C это, конечно же, WideChar
end;
Length/Copy/Delete/SizeOf длястрок
Функция Copy будет работать, как всегда, без изменений. То же самое относится к Delete и всем остальным процедурам работы со строками, основанными на SysUtils.
Вызов Length(SomeString), как и всегда, вернет количество элементов в переданной строке.
Вызов SizeOf для любого идентификатора строки вернет 4, так как все строковые объявления - это ссылки и размер указателя равен 4.
Вызов Length для любой строки вернет количество элементов в этой строке.
Рассмотрим следующий код:
var
S: string;
begin
S:= 'abcdefghijklmnopqrstuvwxyz';
WriteLn('Length = ', Length(S));
WriteLn('SizeOf = ', SizeOf(S));
WriteLn('TotalBytes = ', Length(S) * SizeOf(S[1]));
ReadLn;
end.
В результате его выполнения будет выведено следующее:
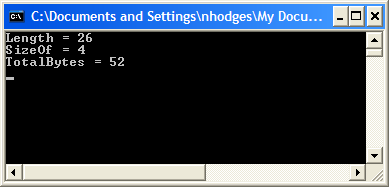
<!--[if !vml]--><!--[endif]-->
Работа с указателями для PChar
Работа с указателями для PChar будет выполняться, как и раньше. Компилятору известен размер PChar, поэтому код, подобный приведенному ниже, будет работать, как и ожидается:
var
p: PChar;
MyString: string;
begin
...
p := @MyString[1];
Inc(p);
...
end;
Этот код будет работать точно так же, как и в предыдущих версиях Delphi, но, конечно, с другими типами данных: PChar это теперь PWideChar и MyString - это теперь UnicodeString.
ShortString
ShortString осталась неизменной, как по функциям, так и по объявлению, она будет работать, как и раньше.
Объявления ShortString выделяют буфер для заданного количества AnsiChar"ов. Такой код:
var
S: string[26];
begin
S:= 'abcdefghijklmnopqrstuvwxyz';
WriteLn('Length = ', Length(S));
WriteLn('SizeOf = ', SizeOf(S));
WriteLn('TotalBytes = ', Length(S) * SizeOf(S[1]));
ReadLn;
end.
выведет на экран следующее:
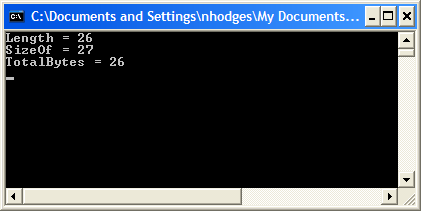
<!--[if !vml]--><!--[endif]-->
Обратите внимание, что общий размер алфавита - 26, это говорит о том, что переменная содержит AnsiChar"ы.
Рассмотрим также и такой код:
type
TMyRecord = record
String1: string[20];
String2: string[15];
end;
Это запись будет расположена в памяти точно так же, так и раньше - это будет запись из двух AnsiString"ов, содержащих AnsiChar"ы. Если у Вас есть File of Rec из записей, содержащих ShortString"и, то приведенный выше код будет работать, как и раньше, и любое чтение или запись не потребует никаких изменений.
Однако помните, что Char - это теперь WideChar, поэтому если Вы используете код, который читает такие записи из файла и потом делаете что-то вроде:
var
MyRec: TMyRecord;
SomeChar: Char;
begin
// Чтение MyRec из файла...
SomeChar := MyRec.String1[3];
...
end;
то Вы должны помнить, что SomeChar превратит AnsiChar в String1[3] в WideChar. Если Вам нужно, чтобы этот код работал, как раньше, измените объявление SomeChar:
var
MyRec: TMyRecord;
SomeChar: AnsiChar; // Теперь объявлен как AnsiChar для символа из ShortString
begin
// Чтение MyRec из файла...
SomeChar := MyRec.String1[3];
...
end;
Части, которые должны быть проверены
В этой части статьи описаны различные конструкции, которые должны быть проверены в существующем коде для совместимости с Юникодом. Поскольку Char теперь является WideChar, данные о байтовом размере символьного массива или строки могут быть неверными. Ниже приведены несколько примеров конструкций кода, которые нужно изучить, чтобы убедиться в их совместимости с новым типом UnicodeString.
SaveToFile/LoadFromFile
Вызовы SaveToFile и LoadFromFile можно было бы отнести к предыдущей части статьи (Части, которые должны "работать прямо так"), если бы они выполняли чтение и запись так же, как они делали это раньше. Однако Вам может понадобиться использование новых перегруженных версий этих процедур, если Вы решили работать с Юникод-данными.
К примеру, TStrings теперь включает следующий набор перегруженных методов:
procedure SaveToFile(const FileName: string); overload; virtual;
procedure SaveToFile(const FileName: string; Encoding: TEncoding); overload; virtual;
Второй метод - это новая перегрузка, принимающая кодировку в качестве параметра, который задает, каким образом данные будут записаны в файл. (В Части II Вы можете прочитать описание типа TEncoding.) Если Вы вызовете первый метод, строковые данные будут записаны так же, как это делалось обычно - как ANSI-данные. Благодаря этому уже существующий код будет работать точно так же, как и всегда.
Однако если Вам нужно записать текст в формате Юникод, то нужно вызвать второй вариант метода, передав ему в параметре соответствующее значение типа TEncoding. Если не сделать этого, строки будут записаны как ANSI-данные, что, скорее всего, приведет к потере информации.
Таким образом, наилучший способ в этом случае - проанализировать вызовы SaveToFile и LoadFromFile и добавить к ним второй параметр, чтобы показать, каким образом нужно сохранить или загрузить данные. Если Вы считаете, что никогда не будете добавлять или использовать Юникод-строки, то можете оставить все, как есть.
Использование функции Chr
Существующий код, превращающий значение типа integer в Char может использовать функцию Chr. Это может привести к следующей ошибке:
[DCC Error] PasParser.pas(169): E2010 Incompatible types: 'AnsiChar' and 'Char'
Если в коде, использующем функцию Chr, имеется присвоение ее результата переменной типа AnsiChar, то эту ошибку можно легко исключить, заменив функцию Chr преобразованием в тип AnsiChar.
То есть, такой код:
MyChar := chr(i);
можно заменить таким:
MyChar := AnsiChar(i);
Символьные множества
Наверное, самой распространенной идиомой, которая может создать проблемы компилятору, является использование символов в множествах. Раньше, когда символ занимал один байт, хранение символов в множествах не создавало никаких трудностей. Но теперь Char объявлен как WideChar, и поэтому больше не может храниться в множестве. Поэтому, если у Вас есть код наподобие этого:
procedure TDemoForm.Button1Click(Sender: TObject);
var
C: Char;
begin
C := Edit1.Text[1];
if C in ['a'..'z', 'A'..'Z'] then
begin
Label1.Caption := 'It is there';
end;
end;
и Вы скомпилируете его, то получите предупреждение, которое будет выглядеть примерно так:
[DCC Warning] Unit1.pas(40): W1050 WideChar reduced to byte char in set expressions. Consider using 'CharInSet' function in 'SysUtils' unit.
Если хотите, можете оставить код неименным - компилятор будет "знать", что Вы пытаетесь сделать и сгенерирует правильный код. Однако, если Вы хотите избавиться от этого предупреждения, то можете использовать новую функцию CharInSet:
if CharInSet(C, ['a'..'z', 'A'..'Z']) then
begin
Label1.Caption := 'It is there';
end;
Функция CharInSet вернет булевское значение и код скомпилируется без предупреждений компилятора.
Использование строк в качестве буферов данных
Часто при работе с данными строки используются как буферы. Это делается часто, потому что это просто - работа со строками проста и понятна. Однако, существующий код, который так делает, в большинстве случаев потребует дополнительной настройки, исходя из того, что string это теперь UnicodeString.
Есть несколько способов разобраться с кодом, который использует строки как буферы данных. Первый - это просто объявить переменную, используемую в качестве буфера, как AnsiString вместо string. Если для работы с байтами буфера в коде используются Char"ы - объявите эти переменные как AnsiChar. Если Вы выберете этот путь, весь Ваш код будет работать, как и прежде, но Вы должны помнить: все переменные, работающие с таким строковым буфером, должны быть ANSI-типа.
Второй, более верный путь, - это преобразовать Ваш буфер из строкового типа в массив байтов или TBytes. Тип TBytes был создан специально для этой цели и работает так же, как и раньше, если использовался тип string.
Вызов SizeOf для буферов
Вызов SizeOf при использовании символьных массивов должен быть проверен на корректность. Рассмотрим следующий код:
procedure TDemoForm.Button1Click(Sender: TObject);
var
var
P: array[0..16] of Char;
begin
StrPCopy(P, 'This is a string');
Memo1.Lines.Add('Length of P is ' + IntToStr(Length(P)));
Memo1.Lines.Add('Size of P is ' + IntToStr(SizeOf(P)));
end;
Вот что этот код выведет в Memo1:
Length of P is 17
Size of P is 34
В этом коде Length вернет количество символов в данной строке (плюс терминальный символ), а SizeOf вернет количество байтов, использованных этим массивом, в данном случае 34, то есть по два байта на символ. В предыдущих версиях Delphi этот код вернул бы 17 в обоих случаях.
Использование FillChar
Вызов FillChar также нужно проверить при работе со строками и символами. Рассмотрим следующий код:
var
Count: Integer;
Buffer: array[0..255] of Char;
begin
// Существующий код - неправильный, потому что string = UnicodeString
Count := Length(Buffer);
FillChar(Buffer, Count, 0);
// Правильный код для Юникода - любой из вариантов верный
Count := SizeOf(Buffer); // <<-- Задание размера буфера в байтах
Count := Length(Buffer) * SizeOf(Char); // <<-- Задание размера буфера в байтах
FillChar(Buffer, Count, 0);
end;
Length возвращает размер в символах, но FillChar ожидает, что Count будет в байтах. В этом случае вместо Length нужно использовать SizeOf (или нужно умножить Length на размер Char).
Кроме того, так как по умолчанию размер Char равен 2, FillChar заполнит строку байтами, а не символами, как раньше.
Пример:
var
Buf: array[0..32] of Char;
begin
FillChar(Buf, Length(Buf), #9);
end;
Это заполнит массив символами с кодом не $09, а $0909. Чтобы получить прежний результат, код нужно изменить:
var
Buf: array[0..32] of Char;
begin
..
StrPCopy(Buf, StringOfChar(#9, Length(Buf)));
..
end;
Использование буквенных символов
Следующий код
if Edit1.Text[1] = #128 then
распознает символ Евро и в итоге даст True в большинстве кодовых страниц ANSI. Однако в Delphi 2009 он даст False, так как #128 - это символ Евро в большинстве ANSI-страниц, а в Юникоде это - управляющий символ. В Юникоде символом Евро имеет код #$20AC.
При переходе на Delphi 2009 разработчикам следует заменить все коды символов со #128 по #255 на их буквенные значения, тогда:
if Edit1.Text[1] = '€' then
будет работать так же, как #128 в ANSI, но будет нормально функционировать (то есть распознавать символ Евро) в Delphi 2009 (где '€' имеет код #$20AC)
Использование Move
Следует проанализировать использование функции Move при работе со строками или символьными массивами. Рассмотрим следующий код:
var
Count: Integer;
Buf1, Buf2: array[0..255] of Char;
begin
// Существующий код - неправильный, потому что string = UnicodeString
Count := Length(Buf1);
Move(Buf1, Buf2, Count);
// Правильный код для Юникода
Count := SizeOf(Buf1); // <<-- Задание размера буфера в байтах
Count := Length(Buf1) * SizeOf(Char); // <<-- Задание размера буфера в байтах
Move(Buf1, Buf2, Count);
end;
Length возвращает размер в символах, но Move ожидает, что Count будет в байтах. В этом случае вместо Length нужно использовать SizeOf (или нужно умножить Length на размер Char).
Методы Read/ReadBuffer для TStream
Вызов TStream.Read/ReadBuffer также следует рассмотреть, если используются строки или символьные массивы. Рассмотрим следующий код:
var
S: string;
L: Integer;
Stream: TStream;
Temp: AnsiString;
begin
// Существующий код - неправильный, потому что string = UnicodeString
Stream.Read(L, SizeOf(Integer));
SetLength(S, L);
Stream.Read(Pointer(S)^, L);
// Правильный код для Юникод-данных
Stream.Read(L, SizeOf(Integer));
SetLength(S, L);
Stream.Read(Pointer(S)^, L * SizeOf(Char)); // <<-- Задание размера буфера в байтах
// Правильный код для ANSI-данных
Stream.Read(L, SizeOf(Integer));
SetLength(Temp, L); // <<-- Используем временную AnsiString
Stream.Read(Pointer(Temp)^, L * SizeOf(AnsiChar)); // <<-- Задание размера буфера в байтах
S := Temp; // <<-- Расширим строку до Юникода
end;
Примечание: работа зависит от формата читаемых данных. Смотрите описание нового класса TEncoding, приведенное выше, для получения сведений о правильном кодировании текста в Stream"е.
Write/WriteBuffer
Как и в случае Read/ReadBuffer, использование TStream.Write/WriteBuffer следует проверить, если используются строки или символьные массивы. Рассмотрим следующий код:
var
S: string;
Stream: TStream;
Temp: AnsiString;
begin
// Существующий код - неправильный, потому что string = UnicodeString
Stream.Write(Pointer(S)^, Length(S));
// Правильный код для Юникод-данных
Stream.Write(Pointer(S)^, Length(S) * SizeOf(Char)); // <<-- Задание размера буфера в байтах
// Правильный код для ANSI-данных
Temp := S; // <<-- Используем временную AnsiString
Stream.Write(Pointer(Temp)^, Length(Temp) * SizeOf(AnsiChar));// <<-- Задание размера буфера в байтах
end;
Примечание: работа зависит от формата читаемых данных. Смотрите описание нового класса TEncoding, приведенное выше, для получения сведений о правильном кодировании текста в Stream"е.
LeadBytes
Замените такой код:
if Str[I] in LeadBytes then
использованием функции IsLeadChar:
if IsLeadChar(Str[I]) then
TMemoryStream
В тех случаях, когда для записи текста в файл используется TMemoryStream, важной является запись Byte Order Mark (BOM) в качестве начальных данных файла. Вот пример записи BOM в файл:
var
BOM: TBytes;
begin
...
BOM := TEncoding.UTF8.GetPreamble;
Write(BOM[0], Length(BOM));
Весь пишущий код должен быть изменен на работу в кодировке UTF8 для Юникод-строк:
var
Temp: Utf8String;
begin
...
Temp := Utf8Encode(Str); // <-- Str - это строка, записываемая в файл
Write(Pointer(Temp)^, Length(Temp));
//Write(Pointer(Str)^, Length(Str)); <-- это оригинальный вызов Write для записи строки в файл
TStringStream
TStringStream теперь происходит от нового типа TByteStream. TByteStream добавляет свойство Bytes, дающее прямой доступ к байтам из TStringStream. TStringStream продолжает работать, как и всегда, за исключением того, что строка, которую он хранит, теперь является Юникод-строкой.
MultiByteToWideChar
Вызовы MultiByteToWideChar можно просто убрать и заменить простым присвоением. Пример использования MultiByteToWideChar:
procedure TWideCharStrList.AddString(const S: string);
var
Size, D: Integer;
begin
Size := SizeOf(S);
D := (Size + 1) * SizeOf(WideChar);
FList[FUsed] := AllocMem(D);
MultiByteToWideChar(0, 0, PChar(S), Size, FList[FUsed], D);
Inc(FUsed);
end;
А после перехода к Юникоду этот код был изменен, чтобы компилироваться как для ANSI, так и для Юникода:
procedure TWideCharStrList.AddString(const S: string);
var
L, D: Integer;
begin
FList[FUsed] := StrNew(PWideChar(S));
Inc(FUsed);
end;
SysUtils.AppendStr
Этот метод может использовать только AnsiString, нет его перегруженной версии для UnicodeString.
Замените вызовы вроде этого:
AppendStr(String1, String2);
таким кодом:
String1 := String1 + String2;
Или, еще лучше, используйте новый класс TStringBuilder для соединения строк.
GetProcAddress
При вызове GetProcAddress всегда следует использовать PAnsiChar (в SDK нет функции с суффиксом "W"). Например:
procedure CallLibraryProc(const LibraryName, ProcName: string);
var
Handle: THandle;
RegisterProc: function: HResult stdcall;
begin
Handle := LoadOleControlLibrary(LibraryName, True);
@RegisterProc := GetProcAddress(Handle, PAnsiChar(AnsiString(ProcName)));
end;
Примечание: Windows.pas содержит перегруженный метод, который выполняет это преобразование.
Использование преобразований к PChar() для работы с указателями при указании на не символьные типы
В предыдущих версиях не все типизированные указатели поддерживали арифметические операции. Из-за этого для выполнения арифметических операций над такими указателями они преобразовывались к PChar. В Delphi 2009 арифметика для указателей может быть включена директивой компилятора и она специально включена для типа PByte. Таким образом, если у Вас есть подобный код, преобразующий указатель к PChar для выполнения арифметических операций над ним:
function TCustomVirtualStringTree.InternalData(Node: PVirtualNode): Pointer;
begin
if (Node = FRoot) or (Node = nil) then
Result := nil
else
Result := PChar(Node) + FInternalDataOffset;
end;
Вы должны заменить его использованием PByte вместо PChar:
function TCustomVirtualStringTree.InternalData(Node: PVirtualNode): Pointer;
begin
if (Node = FRoot) or (Node = nil) then
Result := nil
else
Result := PByte(Node) + FInternalDataOffset;
end;
В приведенном выше куске кода Node не содержит символьных данных. Он преобразовывается к PChar только для доступа к данным, расположенным через заданное число байт после Node. Раньше это работало, так как SizeOf(Char) = SizeOf(Byte). Теперь это работать не будет. Чтобы сделать работу кода правильной, следует использовать PByte вместо PChar. Если оставить все без изменений, Result будет указывать на некорректные данные.
Параметры с вариантными массивами
Если Ваш код использует TVarRec для работы с параметром - вариантным массивом - возможно, Вам придется отредактировать его для работы с UnicodeString. Для этого теперь есть новый тип vtUnicodeString, хранящий данные из UnicodeString. Рассмотрим следующий кусок из DesignIntf.pas, показывающий, в каком случае следует добавить новый код для работы с UnicodeString.
procedure RegisterPropertiesInCategory(const CategoryName: string;
const Filters: array of const); overload;
var
I: Integer;
begin
if Assigned(RegisterPropertyInCategoryProc) then
for I := Low(Filters) to High(Filters) do
with Filters[I] do
case vType of
vtPointer:
RegisterPropertyInCategoryProc(CategoryName, nil,
PTypeInfo(vPointer), );
vtClass:
RegisterPropertyInCategoryProc(CategoryName, vClass, nil, );
vtAnsiString:
RegisterPropertyInCategoryProc(CategoryName, nil, nil,
string(vAnsiString));
vtUnicodeString:
RegisterPropertyInCategoryProc(CategoryName, nil, nil,
string(vUnicodeString));
else
raise Exception.CreateResFmt(@sInvalidFilter, [I, vType]);
end;
end;
CreateProcessW
Юникод-версия CreateProcess (CreateProcessW) работает немного иначе, нежели ANSI-версия. Цитата MSDN из описания параметра lpCommandLine:
"Юникод-версия это функции, CreateProcessW, может изменить содержимое этой строки. Таким образом, этот параметр не может указывать на память только-для-чтения (то есть быть константной переменной или символьной строкой). Если этой параметр - константа, функция может вызвать ошибку доступа."
Из-за этого существующий код, вызывающий CreateProcess, может начать выдавать ошибки доступа (Access Violations) после компиляции в Delphi 2009.
Примеры такого кода:
Передача строковой константы
CreateProcess(nil, 'foo.exe', nil, nil, False, 0, nil, nil, StartupInfo, ProcessInfo);
Передача константного выражения
const
cMyExe = 'foo.exe'
begin
CreateProcess(nil, cMyExe, nil, nil, False, 0, nil, nil, StartupInfo, ProcessInfo);
end;
Передача строки с числом ссылок (Reference Count) -1:
const
cMyExe = 'foo.exe'
var
sMyExe: string;
begin
sMyExe := cMyExe;
CreateProcess(nil, PChar(sMyExe), nil, nil, False, 0, nil, nil, StartupInfo, ProcessInfo);
end;
Код для проверки
Вот список возможных мест в коде, которые Вам следует найти, чтобы проверить, готов ли Ваш код к правильному использованию Юникода:
<!--[if !supportLists]-->· <!--[endif]-->найти любое использование "of Char" или "of AnsiChar", чтобы проверить, что буферы корректно работают с Юникодом;
<!--[if !supportLists]-->· <!--[endif]-->найти "string[" и проверить, что символ, полученный по ссылке, заносится в Char (то есть в WideChar).
<!--[if !supportLists]-->· <!--[endif]-->проверить неявную работу с AnsiString, AnsiChar и PAnsiChar, убедиться, что она по-прежнему нужна и правильно работает;
<!--[if !supportLists]-->· <!--[endif]-->найти неявное использование ShortString, убедиться, что оно по-прежнему требуется и правильно работает;
<!--[if !supportLists]-->· <!--[endif]-->найти вызовы Length( и проверить, чтобы там не подразумевалось, что Length это то же самое, что SizeOf;
<!--[if !supportLists]-->· <!--[endif]-->найти вызовы Copy(, Seek(, Pointer(, AllocMem( и GetMem( и проверить, чтобы они правильно работали со строками или символьными массивами.
Это типичные конструкции, которые, возможно, придется изменить для поддержки нового типа UnicodeString.
Заключение
Вот и все потенциально узкие места в коде, которые нужно проверить на правильность для жизни в мире Юникода. Большая часть Вашего кода по-прежнему будет работоспособной. Большинство предупреждений, которые получит Ваш код от компилятора, можно легко исправить. Значительная часть моментов, которые нужно проверить, встречается достаточно редко, поэтому практически весь Ваш код будет работать просто прекрасно.