
Несмотря на постоянное развитие информационных технологий, практика обеспечения информационной безопасности в российских компаниях насыщена примерами инцидентов в этой области. Более того, число инцидентов неуклонно растет и начинает вызывать определенное беспокойство у начальников служб автоматизации (CIO) и служб информационной безопасности (CISO), ответственных за организацию информационной безопасности ERP-систем в отечественных компаниях. Давайте посмотрим, какие возможности существуют для мониторинга безопасности ERP Oracle E-Business Suite.
Приведем классический вариант построения ERP Oracle E-Business Suite по схеме "база данных - сервер приложений - "тонкий" клиент". Три основных компонента этой системы соединены между собой с помощью сети передачи данных на основе TCP/IP (рис. 1). В этом случае браузер или какая-либо другая программа, выполняющая роль "тонкого" клиента, визуализирует так называемые маркированные данные (языки маркировки: HTML либо XML) для пользователей ERP Oracle E-Business Suite. Введенные пользователем запросы и команды передаются с помощью протокола HTTP через сеть передачи данных серверу приложений. Приложения ERP Oracle E-Business Suite исполняются как некоторые вычислительные процессы на сервере приложений и при необходимости осуществляют взаимодействие с сервером баз данных (в общем случае - распределенным). При этом процесс обмена данными между приложениями и БД ERP Oracle E-Business Suite затрагивает компоненты доступа к реляционной базе данных языка высокого уровня, протокол прикладного уровня SQL*Net и стек протоколов TCP/IP. Так как СУБД ERP Oracle E-Business Suite построена по распределенному принципу, введем в схему (рис. 1) кластер параллельно функционирующих серверов баз данных, связанных между собой по протоколу SQL*Net.
Анализ представленной схемы обработки данных ERP Oracle E-Business Suite (рис. 1) позволяет выделить следу-ющие компоненты, ответственные за преобразование, хранение и передачу данных:
• программу-браузер, выполняющую визуализацию маркированных данных (преобразование "графическое представление - HTML/XML-документ");
• подсистему передачи и кэширования маркированных данных;
• прикладную программу на сервере приложений;
• подсистему передачи данных в реляционном представлении;
• подсистему физического хранения данных в рамках СУБД.
Следовательно, для мониторинга безопасности ERP Oracle E-Business Suite необходимо построить некоторые контрольные точки или инварианты обработки данных, а также создать адекватные методы контроля этих инваринтов для следующих процессов:
• визуализации маркированных данных и интерфейса с пользователем;
• протокола прикладного уровня HTTP;
• протокола прикладного уровня SQL*Net;
• стека протоколов транспортного, сетевого и канального уровней TCP/IP;
• прикладной программы (логики приложения);
• подсистемы физического представления реляционных данных в СУБД.
Давайте рассмотрим перечисленные процессы обработки данных ERP Oracle E-Business Suite подробнее.
Визуализация маркированных данных
Управляющий граф программы "тонкого" клиента представлен на рис. 2. Здесь входным параметром процесса является строковая величина StartURI - уникальный идентификатор ресурса (URI - unique resource identifier), инициализирующая сеанс работы с пользователем ERP Oracle E-Business Suite. Этот параметр может быть однозначно определен на этапе разработки ERP-системы, если процесс идентификации и аутентификации пользователя реализован средствами самого приложения, или величину StartURI должен предоставить внешний процесс идентификации в системе.
В общем случае ветвление, связанное с возможностью отображения копии документа, находящейся в кэше браузера, может зависеть от следующих факторов:
• логики работы с кэшированными документами;
• отметки времени кэшированной копии;
• наличия в идентификаторе ресурса переменной составляющей (запроса) и т. п.
После загрузки с сервера копии документа и его параметров заносятся в кэш для последующего использования. При этом алгоритм визуализации преобразует так называемые маркированные данные, полученные от сервера приложений, во внутреннюю структуру данных браузера, а затем в графическое представление на устройстве вывода. После визуализации документа браузер переходит в цикл ожидания и ожидает действий пользователя. Различают три варианта действий пользователя:
• выход из программы;
• редактирование изменяемых величин;
• вызов команды к серверу приложений.
При попытке пользователя выполнить операцию редактирования браузер должен проверить доступность величины на изменение. При запросе команды для сервера приложений браузер должен:
• определить неизменяемую часть уникального идентификатора;
• определить набор величин, связанных с данным запросом (командой);
• сформировать список пар "название величины - значение величины";
• сформировать конкатенацией полный идентификатор ресурса URI.
Внутреннюю структуру представления данных в программе-браузере можно представить в виде двух наборов данных:
• записей о командах, доступных пользователю при работе с данным документом (в языке HTML с командами связаны элементы управления "ссылка" и "форма"):
• URL1, URL2, ... , URLCC - постоянными составляющими идентификаторов ресурсов, связанных с данной командой (тип данных - строковый);
• CM1, CM2, ... , CMCC - информации о правилах отображения управляющего элемента, связанного с данной командой (тип данных - структура);
• записей о величинах (в языке HTML с постоянными величинами связан элемент управления "текст", с переменными - элемент управления "input"):
• VN1, VN2, ... , VNVС - имен величин (тип данных - строковый);
• VV1, VV2, ... , VVVС - значений величин (тип данных - строковый, либо в зависимости от величины - строковый, целочисленный, вещественный, логический);
• VW1, VW2, ... VWVС - логических признаков возможности редактирования значения величины в программе-браузере (тип данных - логический);
• VR1, VR2, ... , VRVС - порядковых номеров команды, с которой связана данная величина (в языках маркированного представления данных HTML и XML соблюдается строгая иерархическая структура элементов управления и визуализации, вследствие этого каждая конкретная величина может быть связана только с одной командой (тип данных - целочисленный, диапазон допустимых значений - [1..CC]));
• VM1, VM2, ... , VMVC - информации о правилах отображения управляющего элемента, связанного с данной величиной (тип данных - структура).
Указанные два набора данных (State) вместе с текущим уникальным идентификатором ресурса (URI) и маркированным документом в двоичном представлении (Doc) полностью описывают текущее состояние программы-браузера. В этом случае информационный граф модели обработки данных представлен на рис. 3.
Здесь процесс Cache производит выборку из кэша документа по его уникальному идентификатору, процесс Load выполняет загрузку документа с помощью протокола HTTP, процесс Parse выполняет разбор маркированного документа и на его основе заполняет набор данных State. Процесс Request производит сборку нового уникального идентификатора на основе следующих данных:
• значения URLj , связанного с выбранной пользователем командой (полагаем, что ее индекс - j);
• имен VNki и текущих значений VVki величин, связанных с выбранной пользователем командой (то есть тех, для которых выполняется условие VRki = j).
Отметим, что для языка HTML правила построения уникального идентификатора имеют следующий вид:
URI ' = URLj + "?" + VNk1 + "=" + VVk1 + "&" + VNk2 + "=" + VVk2 + "&" + … + VNkn + "=" + VVkn.
Протоколы прикладного уровня HTTP и SQL*Net
Протоколы прикладного уровня HTTP (Hyper Text Transfer Protocol) и SQL*Net достаточно похожи (находятся на одном уровне классической модели OSI). Общими функциями этих протоколов являются:
• согласование параметров транспортного кодирования (в том числе компрессии) данных;
• согласование параметров кодирования алфавита национального языка;
• разрешение имен прикладного уровня в идентификаторах ресурсов.
Отличия проявляются в схемах кодирования передаваемой на нижние уровни информации, а также в характере возвращаемой от сервера метаинформации.
Процесс HTTP-клиент инициализируется путем задания параметра URI - уникального идентификатора запрашиваемого ресурса. При этом процесс выполняет разбор идентификатора на три параметра:
• имя хоста;
• TCP-порт HTTP-сервера;
• относительный URI.
При необходимости имя хоста представляется соответствующим IP-адресом. В этом случае используются:
• служба разрешения доменных имен (DNS);
• служба разрешения имен Windows (WINS);
• локальный справочник.
Далее процесс определяет список допустимых для него параметров HTTP-соединения, таких, как транспортное кодирование (сжатие) и кодирование национального алфавита. В HTTP-запросе указывается весь список для того, чтобы HTTP-сервер имел возможность выбрать общие для клиента и сервера параметры соединения. В случае присутствия документа с аналогичным уникальным идентификатором в локальном кэше в HTTP-заголовок добавляется поле "Время создания имеющегося в кэше документа". Сформированный текст HTTP-запроса (с указанием типа - "GET", версии протокола "HTTP/1.1", относительного URI, имени хоста и параметров соединения) передается на нижележащий уровень стека сетевых протоколов.
После получения запроса HTTP-сервером процесс проверяет наличие на сервере ресурса с запрошенным идентификатором. При отсутствии запрашиваемого ресурса на клиентскую сторону передается сообщение с кодом ошибки "404" - "Документ не найден". В случае наличия ресурса возможны три варианта.
Если HTTP-запрос содержал поле "Время создания имеющегося в кэше документа" и указанное в нем время совпадает со временем создания хранимого на серверной стороне ресурса, то на клиентскую сторону передается сообщение с кодом "304" - "Документ не изменялся". В противном случае на основании своего списка возможных параметров HTTP-соединения и списка, полученного в HTTP-запросе, сервер выбирает активные параметры соединения. Если не удается согласовать параметры соединения, то на клиентскую сторону отправляется сообщение об ошибке с кодом "406" - "Несогласуемые параметры". При успешном согласовании параметров формируется HTTP-ответ, включающий код "200" ("Ресурс передается"), содержимое (при необходимости преобразованное согласно активным параметрам), записи об активных параметрах соединения, а также информацию о дате и времени создания документа для занесения в кэш на клиентской стороне.
Полный текст HTTP-ответа передается на нижележащий уровень стека протоколов. После получения ответа на клиентской части системы проверяется соответствие длины содержимого, и при необходимости выполняется транспортное декодирование.
Отметим, что протокол SQL*Net объединяет несколько подпротоколов, отвечающих за различные функции в организации взаимодействия "клиент - сервер" и "сервер - сервер".
Подпротокол-интерфейс UPI/OPI/NPI предоставляет возможность в соединении "клиент - сервер" (UPI/OPI) и "сервер - сервер" (NPI/OPI) выполнять команды прикладного уровня:
• подключение к серверу;
• предварительная проверка сервером синтаксиса SQL-запроса;
• исполнение SQL-запроса;
• открытие курсора реляционного представления данных;
• передача реляционных данных от сервера к клиенту;
• типизация передаваемых данных на основе записей о типах данных на стороне сервера;
• закрытие курсора;
• отключение от сервера.
При этом отличие схем подключения "клиент - сервер" и "сервер - сервер" проявляется только на этом уровне, тогда как на более низких уровнях подпротоколов различия отсутствуют. Сервер, отвечающий на SQL-запрос, в обоих случаях использует интерфейс OPI - аналог процесса HTTP-сервера. Вызывающие интерфейсы UPI (клиентский) и NPI (серверный при соединении "сервер - сервер") отличаются незначительно. Со стороны клиента унифицированные драйверы доступа к реляционным данным (такие, как, например, ODBC - Open DataBase Connection) производят отображение своих интерфейсов к интерфейсу UPI.
Подпротокол Two-Task Common (TTC) отвечает за выбор единого представления типов данных и схем кодирования национального алфавита. В случае необходимости как клиентская, так и серверная сторона TTC может производить преобразования передаваемых данных в рамках известных ей схем кодирования. В отличие от схемы, используемой протоколом HTTP, Two-Task Common производит выбор общих параметров SQL*Net-соединения, однократно в момент его открытия и при исполнении всех дальнейших команд пользуется уже согласованными (актуальными) параметрами.
Подпротокол Transparent Network Substrate (TNS) реализует не зависящий от нижележащего стека сетевых протоколов интерфейс с четырьмя командами:
• подключиться к удаленному объекту;
• передать данные;
• получить данные;
• отключиться от удаленного объекта.
В функции TNS входит разрешение имен объектов с тем, чтобы вышележащие уровни могли оперировать абстрактным понятием "псевдоним" удаленного процесса. Разрешение имен производится с помощью следующих протоколов:
• Oracle Names;
• локальный справочник;
• программные адаптеры от Oracle для популярных протоколов разрешения имен (NetWare Directory Service, StreetTalk, NIS и т. п.).
В связи с однотипностью функций, выполняемых протоколами, опишем для них единую модель функционирования процесса, распространив на весь протокол SQL*Net возможности кэширования результатов (возможностью кэширования результатов обладает только стык интерфейсов NPI/OPI). К HTML-документу и данным в реляционном представлении далее будем применять термин "ресурс".
Пусть состояние системы "клиент - сервер" описывается следующим набором величин:
• RN - имя запрашиваемого у клиентского интерфейса ресурса (тип данных - строковый);
• RS - требуемая кодировка национального алфавита запрашиваемого ресурса (тип данных - целочисленный);
• CS - список кодировок национального алфавита, поддерживаемых клиентом (тип данных - список целочисленных величин);
• CT - список транспортных кодировок, поддерживаемых клиентом (тип данных - список целочисленных величин);
• CC - содержимое ресурса на клиентской стороне (выходной результат процесса) (тип данных - строковый);
• CD - дата и время создания ресурса (тип данных - отметка времени);
• CACHE_CNT - количество ресурсов, размещенных в кэше (тип данных - целочисленный);
• CACHE_NAMES - имена ресурсов, размещенных в кэше (тип данных - список строковых величин);
• CACHE_DATES - дата и время создания ресурсов, размещенных в кэше (тип данных - список отметок времени);
• CACHE_VALUES - содержимое ресурсов, размещенных в кэше (тип данных - список строковых величин);
• CACHE_CHARSETS - кодировки национального языка ресурсов, размещенных в кэше (тип данных - список целочисленных величин);
• CI - номер найденного в кэше ресурса (тип данных - целочисленный);
• CB - буфер клиентской стороны (тип данных - строковый);
• SB - буфер серверной стороны (тип данных - строковый);
• TN - имя запрашиваемого ресурса на серверной стороне (тип данных - строковый);
• TS - список кодировок национального алфавита, поддерживаемых клиентом, на серверной стороне (тип данных - список целочисленных величин);
• TT - список транспортных кодировок, поддерживаемых клиентом, на серверной стороне (тип данных - список целочисленных величин);
• TDATE - дата и время создания ресурса, найденного в кэше (тип данных - отметка времени);
• SS - список кодировок национального алфавита, поддерживаемых сервером (тип данных - список целочисленных величин);
• ST - список транспортных кодировок, поддерживаемых сервером (тип данных - список целочисленных величин);
• VALUE_CNT - количество ресурсов, размещенных на сервере (тип данных - целочисленный);
• VALUE_NAMES - имена ресурсов, размещенных на сервере (тип данных - список строковых величин);
• VALUE_DATES - дата и время создания ресурсов, размещенных на сервере (тип данных - список отметок времени);
• VALUE_VALUES - содержимое ресурсов, размещенных на сервере (тип данных - список строковых величин);
• VALUE_CHARSETS - кодировки национального языка ресурсов, размещенных на сервере (тип данных - список целочисленных величин);
• SI - номер найденного на сервере ресурса (тип данных - целочисленный);
• AS - кодировка национального алфавита, выбранная сервером как активная для данного сеанса (тип данных - целочисленный);
• AT - транспортная кодировка, выбранная сервером как активная для данного сеанса (тип данных - целочисленный);
• DS - кодировка национального алфавита, выбранная сервером как активная для данного сеанса, на клиентской стороне (тип данных - целочисленный);
• DT - транспортная кодировка, выбранная сервером как активная для данного сеанса, на клиентской стороне (тип данных - целочисленный);
• CM - буфер на клиентской стороне для содержимого ресурса в ходе перекодировок (тип данных - строковый);
• SM - буфер на серверной стороне для содержимого ресурса в ходе перекодировок (тип данных - строковый);
• CE - код ответа сервера на клиентской стороне (тип данных - целочисленный).
Дополнительно введем константы:
• С202 - код ответа, соответствующий успешной отправке ресурса сервером;
• С304 - код ответа, соответствующий неизменности ресурса с момента последней загрузки его клиентом;
• С404 - код ответа, соответствующий отсутствию ресурса;
• С406 - код ответа, соответствующий несогласуемости параметров клиентской и серверной стороны.
Информационный граф протоколов в рамках данной модели представлен на рис. 4.
Именные процедуры в модели имеют следующие функции:
• ENC_REQ - кодирование запроса;
• DEC_REQ - декодирование запроса;
• ENC_RESP - кодирование ответа;
• DEC_RESP - декодирование ответа;
• CHARSET - смена схемы кодирования алфавита национального языка;
• ENC_TRANS - транспортное кодирование;
• DEC_TRANS - транспортное декодирование.
Операции присваивания SB=CB и CB=SB представляют собой передачу сообщений по сети TCP/IP.
Протокол транспортного уровня TCP
Различают две основные функции протокола TCP (transmission control protocol):
• подтверждение доставки сообщения от отправителя получателю;
• управление скоростью обмена данными.
Для реализации названных функций в протоколе было введено понятие "окно" - максимальный объем данных, который может быть передан без подтверждения с принимающей стороны. В процессе передачи данных размер окна варьируется исходя из сетевой обстановки: при увеличении эффективной пропускной способности сети передающая сторона увеличивает размер окна, при снижении - уменьшает.
Кроме того, для гарантированной доставки сообщений между клиентской и серверной стороной на время передачи сообщения устанавливается уникальный сеанс, в рамках которого пересылаются пакеты квитирования - подтверждения доставки. Начало сеанса запрашивается клиентской стороной служебным пакетом SYN с содержимым нулевой длины, а подтверждается со стороны сервера пакетом SYN_ACK также с содержимым нулевой длины. Окончание сеанса запрашивается служебным пакетом FIN и подтверждается пакетом FIN в обратном направлении.
Исходя из симметричности протокола TCP, для целей, поставленных в данной работе, достаточно построить модель TCP-соединения, передающего данные в одном направлении (скажем, от вызывающей стороны к вызываемой).
Опишем состояние системы "TCP-клиент - TCP-сервер" следующими величинами:
• количеством окон N, на которые будет разбито передаваемое сообщение (тип данных - целочисленный);
• значением окон S1, S2, ... SN на передающей стороне (размер окон в битах может быть непостоянен, но для данной задачи это не играет роли) (тип данных - список строковых величин);
• буфером передающей стороны SB размером в одно окно (тип данных - строковый);
• порядковым номером текущего передаваемого окна SI (тип данных - целочисленный);
• значением окон R1, R2, ... RN на принимающей стороне (тип данных - список строковых величин);
• буфером принимающей стороны RB размером в одно окно (тип данных - строковый);
• порядковым номером текущего принимаемого окна RI (тип данных - целочисленный).
Кроме того, введем служебные значения буферов приема и передачи, отвечающие за начало и окончание сеанса:
• SYN - запрос на установление соединения;
• SYN_ACK - подтверждение установления соединения;
• ACK - подтверждение приема окна сообщения;
• FIN - сигнал окончания сообщения.
Информационный граф протокола TCP в рамках введенных обозначений представлен на рис. 5. Операции присвоения SB=RB и RB=SB представляют собой передачу окон по сети с помощью протокола IP.
Протокол сетевого уровня IP
Протоколы сетевого уровня отвечают за относительно независимую для вышележащих уровней модели OSI передачу сообщений по сетям с гетерогенной структурой протоколов канального уровня (Ethernet, FrameRealy, ATM, PPP и т. д.). Как следствие, в их функции входит маршрутизация пакетов в пространстве имен сетевого уровня, а также фрагментация и сборка пакетов (в связи с варьируемостью максимально возможной длины пакета в различных протоколах канального уровня).
В рамках поставленной задачи критичной функцией из перечисленных выше является именно фрагментация и сборка пакетов протоколом IP. При этом при построении модели необходимо учитывать, что в силу неоднородности сетевых условий во времени очередность прихода пакетов-фрагментов в пункт назначения может быть произвольной. Этим протокол IP качественно отличается от протокола TCP, который реализует строгую последовательность передачи окон.
Состояние системы "отправитель - получатель" при передаче одного пакета протокола IP опишем следующими величинами:
• количеством фрагментов N, на которые будет разбито передаваемое сообщение (тип данных - целочисленный);
• значением пакетов-фрагментов S1, S2, ... SN на передающей стороне (тип данных - список строковых величин);
• порядковым номером текущего передаваемого фрагмента SI (тип данных - целочисленный);
• сетевым буфером B размером, равным максимально возможной длине IP-сообщения (тип данных - список строковых величин);
• значением пакетов-фрагментов R1, R2, ... RN на принимающей стороне (тип данных - список строковых величин);
• значением буфера RB на приемной стороне размером в один фрагмент (тип данных - строковый);
• значением номера принятого пакета на приемной стороне PI (тип данных - целочисленный).
В этом случае информационный граф протокола IP имеет следующий вид (рис. 6). Операции присваивания и чтения из буфера B представляют собой передачу окон по сети с помощью протокола нижележащего уровня. Для операции чтения из буфера B существуют ограничения: нельзя считать j-ый элемент буфера B, если счетчик SI меньше j.
Отметим, что именные процедуры в модели имеют следующие функции:
• FRAG - фрагментирование сообщения на элементы Si;
• DEFRAG - сборка сообщения из элементов Ri, проверка полного приема на основе порядковых номеров фрагментов;
• ENC_IP - кодирование IP-фрагмента;
• DEC_IP - декодирование IP-фрагмента.
Характерной особенностью информационного графа протокола IP является недетерминированность его поведения при равных начальных условиях. Пример графа состояний системы для количества фрагментов, равного двум, приведен на рис. 7.
Немного теории мониторинга безопасности ERP-систем
Проведем анализ полученных моделей обработки данных с помощью методов анализа размерностей и подобия. Данные методы были сначала разработаны авторами для аналитической верификации приложений и основываются на проверке совместности системы размерностей модели обработки данных ERP Oracle E-Business Suite.
Кратко сущность предлагаемых методов заключается в том, что для информационного графа модели обработки данных ERP Oracle E-Business Suite строится система взаимосвязей между размерностями переменных и констант следующим образом. Каждый оператор модели, содержащий вычислительные операции и/или оператор присваивания и имеющий однородный вид относительно своих аргументов, представляется в виде суммы функционалов ?: 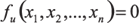 u = 1, 2, …, r, где (1)
u = 1, 2, …, r, где (1) 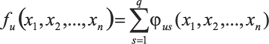 и (2)
и (2) 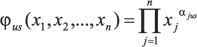 (3)
(3)
В этом случае положения теории размерностей и подобия [1] позволяют создать систему требований к размерностям величин xj, вытекающую из следующих соображений (запись [X] обозначает "размерность величины X"):  (4)
(4)  (5)
(5) 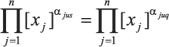 (6)
(6)  (7)
(7)
и после логарифмирования 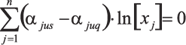 (8)
(8)
u = 1, 2, …, r ; s = 1, 2, …, (q-1) .
Необходимым критерием семантической правильности модели обработки данных ERP Oracle E-Business Suite является существование у системы (8) решения, в котором ни одна из переменных (ln[xj]) не обращена в ноль. Проблемам повышения скорости исчисления данного критерия будет посвящен один из последующих материалов. В данной же статье для решения этого вопроса мы ограничимся тривиальными эквивалентными преобразованиями уравнений системы, записанной в матричной форме.
Таким образом, для построения первоначального набора уравнений (2) для каждой модели обработки данных ERP Oracle E-Business Suite предлагается следующая методика:
• произвольно возьмем выборку реализаций процесса, описываемого моделью;
• проверим представительность выборки по покрытию всех вершин управляющего графа модели;
• выполним приведение управляющего графа модели с целью выделения вычислительных операторов из операторов проверки условий и организации циклов;
• выделим из выборки все уникальные операторы, отвечающие описанным выше ограничениям на вид функциональной связи;
• выделим задействованные в операторах переменные и константы, полагая при этом:
а) элементы внутри массива равноразмерными величинами,
б) числовые константы попарно разноразмерными величинами (определение их принадлежности определенным классам произойдет автоматически на этапе согласования матрицы размерностей).
Переходы управляющего графа, связанные с вычислением сложных функциональных зависимостей, и соответствующие операторам вызова подпрограмм дополняют систему (2) наборами операций присваивания формальных параметров. Подобные дополнительные ограничения выполняют связующую роль между величинами основного тела алгоритма и величинами подпрограмм. Данный шаг необходимо выполнять в случае построения единой модели вычислительного процесса.
Мониторинг безопасности ERP Oracle E-Business Suite
Мониторинг безопасности SQL-запросов. Как правило, под прикладной программой понимается процесс, исполняющийся на сервере приложений ("среднее звено" трехзвенной модели) и ответственный за реализацию собственно прикладной логики системы. Последовательность операций, выполняемых данным процессом по запросу, представлена на рис. 8.

Полагая, что алгоритм вычислений путем несложных преобразований возможно привести к нормализованной (разделенной) форме, примем за свойства первого и последнего блоков отсутствие в них преобразований размерностей информации. Таким образом, в схеме, приведенной на рис. 1, контролю подлежат следующие два уровня системы.
• Блоки пред- и поствычислений. Они обычно реализуются на универсальных языках высокого уровня (С++, Pascal, Java, C#). Контролю подлежат инварианты арифметических операций и операторов присваивания.
• SQL-запрос. Язык структурированных запросов SQL (Structured Query Language) представляет собой прикладной язык высокого уровня. Контролю (на основе метода контроля размерностей) подлежат инварианты нескольких групп типовых операций языка, вовлекающих различные типы данных.
Давайте рассмотрим возможности контроля SQL-запросов.
Предложения языка SQL, чрезвычайно широко применяемого на сегодняшний день для унификации доступа к реляционным СУБД, представляют собой команды серверу БД на получение доступа или редактирование хранящихся данных. Наиболее часто применяются четыре основных типа предложений:
• SELECT - выборка строк данных;
• INSERT - добавление новых строк;
• UPDATE - редактирование существующих строк;
• DELETE - удаление строк.
Элементы контекстно-свободных грамматик, порождающих вышеперечисленные предложения, в графической форме представления изображены на рис. 9-12. Правила вывода, порождающие нетерминальные символы, не влияющие на процедуру анализа размерностей, опущены.
Предложения языка SQL содержат два типа конструкций, контролируемых на уровне инвариантов размерностей:
• конструкции condition ("условие");
• конструкции неявного соответствия размерностей.
Конструкции "условие" встречаются в SQL -предложениях SELECT , UPDATE и DELETE (позиции C 1, C 2, C 3, C 4 на рис. 9, позиция C 1 на рис. 11 и позиция C 1 на рис. 12). Язык SQL поддерживает несколько типов условий, однако все они представимы, как и в подавляющем большинстве универсальных языков программирования, либо в одноместной форме
"выражение-1") (1)("операция условия"
либо в двухместной форме
"выражение-2"). (2) ("выражение-1" "операция условия"
Исключение составляют специфические условия ANY , SOME , ALL , IN , вовлекающие в себя вложенные предложения SELECT .
Анализ размерностей первых двух классов условий полностью аналогичен методике, рассмотренной выше:
• выражения приводятся к однородным уравнениям;
• каждое уравнение с q слагаемыми преобразуется в ( q -1) требований равенства размерностей однородных слагаемых;
• полученные уравнения размерностей логарифмируются, в результате чего создается система однородных линейных уравнений (назовем ее AC ), описывающая требования к взаимосвязям между размерностями.
Специфичным для языка SQL является построение системы уравнений размерностей AE , основывающейся на конструкциях неявного соответствия размерностей и конструкциях условий ANY , SOME , ALL , IN . Основной идеологией языка SQL является работа с кортежами - построчная обработка записей таблиц и результатов реляционных отношений над ними. Так, в предложении SELECT кортежами являются нетерминальные символы, обозначенные E 1 и E 2 на рис. 2, в предложении INSERT - E 1, E 2, E 3 и E 4 на рис. 3, в предложении UPDATE - E 1, E 2, E 3, E 4 и E 5 на рис. 4. В любом предложении языка SQL элементы всех описанных кортежей должны иметь попарно равные размерности.
Кроме того, аналогичные ограничения налагаются и на элементы условий специального вида ANY , SOME , ALL , IN . В общем виде эти условия можно представить в форме
("кортеж-1" "операция условия" " ANY / SOME / ALL / IN " "кортеж-2") .
Таким образом, наличие в предложении языка SQL n описаний кортежей из k элементов в каждом  (3)
(3)
вводит систему из ( n -1)x k дополнительных ограничений на размерности столбцов таблиц и выражений, их содержащих. В тех случаях, когда элементом кортежа является не собственно столбец таблицы, а арифметическое выражение, содержащее его, возможно еще большее увеличение системы ограничений (согласно методике контроля размерностей однородных уравнений).
Построенная из полученного списка ограничений система уравнений размерностей AE дополняет полученную ранее систему AC . Требование нетривиальной совместности системы A , образуемой путем слияния систем AE и AC , является мощным средством проверки семантической корректности SQL -предложения перед его исполнением.
Пример
Произведем построение системы уравнений размерности A и контроль корректности конкретного SQL -предложения на следующем примере. Дана СУБД, содержащая таблицу DETAILS с полями (табл. 1).
Кроме того, в системе определены следующие константы (табл. 2).
Предположим, что была предпринята попытка выполнить следующий SQL -запрос:
UPDATE DETAILS
SET (S,VALUE) = (X*Y, X*Y*PRICE+TRANS)
WHERE ((X,Y) IN (SELECT X+MARGIN,Y+MARGIN
FROM DETAILS)) AND
(PRICE*MAX_SIZE>TRANS)
В основном предложении UPDATE присутствуют два кортежа по два элемента в каждом, одно неспецифическое условие и одно специфическое условие IN . В условии IN и в связанном им запросе SELECT определено еще два кортежа по два элемента в каждом.
Таким образом, проверка конструкций "условие" дает уравнение размерностей
[ PRICE * MAX _ SIZE ]=[ TRANS ] , (4)
проверка конструкций согласования размерностей -
[S]=[X*Y] и (5)
[VALUE]=[X*Y*PRICE+TRANS] . (6)
Вложенное предложение SELECT приводит еще к двум уравнениям размерности:
[X]=[X+MARGIN] и (7)
[Y]=[Y+MARGIN] . (8)
В целом система уравнений AC , порождаемая уравнением (4), имеет вид (табл. 3).
Система уравнений размерности AE , порождаемая уравнениями (5-8), имеет вид (табл. 4.
Матрица, соответствующая системе A (образующаяся объединением AC и AE ) имеет размерность 6x8 и ранг 6, что характеризует наличие в системе двух независимых размерностей (в качестве независимых могут, например, быть выбраны X и VALUE ). Это полностью согласуется с предметной областью, где определены действительно ровно две независимые размерности: "метры" и "рубли".
Предположим, что на этапе создания ПО либо разбора динамического HTTP -запроса произошла ошибка, повлекшая следующее написание SQL -предложения перед моментом исполнения:
UPDATE DETAILS
SET (S,VALUE) = (X*Y, X*Y*PRICE+TRANS)
WHERE ((X,Y) IN (SELECT X+MARGIN,Y*MARGIN FROM DETAILS)) AND
( PRICE * MAX _ SIZE > TRANS )
В момент анализа изменению подвергнется уравнение (8). Оно примет вид
[ Y ]=[ Y * MARGIN ] . (9)
Матрица, соответствующая новой системе, имеет размерность 6x8 и ранг 6, что также характеризует наличие в системе двух независимых размерностей.
Однако при этом имеют место нулевые значения в векторе-решения, что соответствует якобы имеющимся следующим взаимосвязям:
[ X ] = [ MARGIN ] = 0 . (10)
Это уже кардинально не соответствует предметной области и является однозначным индикатором аномалии в построенной SQL -конструкции.
Мониторинг безопасности прикладных протоколов ERP Oracle E - Business Suite . Выборка реализаций процесса протокола прикладного уровня, представительная по покрытию вершин управляющего графа, содержит следующие уникальные взаимосвязи между размерностями в явном виде.
Кроме того, приведение операторов проверки условий выделяет еще один набор ограничений на размерности:
[RN]=[CACHE_NAMES]
[TN]=[VALUE_NAMES]
[VALUE_DATES]=[TDATE]
[CI]=[CACHE_CNT]
[ SI ]=[ VALUE _ CNT ]
(во всех случаях в качестве идентификаторов элементов массивов выписаны имена самих массивов, исходя из принципа равноразмерности элементов массивов, а знаки "*" у числовых констант отмечают их потенциальную разноразмерность).
Система уравнений (8) для протокола прикладного уровня, записанная в матричной форме, представляет собой матрицу AL 7 размерности 29x36. Ранг матрицы равен 28, что обусловлено наличием одного линейно зависимого уравнения. Традиционная методика исчисления критерия требует приведения матрицы путем эквивалентных преобразований к специальному виду с выделенными базисными столбцами. Однако для удобства изложения результатов для данной модели в журнальном формате, мы изменим исходные позиции столбцов переменных и приведем матрицу AL 7 к блочно-диагональному виду B ` L 7: 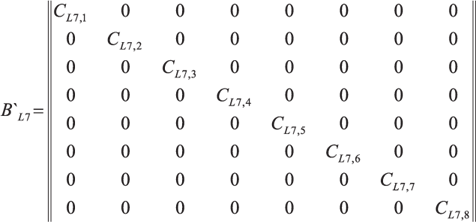 где (9)
где (9) (9.1)
(9.1)  (9.2)
(9.2) 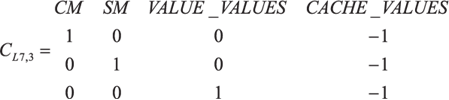 (9.3)
(9.3)  (9.4)
(9.4) 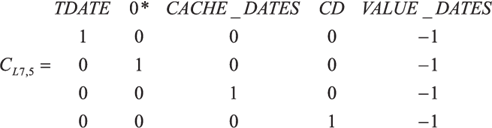 (9.5)
(9.5) 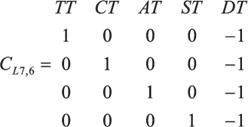 (9.6)
(9.6)  (9.7)
(9.7) 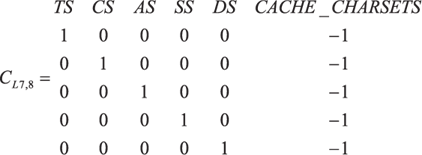 (9.8)
(9.8)
(над столбцами подписаны величины, соответствующие xj в неизвестных ln [ xj ] системы (8)).
Матрица имеет 8 независимых (базисных) и 28 зависимых столбцов; нулевая строка, соответствующая линейно зависимому уравнению удалена. Очевидно, что система однородных линейных уравнений, описываемая матрицей B ' L 7, имеет решение, не содержащее нулей. Как следствие, подобное решение имеет и исходная система размерностей модели.
Мониторинг безопасности протокола TCP .
Наличие цикла и ветвления в управляющем графе процесса указывает на возможность достаточно большого количества различных реализаций. Нас будет интересовать выборочный набор реализаций, покрывающий всю совокупность вершин управляющего графа. Данному условию удовлетворяет набор из одной реализации, хотя бы однократно проходящей цикл процесса, поэтому далее будем рассматривать подобные реализации как представительные для данного управляющего графа.
В явном виде в модели процесса протокола TCP присутствуют следующие взаимосвязи между размерностями: 
Кроме этого, приведение условия ветвления цикла ( SI < N ) к каноническому виду ( T *= SI - N ; T *<0, где T * - вспомогательная величина) добавляет уравнение размерности
[ N ] = [ SI ].
Матричная форма AL 5 записи системы (8) для данного протокола приведена в таблице 7. В заголовках столбцов указаны соответствующие переменные xj .
Матрица имеет размерность 11x13. Ранг матрицы равен 10, что соответствует одной линейно зависимой строке (в данном случае строка 4 является инверсией строки 2). Путем эквивалентных преобразований приведем матрицу к виду BL 5, состоящему из базисных столбцов и зависимых столбцов, содержащих по одному единичному элементу (табл. 8).
Специальный вид матрицы позволяет непосредственно указать не содержащее нулей решение системы размерностей модели. Для этого достаточно выбрать в качестве набора значений базисных величин любой, не содержащий нулевых координат вектор, не являющийся ортогональным к векторам, составленным построчно из коэффициентов базисных столбцов.
Мониторинг безопасности протокола IP .
Представительная выборка реализаций для протокола IP содержит следующие взаимосвязи между размерностями величин в явном виде:
[S]=[RB] [PI]=[SI] [RI]=[1**]
[RB]=[R] [SI]=[1*]
Кроме того, операторы условия содержат еще два ограничения на размерности:
[ SI ]=[ N ] и [ RI ]=[ N ].
Матричная форма записи AL 3 системы уравнений (8) для данной модели приведена в таблице 9, формат записи соответствует формату предыдущего пункта.
Матрица имеет размерность 7x9, ранг матрицы - 7. Путем эквивалентных преобразований приведем матрицу к специальному виду BL 3 (таблица 10).
Аналогично предыдущему разделу специальный вид матрицы подтверждает наличие несодержащего нулей решения и, как следствие, выполнение исследуемого критерия семантической корректности модели.
Таким образом, становится возможным осуществлять мониторинг безопасности моделей сетевого взаимодействия в ERP Oracle E - Business Suite на основе TCP / IP . Существенным достоинством предлагаемого метода является выработка необходимых критериев семантической корректности модели обработки данных в ERP Oracle E - Business Suite .
Заключение
Известно, что своевременность и правильность мониторинга безопасности ERP Oracle E - Business Suite во многом определяет эффективность управления технологиями и организационно-техническими средствами защиты информации. Изучение специфики подобной задачи указывает на необходимость выделения и контроля инвариантов корректной (правильной с точки зрения безопасности) обработки данных в ERP Oracle E - Business Suite . В предлагаемом методе мониторинга безопасности обобщены, систематизированы и развиты практические результаты мониторинга состояния защищенности типичной системы ERP Oracle E - Business Suite в отечественных предприятиях. Важным моментом этого метода является развитие стандартных технологий и средств защиты ERP Oracle E - Business Suite , предоставляющих возможность контроля состояния защищенности на основе инвариантов безопасной обработки данных корпоративной системы в реальном масштабе времени, учитывающих бизнес-логику конкретного предприятия. Обобщая сказанное выше, следует заметить, что все изложенные результаты служат единой цели - созданию нового, более эффективного и обоснованного практически подхода к мониторингу безопасности ERP Oracle
E - Business Suite . Предлагаемый подход может быть полезен руководителям, их заместителям по развитию, автоматизации и безопасности, начальникам служб автоматизации и информационной безопасности, а также всем лицам, ответственным за организацию информационной безопасности ERP Oracle
E - Business Suite на предприятии при выполнении рекомендаций и требований руководящих и нормативных документов Гостехкомиссии России, ФАПСИ, а также международных стандартов, главным образом, ISO 17799 ( BS 7799), ISO 15408, ISO 9001:9002, BSI .