
Аннотация
Эта статья поможет читателю настраивать сверхбольшие базы данных Oracle ( Very Large Database , в дальнейшем - VLDB) для достижения высокой производительности и высокой доступности при низких издержках на эксплуатацию. Она описывает решения выбора размера блока данных Oracle, применения RAID-технологий, использования «линейных» устройств ( raw-devices ), конфигурирования журнальных файлов, разбиения табличных пространств на разделы, выбора параметров хранения и настройки сегментов отката. Статья описывает технологии и связанные с ними ограничения, а также технически детальные методы для оптимизации конфигурации в рамках этих ограничений.
Содержание
- 1 Введение
- 1.1 Операционная сложность
- 1.2 Высокая производительность
- 1.3 Высокая доступность
- 1.4 Преодоление сложностей VLDB
- 2 Размер блока СУБД Oracle
- 2.1 Уменьшение нагрузки на ввод/вывод
- 2.2 Улучшение использования пространства
- 2.3 Предотвращение узких мест при параллелизме
- 2.4 Компромиссы
- 3 Дисковая конфигурация
- 3.1 Структурный анализ конфигурации
- 3.2 RAID
- 3.3 Размер сегмента чередования
- 3.4 Размер массива
- 3.5 Линейные устройства
- 3.6 Конфигурация Oracle
- 4 Журнальные файлы
- 4.1 Баланс производительности и доступности
- 4.2 Контрольные точки сервера Oracle
- 4.3 Восстановление инстанции сервера Oracle
- 4.4 Размещение журнальных файлов
- 4.5 Размер журнального файла
- 4.6 Число журнальных файлов
- 5 Планирование табличных пространств
- 5.1 Назначение сегментов табличным пространствам
- 6 Параметры хранения
- 6.1 Maxextents
- 6.2 Свойства параметров хранения
- 6.3 Выбор параметров хранения
- 7 Сегменты отката
- 7.1 Размер сегмента отката
- 7.2 Количество сегментов отката
- 8 Заключение
1 Введение
VLDB является аббревиатурой, принятой для обозначения СверхБольших Баз Данных ( Very Large Database ). Словосочетание «сверхбольшая» имеет разное наполнение для разных людей, но оно всегда связано с ощущением трудности, сложности, высокой стоимости и риска. VLDB являются тем, что люди связывают с огромными базами данных, поддержка которых граничит с искусством. Требуются большая изобретательность, умение планировать, упорный труд и значительные капиталовложения для того, чтобы избежать очень серьезных разочарований при попытке внедрения VLDB.
1.1 Операционная сложность
Операционная сложность является очевидной проблемой VLDB. Как оператор VLDB Вы должны постоянно оценивать множество сильно связанных параметров. Система будет «наказывать» попытки применить радикальные или случайные изменения. Огромные объекты и длительные процессы оставляют Вам мало пространства для маневра при устранении проблемы.
Это требует, в первую очередь, осторожности при планировании устранения проблемы. Состояние сотен или даже тысяч людей зависит от Вашей способности быстро принимать правильные решения. Здесь требуется талант и упорный труд.
Длительность многих важнейших процедур, например резервное копирование и восстановление, пропорциональна размеру объектов, которыми они манипулируют. Поэтому в больших БД эти важнейшие процедуры могут требовать очень больших временных интервалов. С ростом БД стоимость ошибок увеличивается. Операции - подобные реконфигурации диска, перестроению объекта БД, подсчету числа строк в таблице, откату транзакции, - могут выглядеть вполне безобидно в небольших БД, но быть полностью неприемлемыми для VLDB. Если действие требует нескольких часов Вашего рабочего времени, Вы должны избегать его выполнения.
1.2 Высокая производительность
Увеличивают сложность и другие факторы. Рассмотрим доступ к данным. Вы можете допустить использование неэффективного запроса, который требует 2 секунды работы процессора на высокопроизводительной современной системе с 20 пользователями, но Вы не сможете допустить такое же время обслуживания в системе с 1,200 пользователями, где идет непрерывная борьба за фиксаторы ( latches ), диски и процессорное время. Запросы к VLDB должны быть оптимизированы исключительно хорошо, иначе система развалится.
Более того, многие VLDB становятся «VL» в первую очередь вследствие большого числа одновременно работающих пользователей и пакетных заданий, создающих большой объем транзакций. Большой объем транзакций создает стрессовые ситуации в подсистеме ввода/вывода связанные с генерацией redo-информации и записью в файлы данных. Высокий уровень параллелизма процессов перегружает фиксаторы и механизмы блокировок, разработанные для перевода доступа к критическим ресурсам в последовательный режим ( serialize ).
1.3 Высокая доступность
Чем больше обдумываешь проблему - тем она сложней выглядит. VLDB часто являются источником данных для важных приложений с высокими требованиями доступности. Разработчики индустриальных СУБД слышат формулу «семь-дней-по-двадцать-четыре-часа», а мы цепенеем от монументальной сложности этой задачи. Ввиду электрических и сетевых неисправностей, некачественных модулей памяти и дисковых контроллеров, ошибок приложений и операционных систем, модернизации ПО и оборудования и просто случайных ошибок оператора, - достичь нескольких секунд или минут останова в год крайне сложно. Как обнаружить и исправить логические разрушения сотен и даже тысяч гигабайт данных, которые образовались вследствие ошибочного ввода оператора?
1.4 Преодоление сложностей VLDB
Путь к преодолению сложностей, присущих VLDB, лежит в упрощении БД настолько, насколько это возможно. Вы оптимизируете как СУБД, так и само приложение для снижения любых видов нагрузки. Вы выбираете структуры данных, которые минимизируют ввод/вывод при доступе к данным. Вы создаете приложения с максимально простыми транзакциями. Вы изолируете влияние вышедших из строя компонент на минимально возможные подмножества данных. Вы делайте единицы резервного копирования и восстановления минимально возможными.
Ниже перечислены некоторые аспекты, позволяющие построить хорошую VLDB:
- Оптимизация выполнения последовательности бизнес-операций
- Оптимизация логической модели данных
- Оптимизация схемы БД
- Построение надежной, высокопроизводительной конфигурации аппаратного обеспечения
- Оптимизация физической конфигурации БД
- Оптимизация SQL-операторов приложений
- Оптимизация операционной системы и инстанции сервера Oracle
- Создание корректных и надежных процедур сопровождения
В этой статье мы исследуем решения для физической конфигурации БД, необходимые для успешного построения VLDB.
2 Размер блока СУБД Oracle
Ирония жизни - в тот день, когда Ваш опыт в управлении сервером Oracle минимален, Вам необходимо ввести значение для параметра db_block_size, которое будет в дальнейшем неизменяемо на протяжении всей жизни БД. Важно то, что значение, которое Вы выбрали для размера блока данных Oracle, оказывает сильнейшее влияние на производительность системы. Последующие разделы обратят Ваше внимание на некоторые компромиссы, которые необходимо рассмотреть перед выбором размера блока данных Oracle для Вашей базы данных.
Оптимальный размер блока данных Oracle для VLDB лежит в пределах от 4KB до 64KB. Наиболее часто используемым является значение 8KB и, на втором месте, - 16KB. Сервер СУБД Oracle, установленный на системе с очень быстрой реализацией копирования больших объемов памяти может эффективно работать с размером блока в 32KB и даже (как минимум, теоретически) с 64KB. Я не знаком с обстоятельствами, которые могли бы требовать выбора размера блока для VLDB в 2KB и лишь в очень специальных случаях размер в 4KB будет подходящим для VLDB. В [6, Millsap (1996)] я давал развернутое техническое описание этого вопроса, здесь мы ограничимся только выводами 1.
2.1 Уменьшение нагрузки на ввод/вывод
Наиболее важной характеристикой самых сложных реализаций VLDB является огромная нагрузка на ввод/вывод. Владельцы лучших мировых VLDB вкладывают большие деньги в средства, способные уменьшить нагрузку на ввод/вывод в их системах. Использование большого размера блока данных СУБД Oracle является простой техникой для уменьшения некоторых видов нагрузки на ввод/вывод.
- Число операций ввода/вывода - аппаратура имеет вполне определенную цену одной операции ввода/вывода. Манипуляция с небольшим числом больших блоков данных будет иметь преимущества над манипуляциями большим числом блоков меньшего размера.
- Производительность индексов - скорость работы с индексами обратно пропорциональна высоте двоичного дерева ( B*-tree ) индекса. Больший размер блока Oracle позволит хранить больше ключей в одном блоке что, в свою очередь, даст лучшую производительность при поиске.
- Снижение сцеплений - сервер Oracle использует сцепление ( chaining ) для хранения строк таблиц, кластеров данных и хэштаблиц размер которых (строк) превышает размер блока данных. Сцепление частей строк между несколькими блоками данных приводит к увеличению числа операций ввода/вывода на одну обрабатываемую строку. Больший размер блока данных снижает вероятность того, что будет требоваться сцепления для хранения строки, и тем самым, уменьшает число операций ввода/вывода в системе.
2.2 Улучшение использования пространства
Сервер Oracle хранит небольшой объем служебной информации фиксированного размера в каждом блоке БД вне зависимости от того, какой объем пользовательских данных хранится в этом блоке. Таким образом, чем меньше блоков находится в БД, тем меньше пространства будет истрачено на накладные эти расходы. Для очень малых сегментов выигрыш от экономии на фиксированных накладных расходах может обернуться потерей пространства за счет неиспользуемых завершающих блоков сегмента, но эти потери, в свою очередь, незначительны по сравнению с потерями, вызванными неточным заданием параметров хранения 2. Использование большого размера блока Oracle для очень больших сегментов сохраняет примерно от двух до шести процентов общего объема базы данных.
Этот выигрыш ведет к повышению производительности и снижению стоимости эксплуатации, что особенно заметно на снижении времени резервного копирования/восстановления.
2.3 Предотвращение узких мест при параллелизме
Использование большого размера блока данных Oracle увеличивает риск возникновения узких мест при совместном доступе за исключением случаев, когда архитектор базы данных понимает как использовать параметры хранения initrans и maxtrans. Значение initrans должно быть установлено в максимально ожидаемое число транзакций, одновременно манипулирующих блоком данных 3. Таким образом, если Вы увеличили размер блока данных Oracle в k раз, то Вам необходимо увеличить значение параметра initrans также в k раз. Для того чтобы позволить динамически расти «таблице списка входов транзакций», Вам необходимо установить значение параметра maxtrans в значение, превышающее значение initrans 4.
Неудачный выбор параметров initrans и maxtrans для сегментов базы данных может быть причиной возникновения ожиданий пользовательских сессий. Сессии, которые изменяют блок, имеющий эту проблему, будут мешать другим сессиям получить входы в структуру данных блока, которая позволяют делать реконструкцию данных для достижения непротиворечивости чтения. Эта ситуация, имеющая название ITL-конкуренция , может быть обнаружена администраторами БД с помощью представления v$lock. Наблюдения будут показывать сессии, ожидающие на блокировке TX (очередь транзакций) в режиме блокировки 4 (разделяемый доступ).
Вы в состоянии полностью избежать этих проблем, используя соответствующие техники, описанные в стандартной документации компании Oracle по настройке параметров initrans и maxtrans для сегментов БД.
2.4 Компромиссы
Хотя большой размер блока данных Oracle имеет преимущества для VLDB, имеются определенные ограничения на максимальный размер блока данных который Вы можете выбрать.
- Физический размер ввода/вывода - Размер блока данных СУБД Oracle не должен превышать максимально возможный размер физической операции чтения данных. Убедитесь также, что размер пакетного чтения для операции полного сканирования таблицы ограничен максимальным размером физического чтения операционной системы. К примеру, если размер блока данных Вашей СУБД равен 32KB и параметр db_file_multiblock_read_count равен 32 то маловероятно, что Вы сможете выбирать 1MB = 32KB × 32KB за одну физическую операцию чтения.
- Redo-размер - Процесс, пишущий в журнальные файлы Oracle (LGWR) записывает целые блоки при изменениях в файлах данных табличных пространств, переведенных в состояние резервного копирования. Поэтому решение уменьшить объем генерируемой redo-информации в течение «горячего» резервного копирования, может мотивировать Вас ограничить размер блока данных Oracle.
- Размер копируемой области памяти - В случае, если Вы выберите размер блока данных, превышающий максимальный размер памяти, который операционная система в состоянии обработать за одну операцию, Вы может наблюдать увеличение загрузки процессора и снижение производительности, связанные с обработкой больших блоков в SGA.
- Ограничения параллелизма - Максимальное значения для параметров initrans и maxtrans равно 255. Если блок данных СУБД Oracle при обычных нагрузках получает более 255 запросов от транзакций на изменение, то это значит, что размер блока данных выбран слишком большим. Шансы возникновения токай ситуации близки к нулю: если действительно 255 транзакций одновременно модифицируют один блок, то результирующая конкуренция за фиксаторы будет настолько серьезной, что Вам непременно придется увеличить параметр pctfree для такого сегмента.
3 Дисковая конфигурация
Сердцем хорошей СУБД является надежная и производительная подсистема ввода/вывода. Поэтому проектирование подсистемы ввода/вывода - важная тема при создании любого приложения с использованием VLDB.
3.1 Структурный анализ конфигурации
На самом высоком уровне абстракции определение требований к системе является простым делом, поскольку все мы желаем трех вещей: производительности, надежности и низкой стоимости . Однако когда мы преобразуем эти общезначимые цели во что-то конкретное, мы сталкиваемся с решениями, основанными на компромиссах. Для понимания возникших конфликтов, Вы должны сделать две вещи: (1) понять Ваши цели и (2) разобраться в Ваших технологиях. Весь фокус заключается в поиске верной микстуры из скорости, надежности и стоимости, которая удовлетворит специфичные нужды Вашего бизнеса. Это означает что решение, верное для Вас, не всегда будет подходящим для Вашего соседа.
Архитектурные ограничения приходят к нам из двух источников: (1) это экономические ограничения и (2) это технологические ограничения. Экономические ограничения Вам должны быть ясны очень хорошо, и я уверен, Вы не желаете иметь с ними дело. Однако, даже если вообразить, что Вы можете приобрести любое оборудование и программное обеспечение, какое только пожелаете, Вы все равно столкнетесь с ограничениями технологическими.
Предположим, к примеру, что Вы имеете OLTP-приложение и Вы оптимизировали дисковую конфигурацию Вашего сервера Oracle для достижения максимальной производительности при случайном вводе/выводе в ущерб производительности последовательного доступа к данным. Такое решение может выглядеть вполне разумным, поскольку доступ к файлам OLTP-базы данных в подавляющем большинстве основан на операциях чтения с использованием хорошо определенных индексов или хэш-структур, а также произвольных ( scattered ) операциях записи.
Однако первый же опыт реорганизации индекса на дисковом массиве, оптимизированном исключительно для доступа в условиях высокого параллелизма, потребует на 300-500 процентов больше времени, чем это могло бы занять в другой дисковой конфигурации. Ваше бескомпромиссное решение об оптимизации OLTPпроизводительности напрямую снизит доступность Вашей системы вследствие увеличения продолжительности недоступности индекса во время его реорганизации.
Этот пример, как сотни подобных, указывают нам на важность и трудоемкость понимания Ваших требований и постижения Ваших технологий. Наиболее важным Вашим инструментом должен стать метод структурного анализа, который поможет Вам найти правильные ответы на Ваши вопросы. В этой статье мы будет структурировать анализ конструкции подсистемы ввода/вывода с помощью разбиения на производительность, доступность и стоимость:
- Производительность
- Скорость случайного чтения
- Скорость случайной записи
- Скорость последовательного чтения
- Скорость последовательной записи
- Влияние параллелизма
- Доступность
- Частота отказов
- Продолжительность простоя
- Снижение производительности при отказах
- Стоимость
- Стоимость приобретения
- Стоимость обслуживания
В статье мы оценим несколько инструментов и техник в контексте этих категорий. Их описание дано в последующих разделах.
3.1.1 Производительность
- Производительность случайного чтения - примером могут служить запрос с использованием индексов или хэш-структур, чтение из сегментов отката. По-видимому, эта категория составляет основную массу вызовов операций чтения в высокоактивной OLTP-системе. Для хранилищ данных, эта категория представляет лишь незначительную часть от общей нагрузки.
- Производительность случайной записи - примером могут служить все операции записи данных, индексов и сегментов отката процессом DBWR. Эта категория составляет существенную часть общей массы операций записи в OLTP-системах в период основной работы. Для хранилищ данных данная категория составляет незначительную или нерегулярную долю нагрузки.
- Производительность последовательного чтения - примерами могут служить резервное копирование, полное сканирование таблиц, создание индексов, параллельное выполнение запросов, чтение из временных сегментов, операции восстановления и доката из журнальных файлов. Даже для хорошо оптимизированных OLTP-приложений, эта категория должна рассматриваться как составная часть нагрузки, особенно для систем с интенсивными пакетными заданиями. Для хранилищ данных последовательное чтение может может быть практически единственным видом чтения.
- Производительность последовательной записи - примером служит работа LGWR-процесса, запись во временные сегменты, прямые загрузки данных ( direct-load ), создание индексов, создание табличных пространств и операция восстановления. Проектировщики, акцентируясь на транзакциях и обработке запросов иногда забывают эту категорию. Хотя во время первичной загрузки данных и в течении всей эксплуатации база данных любого типа генерирует большое число операций последовательной записи.
- Влияние параллелизма - в каждой из категорий, упомянутых выше, архитектор должен рассмотреть влияние различных уровней параллелизма.
3.1.2 Доступность
- Частота отказов - ожидаемое число случаев возникновения отказов в единицу времени. Частота отказов определяется с помощью MTTF ( mean time to failure - среднее время возникновения отказа). Для примера, у жесткого диска с MTTF равным 20,000 часов можно ожидать отказ каждые 23 года.
- Продолжительность простоя - стоимость простоя может быть оценена в деньгах, количество которых определяются как некоторая функция от продолжительности простоя. Стоимость простоя для некоторого события пропорциональна показателю среднего времени восстановления ( MTTR, mean time to repair ) для данного события - чем дольше продолжительность простоя, тем выше стоимость.
- Снижение производительности в течение отказа - различным дисковым конфигурациям присущи различные показатели производительности при возникновении отказа. Некоторые конфигурации не являются отказоустойчивыми вообще, в других при возникновении отказов снижается производительность, третьи вовсе нечувствительны к возникновению различных типов отказов.
Важно сопоставить требования приложения с ожидаемым падением производительности при возникновении отказа.
3.1.3 Стоимость
- Стоимость приобретения - экономическая оценка закупки системы.
- Стоимость обслуживания - стоимость эксплуатации и поддержания системы. Стоимость обслуживания состоит из эксплуатационных издержек, которые зависят от надежности системы и из административных затрат, зависящих от сложности системы. Например, система сложная в обращении, требующая более подготовленных операторов и техников по ремонту, будет иметь более высокую стоимость обслуживания.
3.1.4 Метод анализа
Декомпозиция на производительность, надежность и стоимость дает нам важный инструмент для построения хорошей системы. Он позволяет нам оценить компромиссы как в пределах одной категории (например - скорость выполнения случайного чтения за счет последовательного чтения), так и понять влияние одной категории на другую (например - сильную связь между скоростью выполнения последовательной записи и продолжительностью простоя).
Эти категории также позволяет нам формализовать наши рассуждения о системе. К примеру, понимание разных составляющих понятия надежности дает нам возможность изучать их независимо: (1) мы можем фокусировать усилия на снижении частоты отказов или (2) мы можем попытаться снизить продолжительность простоев вследствие отказов, которые мы предотвратить не в силах. И это напоминает нам еще раз, что продолжительность простоя является частично вопросом надежности, а частично - вопросом производительности.
Последующие разделы помогут Вам провести высокоуровневый анализ взаимосвязей производительности, доступности и стоимости при проектировании подсистемы ввода/вывода для СУБД Oracle. Этот раздел поможет Вам лучше понять Ваши задачи и технологии, поможет сделать Вам более информированные решения, чтобы Вы получили наилучший результат от Ваших инвестиций.
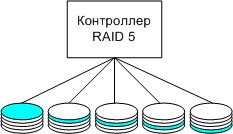
3.2 RAID
На втором месте по ненадежности, после человека, в компьютерных системах, является жесткий диск. Для увеличения надежности дисков большинство поставщиков решений сегодня предлагают дисковые массивы, называемые RAID - избыточные массивы недорогих дисков ( redundant arrays of inexpensive disks ). RAID-массивы представляют собой высокопроизводительные, устойчивые к отказам подсистемы ввода/вывода, которые используют менее дорогие технологии жестких дисков чем те, что используются в традиционных высоконадежных больших ЭВМ.
Понятие RAID было введено в 1987 году в статье, опубликованной в Калифорнийском Университете [9, Patterson et al.(1988)]. Номера уровней RAID означают разную организацию простых технологий дисков для достижения производительности и надежности при относительно невысокой стоимости.
Наиболее важными уровнями RAID, которые должен понимать архитектор VLDB Oracle являются 0, 0+1, 3 и 5. Рисунок 1 дает концептуальное представление об этих RAID-конфигурациях. Обратите внимание, что поставщики RAID могут выбрать для реализации функций чередования и зеркалирования либо программное, либо аппаратное решение. Этот выбор влияет на количество и типы контроллеров необходимых для реализации RAID-массива.
Производительность, предлагаемая RAID-конфигурациями, впечатляет. За счет равномерного распределения физической нагрузки ввода/вывода по всем дискам, RAID-массивы с чередованием показывают бесподобное время ответа и пропускную способность. Массив с чередованием из пяти дисков может показать почти в пять раз большую производительность при последовательном вводе/выводе по сравнению с независимой конфигурацией дисков того же размера.
Равным образом впечатляет превосходство RAID-массивов в надежности. Дисковая система, состоящая из сотни дисков с MTTF равной 200.000 часов, сконфигурированная без избыточности имеет среднее время до потери данных (MTTDL) меньшее чем 83 дня. Та же сотня дисков, организованная в RAID-массив с наличием избыточности имеют MTTDL порядка 26 лет [Chen et al.(1992), 161-163]. Среднее время восстановления RAID-конфигураций также превосходно. Вы можете изъять диск из активного RAID-массива 5 уровня и система, тем не менее, будет продолжать работать.
Однако, каждая RAID-конфигурация имеет свою, уникальную, стоимость. Вы можете обнаружить, что система, которая действительно удовлетворяет Вашим нуждам слишком дорога, а конфигурация, которую Вы в состоянии себе позволить, несет с собой много компромиссных решений. Архитекторы систем на базе СУБД Oracle должны двигаться в извилистом лабиринте компромиссов, принимая решение о способе применения RAID-массивов.
Несколько авторов сделали блестящую работу, описывая RAID-конфигурации и оценивая RAID-структуры с точки зрения надежности, производительности и стоимости ( [1, Chen et al.(1994)]; [2, Gui (1993)]; [11, Sun (1995)]; и многие другие). Последующие разделы содержат итоги этих идей с конкретными рекомендациями о том, когда и как использовать каждый тип RAID-массива для приложений СУБД Oracle.
3.2.1 Определения
Учебная литература о RAID может иногда ввести в заблуждение, поскольку авторы из конъюнктурных соображений могут интерпретировать определения так, как им необходимо. Для того, чтобы сделать эту статью максимально простой, определим предварительно некоторые термины.
- Массив - RAID-конфигурация 0, 0+1, 3 и 5 уровня, в которой диски группируются в наборы, называемые группами с коррекцией ошибок или дисковыми массивами . Мы будем называть группу дисков собранных в группу с коррекцией ошибок массивом .
- Сегмент чередования - чередование ( striping ), это программная или аппаратная возможность, при которой логически непрерывные данные записываются порциями, распределенными между дисками в массиве 5. Эти порции называются сегментами.
Читая этот документ, важно помнить что, массив является коллекцией дисков, и что чередование заключается в распределении порций данных в пределах массива. Рисунок ниже показывает один дисковый массив, состоящий из пяти дисков. Каждый диск содержит пять сегментов чередования, общее число которых составляет 25.
3.2.2 Чередование без избыточности (RAID уровня 0)
RAID 0 является дисковой конфигурацией без избыточности с чередованием. Чередование, сконфигурированное соответствующим образом, дает исключительно хорошее время ответа при случайном доступе с высоким уровнем параллелизма, и превосходную пропускную способность при последовательном доступе с низким уровнем параллелизма. Выбор ширины сегмента чередования массива требует внимательного рассмотрения различных ограничений. Мы обсудим детали оптимизации размера сегмента чередования позже.
Дисковые конфигурации без избыточности полезны в тех случаях, где ограничения на стоимость приобретения перевешивают требования к надежности системы.
- Производительность при случайном чтении - отличная при любых уровнях параллелизма, если каждый запрос на чтение попадает в один сегмент чередования. Использование слишком малого размера сегмента чередования может привести к резкому снижению производительности в средах с высоким уровнем параллелизма.
- Производительность при случайной записи - та же, что и для случайного чтения.
- Производительность при последовательном чтении - отличная при малом размере сегмента чередования в средах с низким уровнем параллелизма. Также отличная в средах с высоким уровнем параллелизма при условии, что каждый запрос на чтение попадает в один сегмент чередования. Использование слишком малого размера сегмента чередования может привести к резкому снижению производительности в средах с высоким уровнем параллелизма.
- Производительность при последовательной записи - та же, что и для последовательного чтения.
- Частота отказов - неудовлетворительна. Отказ любого диска массива будет причиной отказа приложений, требующего процедуры восстановления носителя Oracle для каждого приложения, имеющего данные на этом массиве.
- Длительность простоя - неудовлетворительна. Продолжительность простоя RAID 0 состоит из времени, необходимого на обнаружение неисправности, замены диска и выполнении процедуры восстановлении носителя сервера Oracle.
- Снижение производительности в течение отказа - неудовлетворительно. Любой диск, вышедший из строя, влечет за собой останов приложений, данные которых располагались на дисковом массиве, до полного завершения процедуры восстановления носителя Oracle.
- Стоимость приобретения - отличная. RAID 0 является наименее дорогой RAIDконфигурацией.
- Стоимость обслуживания - от неудовлетворительной до плохой. Цена обслуживания, обусловленная частотой выполнения процедуры восстановления носителя, может превысить ценовые преимущества на приобретение перед избыточными конфигурациями. Необходимость увеличения емкости потребует либо закупки дополнительных массивов, либо переконфигурирования существующих массивов. Требуется обучение при конфигурировании дисковых массивов с чередованием для достижения оптимальной производительности.
3.2.3 Зеркалирование (RAID уровня 1)
Зеркалирование является фундаментальным инструментом архитектора VLDB для снижения частоты отказов дисков. Диски с поддержкой зеркальных копий - это системы, в которых идентичные копии Ваших данных записываются на два или более дисков при каждой операции записи, что позволяет Вашим приложениям работать до тех пор, пока цела хотя бы одна из копий. Несмотря на то, что наблюдается определенная потеря производительности при выполнении операции записи в массивах с зеркалированием по сравнению с конфигурациями без избыточности, зеркалирование обеспечивает наилучшую производительность операции записи среди дисковых конфигураций, устойчивых к сбоям. Зеркалирование особенно полезно для хранения файлов данных Oracle с высокой интенсивностью записи. Многие архитекторы используют зеркалирование для защиты оперативных и архивных журнальных файлов даже тогда, когда стоимостные ограничения не позволяют использования зеркалирования всей дисковой подсистемы.
Дублирование адаптеров, шин и источников питания делает зеркалирование еще более нечувствительным к отказам оборудования. В продублированной конфигурации с зеркалированием, n- уровневая избыточность использует n одинаковых адаптеров. На сегодняшний день несколько клиентов компании Oracle используют трехуровневое дублирование для достижения гибкости операции восстановления. Тройное зеркалирование обеспечивает устойчивость к отказам подобно двойному зеркалированию и позволяет администратору БД восстанавливать СУБД на любое время в прошлом без использования стримеров. Позже мы обсудим одну технику тройного дублирования.
- Производительность при случайном чтении - хорошая. Если реализация контроллера RAID 1 оптимизирует операцию чтения, то несколько выше, чем у независимого диска, в противном случае - идентична независимому диску. Контроллер RAID 1 с оптимизатором будет обслуживать запрос на чтение, используя ту копию, для которой стоимость выполнения операции чтения минимальна, оставляя другой диск(и) в зеркальной группе для параллельного обслуживания других запросов.
- Производительность при случайной записи - хорошая. Если реализация контроллера RAID 1 использует оптимизацию чтения, то несколько хуже, чем у независимого диска, в противном случае - идентична независимому диску. Хотя запись нескольких копий может выполняться параллельно, скорость всей операции записи ограничена скоростью самого медленного устройства. Цена записи n-уровневой реализации RAID 1 равна max( w1,w2, · · · ,wn ), где wi - цена записи на i -тое устройство. Оптимизация чтения данных рассинхронизирует состояния зеркалированных дисков, вследствие чего wi ≠ wj для i ≠ j даже для идентичных дисков.
- Производительность при последовательном чтении - удовлетворительная. См. производительность при случайном чтении. Про пускная способность ограничена производительностью одного диска.
- Производительность при последовательной записи - удовлетворительная. См. производительность при случайной записи. Пропускная способность ограничена производительностью одного диска.
- Частота отказов - отличная. N -уровневое дублирование дисковой системы может обеспечить работоспособность системы при выходе из строя до n . 1 дисков в зеркальном наборе. Однако RAID 1 не устраняет проблемы выхода из строя адаптера, шины ввода/вывода, RAID-контроллера, источника питания, аппаратных или программных ошибок. Для устранения этих видов ошибок необходимо дублирование оборудования. При n -кратном дублировании всех компонент система останется работоспособной при выходе из строя до n -1 адаптеров, шин ввода/вывода и пр. в пределах одного комплекта дублирования. Дублирование является наиболее отказоустойчивой дисковой конфигурацией.
- Длительность простоя - отличная. Продолжительность отказа, вызванного n - 1 или меньшим числом дисков или других продублированных компонент равно периоду времени, необходимому для замены этих компонент. В течение этого времени все приложения находятся в рабочем состоянии. Продолжительность простоя при потере данных, обусловленной выходом из строя всех n дисков сопоставима с показателем для RAID 0 конфигурации. В этом случае все зависимые приложения будут недоступны.
- Снижение производительности в течение отказа - отличное. При выходе из строя диска в RAID 1 не будет наблюдаться снижения производительности всего массива. Однако, на время замены диска, операция включения нового диска в массив будет генерировать большой объем ввода/вывода в восстанавливаемой зеркальной группе, что может привести к существенному снижению производительности приложений, читающих или записывающий данные на эту зеркальную группу. Замена других продублированных аппаратных компонент не влечет за собой снижения производительности.
- Стоимость приобретения - плохая. Стоимость емкости при n -уровневом зераклировании в n раз выше, чем стоимость аналогичной емкости для RAID 0. Реализация RAID 1 требует специального контроллера RAID 1 в дополнение к тому же числу адаптеров, что и для RAID 0. Полное зеркалирование ограничено возможностями подсистемы ввода/вывода, поскольку n-уровневое зеркалирование требует в n раз больше посадочных мест, чем конфигурации без избыточности.
- Стоимость обслуживания - удовлетворительная. Стоимость включает обучение персонала администрированию систем с использованием зеркалирования, разработку программного обеспечения для интеграции процедур зеркалирования в плановые операции обслуживания и т.д.
| Чтобы не заставлять Вас искать указанный документ компании Oracle, что кстати является не простым делом, скажу, что одним из специальных случаев, когда выбор в 4KB будет подходящим, заключается в наличии огромного числа небольших сегментов (меньше 100KB). | |
| Как мы обсудим позднее, приближенное задание параметров хранения является хорошим компромиссным решением, снижающим стоимость эксплуатации, в сравнении с VLDB с очень точно заданными параметрами хранения. | |
| Под транзакцией здесь понимается выполнение операторов insert, update, delete, или select . . . for update | |
| Формально, «таблица списка входов транзакций» называется списком интересующихся транзакций ( interested transactions list ), или ITL . | |
| Обратите внимание - striping пишется с одной буквой p . |