
Оглавление
- Введение
- Сходства методик моделирования данных IDEF1X и IE
- Различия методик моделирования IDEF1X и IE
- Заключение
- Дополнительная информация
Рассмотрены две методики моделирования данных, используемых в программном средстве AllFusion ERwin Data Modeler. Показано, что методики IDEF1X и IE имеют больше сходств, чем различий.
Введение
Проектирование качественных баз данных (БД) с каждым годом приобретает все большее значение. Возможности систем управления базами данных с каждой версией увеличиваются, вместе с ними возрастают объемы БД и их сложность. Ошибка, допущенная на этапе проектирования БД, в дальнейшем может существенно снизить ее производительность и возможное применение. Чтобы снизить риск совершения критических ошибок следует использовать специальные программные средства моделирования данных. К таким средствам относится AllFusion ERwin Data Modeler (далее - Erwin). Одной из особенностей этого программного продукта является поддержка двух методик моделирования данных:
- IDEF1X
- IE (Information Engineering)
Пользователю ERwin предлагается использовать методику моделирования, которая является для него наиболее удобной. Для того чтобы эффективно использовать все возможности ERwin, необходимо понимать различия и сходства упомянутых методик.
В первой части статьи будет рассказано о сходствах методик моделирования, а во второй речь пойдет о различиях между ними.
Сходства методик моделирования данных IDEF1X и IE.
Обе методики моделирования данных основываются на диаграмме сущность-связь, которая была предложена в 1976 году сотрудником корпорации IBM Питером Ченом.
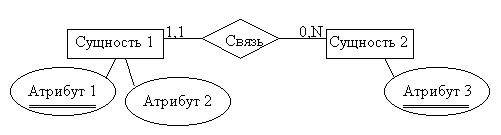
Рисунок 1. Диаграмма сущность-связь, предложенная П. Ченом
Диаграмма сущность-связь основывается на важной семантической информации о реальном мире. Может использоваться в качестве основы для унификации различных представлений данных на основе иерархической модели, сетевой модели и реляционной модели. Она включает в себя два графических элемента:
- сущность
Сущность (entity) - это "предмет", который может быть идентифицирован некоторым способом, отличающим его от других "предметов" (определение Питера Чена). Каждая сущность обладает набором атрибутов. Атрибут - отдельная характеристика сущности.Сущность состоит из экземпляров, каждый из которых должен отличаться от другого экземпляра. Пример: сущность - сотрудник, экземпляр сущности сотрудник - Петров Виктор Сергеевич.
- связь
Связь (relationship) - это логическая ассоциация, устанавливаемая между сущностями, которая представляет бизнес-правило или ограничение. С момента создания графическое представление диаграммы сущность-связь, которое предложил Питер Чен, изменялось и представления обеих рассматриваемых методик отличаются от представления предложенного Питером Ченом.
В обеих методиках сущность отображается прямоугольником, где сверху прямоугольника представлено название сущности. Прямоугольник делится горизонтальной линией, где атрибуты представленные выше линии являются атрибутами первичного ключа, а ниже линии представлены неключевые атрибуты.

Рисунок 2. Отображение сущности.
Атрибут первичного ключа - атрибут, значение которого позволяет уникально идентифицировать экземпляр сущности. Атрибут первичного ключа является частью первичного ключа, который необходим, для того чтобы отличать экземпляры сущности друг от друга. Первичный ключ может быть простым - состоящим из одного атрибута и составным - состоящим из нескольких атрибутов.
Связи отображаются как линии между сущностями. В зависимости от роли в связи сущность может быть родительской или дочерней. В методике IDEF1X у дочерней сущности на связи присутствует точка, в методике IE вместо точки используется 'птичья лапка' (crow's foot). Каждая связь имеет глагольную фразу, которая характеризует связь. Глагольная фраза читается по следующей формуле = название родительской сущности + глагольная фраза + название дочерней сущности. Иногда для большей ясности разработчики используют вторую глагольную фразу, которая читается по формуле = название дочерней сущности + глагольная фраза + название родительской сущности.
Существует два типа сущностей:
- зависимая сущность . Для определения экземпляра такой сущности необходимо сослаться на экземпляр независимой сущности, с которой связана зависимая сущность. Пример: сущности - заказ и позиция заказа . Для идентификации позиции заказа нужно сослаться на заказ, в который входит данная позиция.
- независимая сущность . Для определения экземпляра сущности нет необходимости ссылаться на другие сущности. Пример: сущности - заказ и позиция заказа . Для определения заказа (сущности) нет необходимости ссылаться на позиции этого заказа (другие сущности).
Существует несколько видов связей:
- идентифицирующая . Идентифицирующая связь указывает на то, что дочерняя сущность в связи является зависимой от родительской сущности, т.е. экземпляр зависимой сущности может быть однозначно определен, только если в этом экземпляре есть ссылка на экземпляр независимой сущности.
Идентифицирующая связь в обеих методиках отображается сплошной линией, причем дочерняя сущность является зависимой и поэтому отображается прямоугольником со скругленными углами.
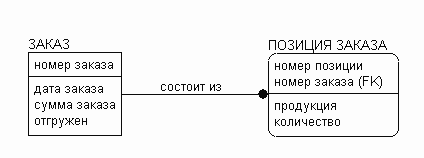
Рисунок 3. Идентифицирующая связь (методика IDEF1X)
- неидентифицирующая . Неидентифицирующая связь показывает на зависимость между родительской и дочерней сущностями, при этом экземпляр дочерней сущности может быть однозначно идентифицирован без ссылки на экземпляр родительской сущности.
Неидентифицирующая связь в обеих методиках отображается штриховой линией.
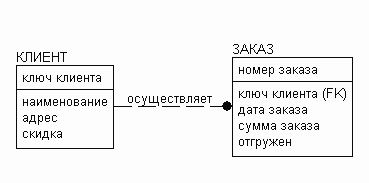
Рисунок 4. Неидентифицирующая связь (методика IDEF1X).
- многие ко многим . Неспецифичный тип связи, во многом свидетельствует о незавершенности анализа. На конечных этапах моделирования данных все связи многие-ко-многим преобразуются в другие (идентифицирующие и неидентифицирующие) типы связей. В связи многие-ко-многим не выделяется родительская и дочерняя сущность и, как правило, используется две глагольных фразы.
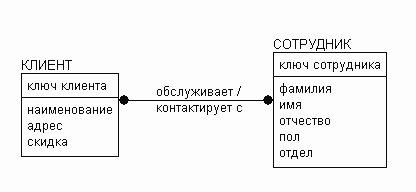
Рисунок 5. Связь многие-ко-многим (методика IDEF1X).
- иерархическая . Указывает на связь сущности саму на себя.
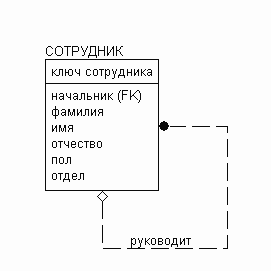
Рисунок 6. Иерархическая связь (методика IDEF1X).
- связь типа иерархии категории (будет рассмотрена в следующей части статьи).
Различия методик моделирования IDEF1X и IE
Первое различие между методиками IDEF1X и IE заключается в отображении мощности связи. Мощность связи - это отношение, показывающее какому количеству экземпляров дочерней сущности, может соответствовать экземпляр родительской сущности.
В методике IDEF1X мощность отображается следующим образом:
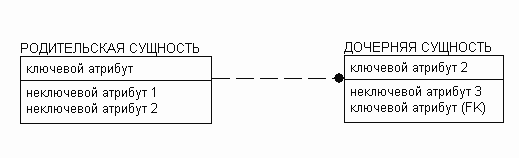
Рисунок 7. Методика IDEF1X - экземпляру родительской сущности могут соответствовать 0,1 или много экземпляров дочерней сущности.
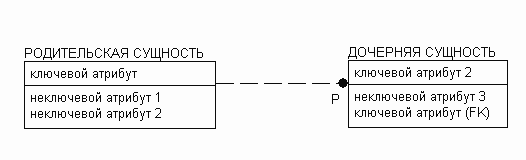
Рисунок 8. Методика IDEF1X - экземпляру родительской сущности могут соответствовать 1 или много экземпляров дочерней сущности (буква P у дочерней сущности).
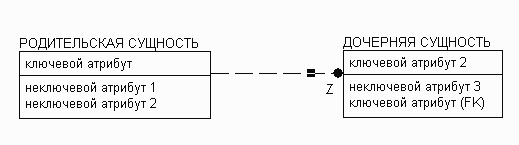
Рисунок 9. Методика IDEF1X - экземпляру родительской сущности могут соответствовать 0 или 1 экземпляров дочерней сущности (буква Z у дочерней сущности).
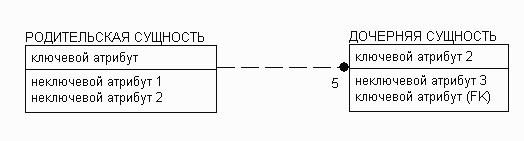
Рисунок 10. Методика IDEF1X - экземпляру родительской сущности соответствует в точности 5 экземпляров дочерней сущности (цифра 5 у дочерней сущности).
В методике IE мощность связи отображается следующим образом:
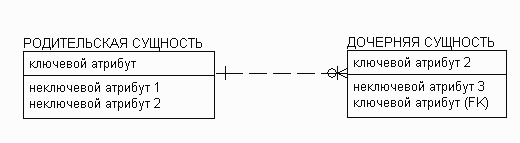
Рисунок 11. Методика IE - экземпляру родительской сущности могут соответствовать 0,1 или много экземпляров дочерней сущности.
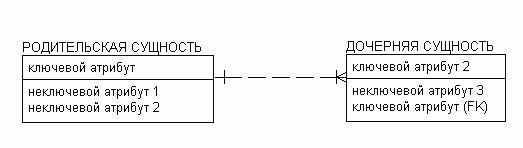
Рисунок 12. Методика IE - экземпляру родительской сущности могут соответствовать 1 или много экземпляров дочерней сущности.
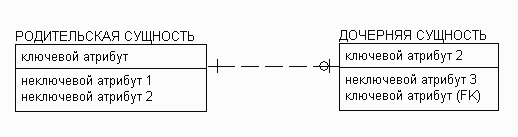
Рисунок 13. Методика IE - экземпляру родительской сущности могут соответствовать 0 или 1 экземпляров дочерней сущности.
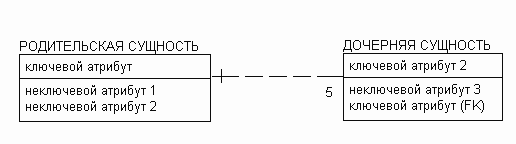
Рисунок 14. Методика IE - экземпляру родительской сущности соответствует в точности 5 экземпляров дочерней сущности (цифра 5 у дочерней сущности).
Из приведенных выше рисунков видно, что в методике IE для отображения мощности связи используется внешний вид связи у дочерней сущности, в то время как в методике IDEF1X для этих целей используются буквы у дочерней сущности.
Второе и самое существенное различие между методиками IDEF1X и IE заключается в разном смысле связи типа иерархия категорий и в ее графическом отображении.
В процессе моделирования данных могут быть выявлены сущности, часть атрибутов и связей которых одинаковы. В этом случае используется иерархия категорий. Все общие атрибуты выделяются в сущность называемую супертипом, а отличающиеся атрибуты помещаются в сущности - подтипы, связанные с супертипом. При помощи дискриминанта определяется, с экземпляром какого подтипа связан экземпляр супертипа.
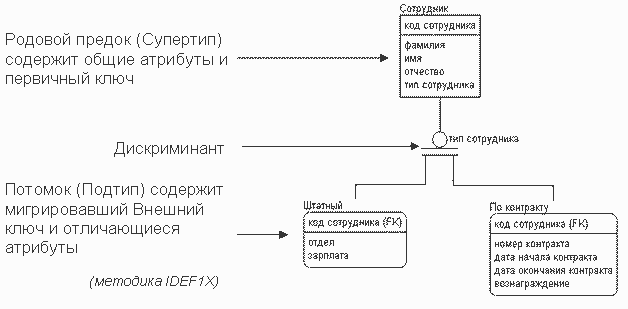
Рисунок 15. Связь типа иерархия категорий в методике IDEF1X.
В нотации IDEF1X иерархия категорий может быть двух типов - полная и неполная. Определить, какой тип иерархии категорий представлен в модели данных, можно по стилю отображения дискриминанта: дискриминант с двумя горизонтальными линиями свидетельствует о полноте иерархии категорий, с одной горизонтальной линией - о ее неполноте. Полная иерархия категорий свидетельствует о завершенности анализа. В примере с сотрудником полная иерархия категорий говорит о том, что любой сотрудник является либо штатным сотрудником, либо работающим по контракту и никаких других вариантов быть не может. Если в примере мы изменим иерархию категорий на неполную, это будет свидетельствовать о том, что помимо сотрудников, зачисленных в штат и работающих по контракту, могут быть и другие типы сотрудников, но на данном этапе моделирования данных, они еще не выявлены.
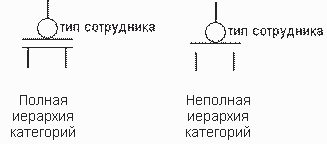
Рисунок 16. Виды иерархии категорий в методике IDEF1X.
Иерархия категорий создается в методике IE исходя из тех же соображений, что и в методике IDEF1X: в процессе моделирования данных выделяются сущности, имеющие общие атрибуты и связи, в таком случае общие атрибуты заключаются в сущность - супертип, а различающиеся атрибуты помещаются в сущности - подтипы.
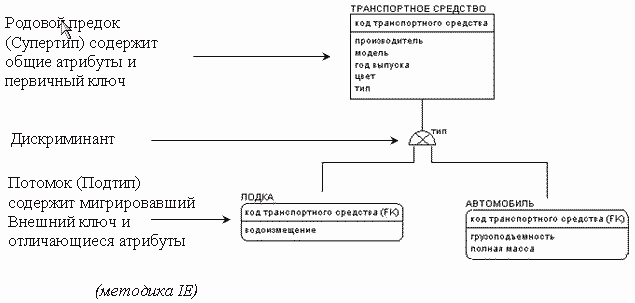
Рисунок 17. Иерархия категорий в методике IE.
Графическое отображение дискриминанта в методике IE отличается от представления в методике IDEF1X, отличается и смысл всей иерархии категорий. В методике IE есть деление иерархий категорий на эксклюзивную и неэксклюзивную. В рассматриваемом выше примере (рисунок 17) представлена иерархия категорий, где в качестве супертипа представлена сущность транспортное средство. В случае использования эксклюзивной иерархии категорий можно сказать, что транспортное средство является либо автомобилем, либо лодкой. Если изменить иерархию категорий на неэксклюзивную, то это будет говорить о том, что транспортное средство может быть автомобилем, либо лодкой, либо как лодкой, так и автомобилем одновременно (амфибия). Т.е. при эксклюзивной иерархии категорий экземпляр супертипа входит в экземпляр одного из подтипов, при неэксклюзивной иерархии категорий экземпляр супертипа может входить более чем в один подтип.
Примечание: в методике IE все иерархии категорий считаются полными.
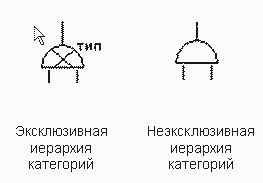
Рисунок 18. Типы иерархии категорий в методике IE
Заключение
AllFusion ERwin Data Modeler не ограничивает разработчика в том, какую методику моделирования данных использовать. Это возможно благодаря поддержке двух методик моделирования данных: методики IDEF1X и методики IE. Различий между ними немного, но их нужно понимать для успешного использования выбранной методики в процессе моделирования данных.
Дополнительная информация
- Подробнее о продуктах Computer Associates
- Подробнее о линейке интегрированных средств моделирования (CASE) - AllFusion Modeling Suite
- Обратиться в Interface Ltd. за дополнительной информацией/по вопросу приобретения продуктов
- Приобрести продукты Computer Associates в электронном магазине ITshop.ru
- Курсы по продуктам Computer Associates