
- Отключенные предупреждения
- Использование функций с переменным количеством аргументов
- Магические константы
- Хранение в double целочисленных значений
- Операции сдвига
- Упаковка указателей
- Memsize-типы в объединениях
- Изменение типа массива
- Виртуальные функции с аргументами типа memsize
- Сериализация и обмен данными
- Битовые поля
- Адресная арифметика с указателями
- Индексация массивов
- Смешанное использование простых целочисленных типов и memsize-типов
- Неявные приведения типов при использовании функций
- Перегруженные функции
- Выравнивание данных
- Исключения.
- Использование устаревших функций и предопределенных констант.
- Явные приведения типов
- Диагностика ошибок
- Юнит-тестирование
- Просмотр кода
- Встроенные средства компиляторов
- Статические анализаторы
- Заключение
- Ресурсы
Вашему вниманию предлагается статья, посвященная переносу программного кода 32-битных приложений на 64-битные системы. Статья составлена для программистов, использующих Си++, но может быть полезна всем, кто сталкивается с переносом приложений на другие платформы.
Нужно четко понимать, что новый класс ошибок, возникающий при написании 64-битных программ, не просто еще несколько новых некорректных конструкций, среди тысяч других. Это означает неминуемые сложности, с которыми столкнутся разработчики любой развивающейся программы. Данная статья поможет быть готовым к этим трудностям и покажет пути их преодоления.
Любая новая технология (как в программировании, так и в других областях) несет в себе помимо преимуществ, также и некоторые ограничения или даже проблемы использования этой технологии. Точно такая же ситуация сложилась и в области разработки 64-битного программного обеспечения. Мы все знаем о том, что 64-битное программное обеспечение - это следующий этап развития информационных технологий. Однако немногие программисты пока реально столкнулись с нюансами этой области, а именно разработки 64-битных программ.
Мы не будем задерживаться на преимуществах, которые открывает перед программистами переход на 64-битную архитектуру. Данной тематике посвящено большое количество публикаций, и читателю не составит труда их найти.
Целью этой статьи является подробный обзор тех проблем, с которыми может столкнуться разработчик 64-битных программ. В статье Вы познакомитесь:
- с типовыми ошибками программирования, проявляющими себя на 64-битных системах;
- с причинами, по которым эти ошибки проявляют себя (с соответствующими примерами);
- с методами устранения перечисленных ошибок;
- с обзором методик и средств поиска ошибок в 64-битных программах.
Приведенная информация позволит Вам:
- узнать отличия 32-битных и 64-битных систем;
- избежать ошибок при написании кода для 64-битных систем;
- ускорить процесс миграции 32-битного приложения на 64-битную архитектуру за счет существенного сокращения времени отладки и тестирования;
- более точно и обоснованно прогнозировать время переноса кода на 64-битную систему.
Для лучшего понимания изложенного материала, в статье приводится много примеров. Знакомясь с ними, Вы получите нечто большее суммы отдельных частей. Вы откроете дверь в мир 64-битных систем.
Для облегчения понимания дальнейшего текста вначале вспомним некоторые типы, с которыми мы можем столкнуться (см. таблица N1).
|
Название типа |
Размерность типа в битах (32-битная система) |
Размерность типа в битах (64-битная система) |
Описание |
|---|---|---|---|
| ptrdiff_t | 32 | 64 | Знаковый целочисленный тип, образующийся при вычитании двух указателей. Используется для хранения размеров. Иногда используется в качестве результата функции, возвращающей размер или -1 при возникновении ошибки. |
| size_t | 32 | 64 | Беззнаковый целочисленный тип. Результат оператора sizeof(). Служит для хранения размера или количества объектов. |
| intptr_tu intptr_t SIZE_TS SIZE_T INT_PTR DWORD_PTR и т. д. | 32 | 64 | Целочисленные типы, способные хранить в себе значение указателя. |
| time_t | 32 | 64 | Время в секундах. |
В тексте будет использоваться термин "memsize" тип. Под memsize-типом мы будем понимать любой простой целочисленный тип, способный хранить в себе указатель и меняющий свою размерность при изменении разрядности платформы с 32-бит на 64-бита. Примеры memsize-типов: size_t, ptrdiff_t, все указатели, intptr_t, INT_PTR, DWORD_PTR.
Несколько слов следует уделить моделям данных, определяющим соотношения размеров фундаментальных типов для различных систем. В таблице N2 приведены модели данных, которые могут быть нам интересны.
|
ILP32 |
LP64 |
LLP64 |
ILP64 | |
|---|---|---|---|---|
| char | 8 | 8 | 8 | 8 |
| short | 16 | 16 | 16 | 16 |
| int | 32 | 32 | 32 | 64 |
| long | 32 | 64 | 32 | 64 |
| long long | 64 | 64 | 64 | 64 |
| size_t | 32 | 64 | 64 | 64 |
| pointer | 32 | 64 | 64 | 64 |
По умолчанию в статье будет считаться, что перенос программ осуществляется с системы, имеющей модель данных ILP32, на системы с моделью данных LP64 или LLP64.
И последнее: 64-битная модель в Linux (LP64) и Windows (LLP64) имеет различие только в размерности типа long. Поскольку это их единственное отличие, то для обобщения изложения мы будем избегать использования типов long, unsigned long, и будем использовать типы ptrdiff_t, size_t.
Приступим к рассмотрению типовых ошибок, возникающих при переносе программ на 64-битную архитектуру.
1. Отключенные предупреждения
Во всех книгах, посвященных разработке качественного кода, рекомендуется выставлять уровень предупреждений, выдаваемых компилятором на как можно более высокий. Но на практике встречаются ситуации, когда для определенных частей проекта выставлен меньший уровень диагностики или вообще выключен. Обычно это очень старый код, который продолжает поддерживаться, но не модифицируется. Программисты, работающие в проекте, привыкли, что этот код работает, и закрывают глаза на его качество. Здесь и кроется опасность пропустить серьезные предупреждения компилятора при переносе программ на новую 64-битную систему.
При переносе приложения следует обязательно включить предупреждения для всего проекта, помогающие проверить код на совместимость и внимательно проанализировать их. Это может существенно сэкономить время при отладке проекта на новой архитектуре.
Если этого не сделать, то самые глупые и простые ошибки будут проявлять себя во всем своем многообразии. Вот простейший пример переполнения, который возникнет в 64-битной программе, если полностью игнорировать предупреждения:
unsigned char *array[50]; unsigned char size = sizeof(array); 32-bit system: sizeof(array) = 200 64-bit system: sizeof(array) = 400
2. Использование функций с переменным количеством аргументов
Классическим примером является некорректное использование функций printf, scanf и их разновидностей:
1) const char *invalidFormat = "%u"; size_t value = SIZE_MAX; printf(invalidFormat, value);
2) char buf[9]; sprintf(buf, "%p", pointer);
В первом случае не учитывается, что тип size_t не эквивалентен типу unsigned на 64-битной платформе. Это приведет к выводу на печать некорректного результата, в случае если value > UINT_MAX.
Во втором случае автор кода не учел, что размер указателя в будущем может составить более 32 бит. В результате на 64-битной архитектуре данный код приведет к переполнению буфера.
Некорректное использование функций с перемененным количеством параметров является распространенной ошибкой на всех архитектурах, а не только 64-битных. Это связано с принципиальной опасностью использования данных конструкций языка Си++. Общепринятой практикой является отказ от них и использование безопасных методик программирования. Мы настоятельно рекомендуем модифицировать код и использовать безопасные методы. Например, можно заменить printf на cout, а sprintf на boost::format или std::stringstream.
Если Вы вынуждены поддерживать код, использующий функции типа sscanf, то в формате управляющих строк можно использовать специальные макросы, раскрывающиеся в необходимые модификаторы для различных систем. Пример:
// PR_SIZET on Win64 = "I"
// PR_SIZET on Win32 = ""
// PR_SIZET on Linux64 = "l"
// ...
size_t u;
scanf("%" PR_SIZET "u", &u);
3. Магические константы
В некачественном коде часто встречаются магические числовые константы, наличие которых опасно само по себе. При миграции кода на 64-битную платформу эти константы могут сделать код неработоспособным, если участвуют в операциях вычисления адреса, размера объектов или в битовых операциях.
В таблице N3 перечислены основные магические константы, которые могут влиять на работоспособность приложения на новой платформе.
|
Значение |
Описание |
|---|---|
| 4 | Количество байт в типе |
| 32 | Количество бит в типе |
| 0x7fffffff | Максимальное значение 32-битной знаковой переменной. Маска для обнуления старшего бита в 32-битном типе. |
| 0x80000000 | Минимальное значение 32-битной знаковой переменной. Маска для выделения старшего бита в 32-битном типе. |
| 0xffffffff | Максимальное значение 32-битной переменной. Альтернативная запись -1 в качестве признака ошибки. |
Следует внимательно изучить код на предмет наличия магических констант и заменить их безопасными константами и выражениями. Для этого можно использовать оператор sizeof(), специальные значения из <limits.h>, <inttypes.h> и так далее.
Приведем несколько ошибок, связанных с использованием магических констант. Самой распространенной является запись в виде числовых значений размеров типов:
1) size_t ArraySize = N * 4; intptr_t *Array = (intptr_t *)malloc(ArraySize);
2) size_t values[ARRAY_SIZE]; memset(values, ARRAY_SIZE * 4, 0);
3) size_t n, newexp; n = n >> (32 - newexp);
Во всех случаях, предполагаем, что размер используемых типов всегда равен 4 байта. Исправление кода заключается в использовании оператора sizeof():
1) size_t ArraySize = N * sizeof(intptr_t); intptr_t *Array = (intptr_t *)malloc(ArraySize);
2) size_t values[ARRAY_SIZE]; memset(values, ARRAY_SIZE * sizeof(size_t), 0);
или
memset(values, sizeof(values), 0); //preferred alternative
3) size_t n, newexp; n = n >> (CHAR_BIT * sizeof(n) - newexp);
Иногда может потребоваться специфическая константа. В качестве примера мы возьмем значение size_t, где все биты кроме 4 младших должны быть заполнены единицами. В 32-битной программе эта константа может быть объявлена следующим образом:
// constant '1111..110000' const size_t M = 0xFFFFFFF0u;
Это некорректный код в случае 64-битной системы. Такие ошибки очень неприятны, так как запись магических констант может быть осуществлена различными способами и их поиск достаточно трудоемок. К сожалению, нет никаких других путей, кроме как найти и исправить этот код, используя директиву #ifdef или специальный макрос.
#ifdef _WIN64 #define CONST3264(a) (a##i64) #else #define CONST3264(a) (a) #endif const size_t M = ~CONST3264(0xFu);
Иногда в качестве кода ошибки или другого специального маркера используют значение "-1", записывая его как "0xffffffff". На 64-битной платформе записанное выражение некорректно и следует явно использовать значение -1. Пример некорректного кода, использующего значение 0xffffffff как признак ошибки:
#define INVALID_RESULT (0xFFFFFFFFu)
size_t MyStrLen(const char *str) {
if (str == NULL)
return INVALID_RESULT;
...
return n;
}
size_t len = MyStrLen(str);
if (len == (size_t)(-1))
ShowError();
На всякий случай уточним Ваше понимание, чему с вашей точки зрения равно значение "(size_t)(-1)" на 64-битной платформе. Можно ошибиться, назвав значение 0x00000000FFFFFFFFu. Согласно правилам языка Си++ сначала значение -1 преобразуется в знаковый эквивалент большего типа, а затем в беззнаковое значение:
int a = -1; // 0xFFFFFFFFi32 ptrdiff_t b = a; // 0xFFFFFFFFFFFFFFFi64 size_t c = size_t(b); // 0xFFFFFFFFFFFFFFFui64
Таким образом, "(size_t)(-1)" на 64-битной архитектуре представляется значением 0xFFFFFFFFFFFFFFFui64, которое является максимальным значением для 64-битного типа size_t.
Вернемся к ошибке с INVALID_RESULT. Использование константы 0xFFFFFFFFu приводит к невыполнению условия "len == (size_t)(-1)" в 64-битной программе. Наилучшее решение заключается в изменении кода так, чтобы специальных маркерных значений не требовалось. Если по какой-то причине Вы не можете от них отказаться или считаете нецелесообразным существенные правки кода, то просто используйте честное значение -1.
#define INVALID_RESULT (size_t(-1)) ...
4. Хранение в double целочисленных значений
Тип double, как правило, имеет размер 64-бита, и совместим со стандартом IEEE-754 на 32-битных и 64-битных системах. Некоторые программисты используют тип double для хранения и работы с целочисленными типами:
size_t a = size_t(-1);
double b = a;
--a;
--b;
size_t c = b; // x86: a == c
// x64: a != c
Данный пример еще можно пытаться оправдывать на 32-битной системе, так как тип double имеет 52 значащих бит и способен без потерь хранить 32-битное целое значение. Но при попытке сохранить в double 64-битное целое число точное значение может быть потеряно (см. рисунок 1).
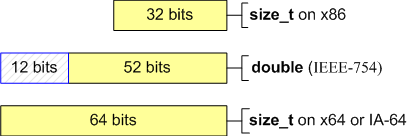
Рисунок 1. Количество значащих битов в типах size_t и double.
Возможно, приближенное значение вполне применимо в Вашей программе, но на всякий случай хочется сделать предупреждение о потенциальных эффектах на новой архитектуре. И в любом случае не рекомендуется смешивать целочисленную арифметику и арифметику с плавающей точкой.
5. Операции сдвига
Операции сдвига при невнимательном использовании, могут принести много неприятностей во время перехода от 32-битной к 64-битной системе. Начнем с примера функции, выставляющей в переменной типа memsize, указанный вами бит в 1:
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {
ptrdiff_t mask = 1 << bitNum;
return value / mask;
}
Приведенный код работоспособен на 32-битной архитектуре и позволяет выставлять биты с номерами от 0 до 31. После переноса программы на 64-битную платформу возникнет необходимость выставлять биты от 0 до 63. Как Вы думаете, какое значение вернет следующий вызов функции SetBitN(0, 32)? Если Вы думаете, что 0x100000000, то авторы рады, что не зря подготовили эту статью. Вы получите 0.
Обратите внимание, что "1" имеет тип int и при сдвиге на 32 позиции произойдет переполнение, как показано на рисунке 2.

Рисунок 2. Вычисление выражения "ptrdiff_t mask = 1 << bitNum".
Для исправления кода необходимо сделать константу "1" того же типа, что и переменная mask.
ptrdiff_t mask = ptrdiff_t(1) << bitNum;
или
ptrdiff_t mask = CONST3264(1) << bitNum;
Еще один вопрос. Чему будет равен результат вызова неисправленной функции SetBitN(0, 31)? Правильный ответ 0xffffffff80000000. Результатом выражения 1 << 31 является отрицательное число -2147483648. Это число представляется в 64-битной целой переменной как 0xffffffff80000000. Следует помнить и учитывать эффекты сдвига значений различных типов. Для лучшего понимания и наглядности изложенной информации в таблице N4 приведен ряд интересных выражений со сдвигами в 64-битной системе.
|
Выражение |
Результат (Dec) |
Результат (Hex) |
|---|---|---|
| ptrdiff_t Result; Result = 1 << 31; | -2147483648 | 0xffffffff80000000 |
| Result = ptrdiff_t(1) << 31; | 2147483648 | 0x0000000080000000 |
| Result = 1U << 31; | 2147483648 | 0x0000000080000000 |
| Result = 1 << 32; | 0 | 0x0000000000000000 |
| Result = ptrdiff_t(1) << 32; | 4294967296 | 0x0000000100000000 |
6. Упаковка указателей
Большое количество ошибок при мигрировании на 64-битные системы связано с изменением размера указателя по отношению к размеру обычных целых. В среде с моделью данных ILP32 обычные целые и указатели имеют одинаковый размер. К сожалению, 32-битный код повсеместно опирается на это предположение. Указатели часто приводятся к int, unsigned int и другим неподходящим типам для выполнения адресных расчетов.
Следует четко помнить, что для целочисленного представления указателей следует использовать только memsize типы. Предпочтение, на наш взгляд, следует отдавать типу uintptr_t, так как он лучше выражает намерения и делает код более переносимым, предохраняя его от изменений в будущем.
Рассмотрим два небольших примера.
1) char *p; p = (char *) ((int)p & PAGEOFFSET);
2) DWORD tmp = (DWORD)malloc(ArraySize); ... int *ptr = (int *)tmp;
Оба примера не учитывают, что размер указателя может отличаться от 32 бит. Используется явное приведение типа, отбрасывающее старшие биты в указателе, что является явной ошибкой на 64-битной системе. Исправленные варианты, использующие для упаковки указателей целочисленные memsize типы (intptr_t и DWORD_PTR), приведены ниже:
1) char *p; p = (char *) ((intptr_t)p & PAGEOFFSET);
2) DWORD_PTR tmp = (DWORD_PTR)malloc(ArraySize); ... int *ptr = (int *)tmp;
Опасность двух рассмотренных примеров в том, что сбой в программе может быть обнаружен спустя очень большой промежуток времени. Программа может совершенно корректно работать с небольшим объемом данных на 64-битной системе, пока обрабатываемые адреса находятся в пространстве первых четырех гигабайт памяти. А затем, при запуске программы на больших производственных задачах, произойдет выделение памяти за пределами этой области. Рассмотренный в примерах код, обрабатывая указатель на объект вне данной области, приведет к неопределенному поведению программы.
Следующий приведенный код не будет таиться и проявит себя при первом выполнении:
void GetBufferAddr(void **retPtr) {
...
// Access violation on 64-bit system
*retPtr = p;
}
unsigned bufAddress;
GetBufferAddr((void **)&bufAddress);
Исправление также заключается в выборе типа, способного вмещать в себя указатель.
uintptr_t bufAddress; GetBufferAddr((void **)&bufAddress); //OK
Бывают ситуации, когда упаковка указателя в 32-битный тип просто необходима. В основном такие ситуации возникают при необходимости работы со старыми API функциями. Для таких случаев следует прибегнуть к специальным функциям, таким как LongToIntPtr, PtrToUlong и так далее.
Резюмируя, хочется заметить, что плохим стилем будет упаковка указателя в типы, всегда равные 64-битам. Показанный ниже код вновь придется исправлять с приходом 128-битных систем:
PVOID p; // Bad style. The 128-bit time will come. __int64 n = __int64(p); p = PVOID(n);
7. Memsize-типы в объединениях
Особенностью объединения является то, что для всех элементов - членов объединения выделяется одна и та же область памяти, то есть они перекрываются. Хотя доступ к этой области памяти возможен с использованием любого из элементов, элемент для этой цели должен выбираться так, чтобы полученный результат не был бессмысленным.
Следует внимательно отнестись к объединениям, имеющим в своем составе указатели и другие члены типа memsize.
Когда возникает необходимость работать с указателем как с целым числом, иногда удобно воспользоваться объединением, как показано в примере, и работать с числовым представлением типа без использования явных приведений:
union PtrNumUnion {
char *m_p;
unsigned m_n;
} u;
u.m_p = str;
u.m_n += delta;
Данный код корректен на 32-битных системах и некорректен на 64-битных. Изменяя член m_n на 64-битной системе, мы работаем только с частью указателя m_p. Следует использовать тип, который будет соответствовать размеру указателя:
union PtrNumUnion {
char *m_p;
size_t m_n; //type fixed
} u;
Другое частое использование объединения заключается в представлении одного члена, набором других более мелких. Например, нам может потребоваться разбить значение типа size_t на байты для реализации табличного алгоритма подсчета количества нулевых битов в байте:
union SizetToBytesUnion {
size_t value;
struct {
unsigned char b0, b1, b2, b3;
} bytes;
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = TranslateTable[u.bytes.b0] +
TranslateTable[u.bytes.b1] +
TranslateTable[u.bytes.b2] +
TranslateTable[u.bytes.b3];
Здесь допущена принципиальная алгоритмическая ошибка, заключающаяся в предположении, что тип size_t состоит из 4 байт. Возможность автоматического поиска алгоритмических ошибок пока вряд ли возможна, но мы можем осуществить поиск всех объединений и проверить наличие в них memsize типов. Найдя такое объединение, мы можем обнаружить алгоритмическую ошибку и переписать код следующим образом.
union SizetToBytesUnion {
size_t value;
unsigned char bytes[sizeof(value)];
} u;
SizetToBytesUnion u;
u.value = value;
size_t zeroBitsN = 0;
for (size_t i = 0; i != sizeof(bytes); ++i)
zeroBitsN += TranslateTable[bytes[i]];
8. Изменение типа массива
Иногда в программах необходимо (или просто удобно) представлять элементы массива в виде элементов другого типа. Опасное и безопасное приведение типов представлено в следующем коде:
int array[4] = { 1, 2, 3, 4 };
enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };
//safe cast (for MSVC2005)
ENumbers *enumPtr = (ENumbers *)(array);
cout << enumPtr[1] << " ";
//unsafe cast
size_t *sizetPtr = (size_t *)(array);
cout << sizetPtr[1] << endl;
//Output on 32-bit system: 2 2
//Output on 64 bit system: 2 17179869187
Как видите, результат вывода программы отличается в 32-битном и 64-битном варианте. На 32-битной системе доступ к элементам массива осуществляется корректно, так как размеры типов size_t и int совпадают, и мы видим вывод "2 2".
На 64-битной системе мы получили в выводе "2 17179869187", так как именно значение 17179869187 находится в 1-ом элементе массива sizetPtr (см. рисунок 3). В некоторых случаях именно такое поведение и бывает нужно, но обычно это является ошибкой.

Рисунок 3. Расположение элементов массивов в памяти.
Исправление описанной ситуации заключается в отказе от опасных приведений типов путем модернизации программы. Другим вариантом является создание нового массива и копирование в него значений из исходного массива.
9. Виртуальные функции с аргументами типа memsize
Если у Вас в программе имеются большие иерархии наследования классов с виртуальными функциями, то существует вероятность использования по невнимательности аргументов различных типов, но которые фактически совпадают на 32-битной системе. Например, в базовом классе Вы используете в качестве аргумента виртуальной функции тип size_t, а в наследнике - тип unsigned. Соответственно, на 64-битной системе этот код будет некорректен.
Такая ошибка не обязательно кроется в сложных иерархиях наследования, и вот один из примеров:
сlass CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
class CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD dwData, UINT nCmd);
};
Проследим жизненный цикл разработки некоторого приложения. Пусть первоначально оно разрабатывалось под Microsoft Visual C++ 6.0., когда функция WinHelp в классе CWinApp имела следующий прототип:
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);
Совершенно верно было осуществить перекрытие виртуальной функции в классе CSampleApp, как показано в примере. Затем проект был перенесен в Microsoft Visual C++ 2005, где прототип функции в классе CWinApp претерпел изменения, заключающиеся в смене типа DWORD на тип DWORD_PTR. На 32-битной системе программа продолжит совершенно корректно работать, так как здесь типы DWORD и DWORD_PTR совпадают. Неприятности проявят себя при компиляции данного кода под 64-битную платформу. Получатся две функции с одинаковыми именами, но с различными параметрами, в результате чего перестанет вызываться пользовательский код.
Исправление заключается в использовании одинаковых типов в соответствующих виртуальных функциях.
сlass CSampleApp : public CWinApp {
...
virtual void WinHelp(DWORD_PTR dwData, UINT nCmd);
};
10. Сериализация и обмен данными
Важным элементом переноса программного решения на новую платформу является преемственность к существующим протоколам обмена данных. Необходимо обеспечить чтение существующих форматов проектов, осуществлять обмен данными между 32-битными и 64-битными процессами и так далее.
В основном, ошибки данного рода заключаются в сериализации memsize типов и операциях обмена данными с их использованием:
1) size_t PixelCount; fread(&PixelCount, sizeof(PixelCount), 1, inFile);
2) __int32 value_1; SSIZE_T value_2; inputStream >> value_1 >> value_2;
3) time_t time; PackToBuffer(MemoryBuf, &time, sizeof(time));
Во всех приведенных примерах имеются ошибки двух видов: использование типов непостоянной размерности в бинарных интерфейсах и игнорирование порядка байт.
Использование типов непостоянной размерности. Недопустимо использование типов, которые меняют свой размер в зависимости от среды разработки, в бинарных интерфейсах обмена данными. В языке Си++ все типы не имеют четкого размера и, следовательно, их все невозможно использовать для этих целей. Поэтому создатели средств разработки и сами программисты создают типы данных, имеющие строгий размер, такие как __int8, __int16, INT32, word64 и так далее.
Использование подобных типов обеспечивает переносимость данных между программами на различных платформах, хотя и требует дополнительных усилий. Три показанных примера написаны неаккуратно, что даст о себе знать при смене разрядности некоторых типов данных с 32-бит до 64-бит. Учитывая необходимость поддержки старых форматов данных, исправление может выглядеть следующим образом:
1) size_t PixelCount; __uint32 tmp; fread(&tmp, sizeof(tmp), 1, inFile); PixelCount = static_cast<size_t>(tmp);
2) __int32 value_1; __int32 value_2; inputStream >> value_1 >> value_2;
3) time_t time; __uint32 tmp = static_cast<__uint32>(time); PackToBuffer(MemoryBuf, &tmp, sizeof(tmp));
Но приведенный вариант исправления может являться не лучшим. При переходе на 64-битную систему программа может обрабатывать большее количество данных, и использование в данных 32-битных типов может стать существенным препятствием. В таком случае, можно оставить старый код для совместимости со старым форматом данных, исправив некорректные типы. И реализовать новый бинарный формат данных уже с учетом допущенных ошибок. Еще одним вариантом может стать отказ от бинарных форматов и переход на текстовый формат или другие форматы, предоставляемые различными библиотеками.
Игнорирование порядка байт (byte order). Даже после внесения исправлений, касающихся размеров типа, Вы можете столкнуться с несовместимостью бинарных форматов. Причина кроется в ином представлении данных. Наиболее часто это связано с другой последовательностью байт.
Порядок байт - метод записи байтов многобайтовых чисел (см. также рисунок 4). Порядок от младшего к старшему (англ. little-endian) - запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами. Порядок от старшего к младшему (англ. big-endian) - запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP. Поэтому, порядок байтов от старшего к младшему часто называют сетевым порядком байтов (англ. network byte order). Этот порядок байт используется процессорами Motorola 68000, SPARC.

Рисунок 4. Порядок байт в 64-битном типе на little-endian и big-endian системах.
Разрабатывая бинарный интерфейс или формат данных, следует помнить о последовательности байт. А если 64-битная система, на которую Вы переносите 32-битное приложение, имеет иную последовательность байт, то Вы просто будете вынуждены учесть это в своем коде. Для преобразования между сетевым порядком байт (big-endian) и порядком байт (little-endian), можно использовать функции htonl(), htons(), bswap_64, и так далее.
11. Битовые поля
Если Вы используете битовые поля, то необходимо учитывать, что использование memsize типов повлечет изменение размеров структур и выравнивания. Например, приведенная далее структура будет иметь размер 4 байта на 32-битной системе и 8 байт на 64-битной системе:
struct MyStruct {
size_t r : 5;
};
Но на этом ваша внимательность к битовым полям ограничиваться не должна. Рассмотрим тонкий пример:
struct BitFieldStruct {
unsigned short a:15;
unsigned short b:13;
};
BitFieldStruct obj;
obj.a = 0x4000;
size_t addr = obj.a << 17; //Sign Extension
printf("addr 0x%Ix\n", addr);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0xffffffff80000000
Обратите внимание, если приведенный пример скомпилировать для 64-битной системы, то в выражении "addr = obj.a << 17;" будет присутствовать знаковое расширение, несмотря на то, что обе переменные addr и obj.a являются беззнаковыми. Это знаковое расширение обусловлено правилами приведения типов, которые применяются следующим образом (см. также рисунок 5):
Член структуры obj.a преобразуется из битового поля типа unsigned short в int. Мы получаем тип int, а не unsigned int из-за того, что 15-битное поле помещается в 32-битное знаковое целое.
Выражение "obj.a << 17" имеет тип int, но оно преобразуется в ptrdiff_t и затем в size_t, перед тем как будет присвоено переменной addr. Знаковое расширение происходит в момент совершения преобразования из int в ptrdiff_t.
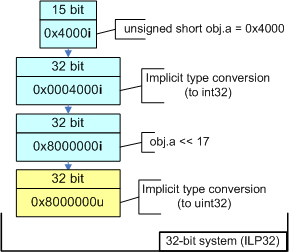

Рисунок 5. Вычисление выражения на различных системах.
Так что будьте внимательны при работе с битовыми полями. Для предотвращения описанной ситуации в нашем примере нам достаточно явно привести obj.a к типу size_t.
...
size_t addr = size_t(obj.a) << 17;
printf("addr 0x%Ix\n", addr);
//Output on 32-bit system: 0x80000000
//Output on 64-bit system: 0x80000000
12. Адресная арифметика с указателями
Пример первый:
unsigned short a16, b16, c16; char *pointer; : pointer += a16 * b16 * c16;
Данный пример корректно работает с указателями, если значение выражения "a16 * b16 * c16" не превышает UINT_MAX (4Gb). Такой код мог всегда корректно работать на 32-битной платформе, так как программа никогда не выделяла массивов больших размеров. На 64-битной архитектуре размер массива превысил UINT_MAX элементов. Допустим, мы хотим сдвинуть значение указателя на 6.000.000.000 байт, и поэтому переменные a16, b16 и c16 имеют значения 3000, 2000 и 1000 соответственно. При вычислении выражения "a16 * b16 * c16" все переменные, согласно правилам языка Си++, будут приведены к типу int, а уже затем будет произведено их умножение. В ходе выполнения умножения произойдет переполнение. Некорректный результат выражения будет расширен до типа ptrdiff_t и произойдет некорректное вычисление указателя.
Следует старательно избегать возможных переполнений в арифметике с указателями. Для этого лучше всего использовать memsize типы или явное приведение типов в выражениях, где присутствуют указатели. Используя явное приведение типов, мы можем переписать наш код следующим образом:
short a16, b16, c16;
char *pointer;
:
pointer += static_cast<ptrdiff_t>(a16) *
static_cast<ptrdiff_t>(b16) *
static_cast<ptrdiff_t>(c16);
Если Вы думаете, что злоключения ждут неаккуратные программы только на больших объемах данных, то мы вынуждены Вас огорчить. Рассмотрим интересный код для работы с массивом, содержащим всего 5 элементов. Второй пример работоспособен в 32-битном варианте и не работоспособен в 64-битном:
int A = -2;
unsigned B = 1;
int array[5] = { 1, 2, 3, 4, 5 };
int *ptr = array + 3;
ptr = ptr + (A + B); //Invalid pointer value on 64-bit platform
printf("%i\n", *ptr); //Access violation on 64-bit platform
Давайте проследим, как происходит вычисление выражения "ptr + (A + B)":
- Согласно правилам языка Си++ переменная A типа int приводится к типу unsigned.
- Происходит сложение A и B. В результате мы получаем значение 0xFFFFFFFF типа unsigned.
Затем происходит вычисление выражения "ptr + 0xFFFFFFFFu", но что из этого выйдет, будет зависеть от размера указателя на данной архитектуре. Если сложение будет происходить в 32-битной программе, то данное выражение будет эквивалентно "ptr - 1" и мы успешно распечатаем число 3.
В 64-битной программе к указателю честным образом прибавится значение 0xFFFFFFFFu, в результате чего указатель окажется далеко за пределами массива. И при доступе к элементу по данному указателю нас ждут неприятности.
Для предотвращения показанной ситуации, как и в первом случае, рекомендуем использовать в арифметике с указателями только memsize-типы. Два варианта исправления кода:
ptr = ptr + (ptrdiff_t(A) + ptrdiff_t(B));
ptrdiff_t A = -2; size_t B = 1; ... ptr = ptr + (A + B);
Вы можете возразить и предложить следующий вариант исправления:
int A = -2; int B = 1; ... ptr = ptr + (A + B);
Да, такой код будет работать, но он плох по ряду причин:
- Он будет приучать к неаккуратной работе с указателями. Через некоторое время Вы можете забыть нюансы и по ошибке вновь сделать одну из переменных типа unsigned.
- Использование не memsize-типов совместно с указателями потенциально опасно. Допустим, что в выражении с указателем участвует переменная Delta типа int. И это выражение совершенно корректно. Но ошибка может укрыться в вычислении самой переменной Delta, так как 32-бит может не хватить для необходимых вычислений, при работе с большими массивами данных. Использование memsize-типа для переменной Delta автоматически устраняет такую опасность.
13. Индексация массивов
Данная разновидность ошибок выделена для лучшей структуризации изложения, так как индексация в массивах с использованием квадратных скобок - это всего лишь иная запись адресной арифметики, рассмотренной выше.
В программировании на языке Си, а затем и Си++ сложилась практика использования в конструкциях следующего вида переменные типа int/unsigned:
unsigned Index = 0; while (MyBigNumberField[Index] != id) Index++;
Но время идет, и все меняется. И вот теперь пришло время сказать: "Больше так не делайте! Используйте для индексации (больших) массивов только memsize-типы."
Приведенный код не сможет обработать в 64-битной программе массив, содержащий более UINT_MAX элементов. После доступа к элементу с индексом UINT_MAX произойдет переполнение переменной Index и мы получим вечный цикл.
Чтобы окончательно убедить Вас в необходимости использования только memsize типов для индексации и в выражениях адресной арифметики, приведем последний пример.
class Region {
float *array;
int Width, Height, Depth;
float Region::GetCell(int x, int y, int z) const;
...
};
float Region::GetCell(int x, int y, int z) const {
return array[x + y * Width + z * Width * Height];
}
Данный код взят из реальной программы математического моделирования, в которой важным ресурсом является объем оперативной памяти, и возможность на 64-битной архитектуре использовать более 4 гигабайт памяти существенно увеличивает вычислительные возможности. В программах данного класса для экономии памяти часто используют одномерные массивы, осуществляя работу с ними как с трехмерными массивами. Для этого существуют функции, аналогичные GetCell, обеспечивающие доступ к необходимым элементам. Но приведенный код будет корректно работать только с массивами, содержащими менее INT_MAX элементов. Причина - использование 32-битных типов int для вычисления индекса элемента.
Программисты часто допускают ошибку, пытаясь исправить код следующим образом:
float Region::GetCell(int x, int y, int z) const {
return array[static_cast<ptrdiff_t>(x) + y * Width +
z * Width * Height];
}
Они знают, что по правилам языка Си++ выражение для вычисления индекса будет иметь тип ptrdiff_t и надеются за счет этого избежать переполнения. Но переполнение может произойти внутри подвыражения "y * Width" или "z * Width * Height", так как для их вычисления по-прежнему используется тип int.
Если Вы хотите исправить код, не изменяя типов переменных, участвующих в выражении, то Вы можете явно привести каждую переменную к memsize типу:
float Region::GetCell(int x, int y, int z) const {
return array[ptrdiff_t(x) +
ptrdiff_t(y) * ptrdiff_t(Width) +
ptrdiff_t(z) * ptrdiff_t(Width) *
ptrdiff_t(Height)];
}
Другое решение - изменить типы переменных на memsize тип:
typedef ptrdiff_t TCoord;
class Region {
float *array;
TCoord Width, Height, Depth;
float Region::GetCell(TCoord x, TCoord y, TCoord z) const;
...
};
float Region::GetCell(TCoord x, TCoord y, TCoord z) const {
return array[x + y * Width + z * Width * Height];
}
14. Смешанное использование простых целочисленных типов и memsize-типов
Смешанное использование memsize- и не memsize-типов в выражениях может приводить к некорректным результатам на 64-битных системах и быть связано с изменением диапазона входных значений. Рассмотрим ряд примеров:
size_t Count = BigValue;
for (unsigned Index = 0; Index != Count; ++Index)
{ ... }
Это пример вечного цикла, если Count > UINT_MAX. Предположим, что на 32-битных системах этот код работал с диапазоном менее UINT_MAX итераций. Но 64-битный вариант программы может обрабатывать больше данных и ему может потребоваться большее количество итераций. Поскольку значения переменной Index лежат в диапазоне [0..UINT_MAX], то условие "Index != Count" никогда не выполнится, что и приводит к бесконечному циклу.
Другая частая ошибка - запись выражений следующего вида:
int x, y, z; intptr_t SizeValue = x * y * z;
Ранее уже рассматривались подобные примеры, когда при вычислении значений с использованием не memsize-типов происходило арифметическое переполнение. И конечный результат был некорректен. Поиск и исправление приведенного кода осложняется тем, что компиляторы, как правило, не выдают на него никаких предупреждений. С точки зрения языка Си++ это совершенно корректная конструкция. Происходит умножение нескольких переменных типа int, после чего результат неявно расширяется до типа intptr_t и происходит присваивание.
Приведем небольшой код, показывающий опасность неаккуратных выражений со смешанными типами (результаты получены с использованием Microsoft Visual C++ 2005, 64-битный режим компиляции):
int x = 100000; int y = 100000; int z = 100000; intptr_t size = 1; // Result: intptr_t v1 = x * y * z; // -1530494976 intptr_t v2 = intptr_t(x) * y * z; // 1000000000000000 intptr_t v3 = x * y * intptr_t(z); // 141006540800000 intptr_t v4 = size * x * y * z; // 1000000000000000 intptr_t v5 = x * y * z * size; // -1530494976 intptr_t v6 = size * (x * y * z); // -1530494976 intptr_t v7 = size * (x * y) * z; // 141006540800000 intptr_t v8 = ((size * x) * y) * z; // 1000000000000000 intptr_t v9 = size * (x * (y * z)); // -1530494976
Необходимо, чтобы все операнды в подобных выражениях были заранее приведены к типу большей разрядности. Помните, что выражение вида
intptr_t v2 = intptr_t(x) * y * z;
вовсе не гарантирует правильный результат. Оно гарантирует только то, что выражение "intptr_t(x) * y * z" будет иметь тип intptr_t. Правильный результат, показанный этим выражением в примере, не более чем везение, обусловленное конкретной версией компилятора и фазой Луны.
Порядок вычисления выражения с операторами одинакового приоритета не определен. Точнее, компилятор волен вычислять подвыражения в том порядке, который он считает более эффективным, даже если подвыражения вызывают побочные эффекты. Порядок возникновения побочных эффектов не определен. Выражения, включающие в себя коммутативные и ассоциативные операции (*, +, &, /, ^), могут быть реорганизованы произвольным образом, даже при наличии скобок. Для задания определенного порядка вычисления выражения необходимо использовать явную временную переменную.
Следовательно, если результатом выражения должен являться memsize-тип, то в выражении должны участвовать только memsize-типы. Или элементы, приведенные к memsize-типам. Правильный вариант:
intptr_t v2 = intptr_t(x) * intptr_t(y) * intptr_t(z); // OK!
ПРИМЕЧАНИЕ
Примечание. Если у Вас много целочисленных вычислений и контроль над переполнениями для Вас является важной задачей, то мы предлагаем обратить Ваше внимание на класс SafeInt, реализацию и описание которого можно найти в MSDN.
Смешанное использование типов может проявляться и в изменении программной логики:
ptrdiff_t val_1 = -1;
unsigned int val_2 = 1;
if (val_1 > val_2)
printf ("val_1 is greater than val_2\n");
else
printf ("val_1 is not greater than val_2\n");
//Output on 32-bit system: "val_1 is greater than val_2"
//Output on 64-bit system: "val_1 is not greater than val_2"
На 32-битной системе переменная val_1 согласно правилам языка Си++ расширялась до типа unsigned int и становилась значением 0xFFFFFFFFu. В результате условие "0xFFFFFFFFu > 1" выполнялось. На 64-битной системе наоборот расширяется переменная val_2 до типа ptrdiff_t. В этом случае уже проверяется выражение "-1 > 1". На рисунке 6 схематично отображены происходящие преобразования.
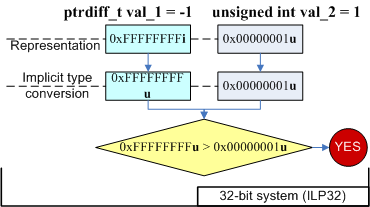
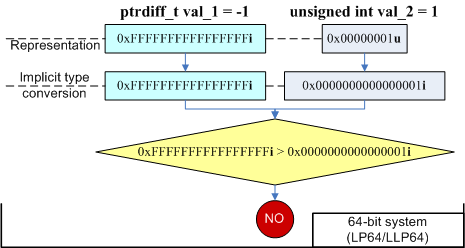
Рисунок 6. Преобразования, происходящие в выражении.
Если Вам необходимо вернуть прежнее поведение кода - следует изменить тип переменной val_2:
ptrdiff_t val_1 = -1;
size_t val_2 = 1;
if (val_1 > val_2)
printf ("val_1 is greater than val_2\n");
else
printf ("val_1 is not greater than val_2\n");
15. Неявные приведения типов при использовании функций
Рассматривая предыдущий класс ошибок, связанный со смешиванием простых целочисленных типов и memsize-типов, мы рассматривали только простые выражения. Но аналогичные проблемы могут проявиться и при использовании других конструкций языка Си++:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return x + y * Width + z * Width * Height;
}
...
MyArray[GetIndex(x, y, z)] = 0.0f;
В случае работы с большими массивами (более INT_MAX элементов) данный код будет вести себя некорректно, и мы будем адресоваться не к тем элементам массива MyArray, к которым рассчитываем. Несмотря на то, что мы возвращаем значение типа size_t, выражение "x + y * Width + z * Width * Height" вычисляется с использованием типа int. Мы думаем, Вы уже догадались, что исправленный код будет выглядеть следующим образом:
extern int Width, Height, Depth;
size_t GetIndex(int x, int y, int z) {
return (size_t)(x) +
(size_t)(y) * (size_t)(Width) +
(size_t)(z) * (size_t)(Width) * (size_t)(Height);
}
В следующем примере, у нас вновь смешивается memsize-тип (указатель) и простой тип unsigned:
extern char *begin, *end;
unsigned GetSize() {
return end - begin;
}
Результат выражения "end - begin" имеет тип ptrdiff_t. Поскольку функция возвращает тип unsigned, то происходит неявное приведение типа, при котором старшие биты результата теряются. Таким образом, если указатели begin и end ссылаются на начало и конец массива, по размеру большего UINT_MAX (4Gb), то функция вернет некорректное значение.
И еще один пример. На этот раз рассмотрим не возвращаемое значение, а формальный аргумент функции:
void foo(ptrdiff_t delta); int i = -2; unsigned k = 1; foo(i + k);
Этот код не напоминает Вам пример с некорректной арифметикой указателей, рассмотренный ранее? Да, здесь происходит то же самое. Некорректный результат возникает при неявном расширении фактического аргумента, имеющего значение 0xFFFFFFFF и тип unsigned, до типа ptrdiff_t.
16. Перегруженные функции
При переносе 32-битных программ на 64-битную платформу может наблюдаться изменение логики ее работы, связанное с использованием перегруженных функций. Если функция перекрыта для 32-битных и 64-битных значений, то обращение к ней с аргументом типа memsize будет транслироваться в различные вызовы на различных системах. Этот прием может быть полезен, как, например, в приведенном коде:
static size_t GetBitCount(const unsigned __int32 &) {
return 32;
}
static size_t GetBitCount(const unsigned __int64 &) {
return 64;
}
size_t a;
size_t bitCount = GetBitCount(a);
Но такое изменение логики хранит в себе опасность. Представьте себе программу, где для каких-то целей используется класс для организации стека. Особенность этого класса в том, что он позволяет хранить значение различных типов:
class MyStack {
...
public:
void Push(__int32 &);
void Push(__int64 &);
void Pop(__int32 &);
void Pop(__int64 &);
} stack;
ptrdiff_t value_1;
stack.Push(value_1);
...
int value_2;
stack.Pop(value_2);
Неаккуратный программист помещал и затем выбирал из стека значения различных типов (ptrdiff_t и int). На 32-битной системе их размеры совпадали, все замечательно работало. Когда в 64-битной программе изменился размер типа ptrdiff_t, то в стек стало попадать больше байт, чем затем извлекаться.
Думаем, что Вам понятен данный класс ошибок, и как внимательно следует относиться к вызову перегруженных функций, передавая фактические аргументы типа memsize.
17. Выравнивание данных
Процессоры работают эффективнее, когда имеют дело с правильно выровненными данными. Как правило, 32-битный элемент данных должен быть выровнен по границе, кратной 4 байт, а 64-битный элемент - по границе 8 байт. Попытка работать с не выровненными данными на процессорах IA-64 (Itanium), как показано в следующем примере, приведет к возникновению исключения:
#pragma pack (1) // Also set by key /Zp in MSVC
struct AlignSample {
unsigned size;
void *pointer;
} object;
void foo(void *p) {
object.pointer = p; // Alignment fault
}
Если Вы вынуждены работать с не выровненными данными на Itanium, то следует явно указать это компилятору. Например, воспользоваться специальным макросом UNALIGNED:
#pragma pack (1) // Also set by key /Zp in MSVC
struct AlignSample {
unsigned size;
void *pointer;
} object;
void foo(void *p) {
*(UNALIGNED void *)&object.pointer = p; //Very slow
}
Такое решение неэффективно, так как доступ к не выровненным данным будет происходить в несколько раз медленнее. Лучшего результата можно достичь, располагая в 64-битные элементы данных до 32,16 и 8-битных элементов.
На архитектуре x64, при обращении к не выровненным данным, исключения не возникает, но их также следует избегать. Во-первых, из-за существенного замедления скорости доступа к таким данным, а во-вторых, из-за высокой вероятности переноса программы в будущем на платформу IA-64.
Рассмотрим еще один пример кода, не учитывающий выравнивание данных:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( sizeof(DWORD) + 5 * sizeof(PVOID) );
...
Если мы хотим выделить объем памяти, необходимый для хранения объекта типа MyPointersArray, содержащего 5 указателей, то мы должны учесть, что начало массива m_arr будет выровнено по границе 8 байт. Расположение данных в памяти на разных системах (Win32/Win64) показано на рисунке 7.
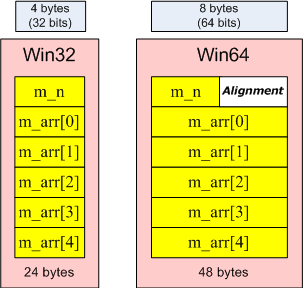
Рисунок 7. Выравнивание данных в памяти на системах Win32 и Win64
Корректный расчет размера должен выглядеть следующим образом:
struct MyPointersArray {
DWORD m_n;
PVOID m_arr[1];
} object;
...
malloc( FIELD_OFFSET(struct MyPointersArray, m_arr) +
5 * sizeof(PVOID) );
...
В приведенном коде мы узнаем смещение последнего члена структуры и суммируем это смещение с его размером. Смещение члена структуры или класса можно узнать с использованием макроса offsetof или FIELD_OFFSET.
Всегда используйте эти макросы для получения смещения в структуре, не опираясь на Ваше знание размеров типов и выравнивания. Пример кода с правильным вычислением адреса члена структуры:
struct TFoo {
DWORD_PTR whatever;
int value;
} object;
int *valuePtr =
(int *)((size_t)(&object) + offsetof(TFoo, value)); // OK
18. Исключения.
Генерирование и обработка исключений с участием целочисленных типов не является хорошей практикой программирования на языке Си++. Для этих целей следует использовать более информативные типы, например классы, производные от классов std::exception. Но иногда все-таки приходится работать с менее качественным кодом, таким как показано ниже:
char *ptr1;
char *ptr2;
try {
try {
throw ptr2 - ptr1;
}
catch (int) {
std::cout << "catch 1: on x86" << std::endl;
}
}
catch (ptrdiff_t) {
std::cout << "catch 2: on x64" << std::endl;
}
Следует тщательно избегать генерирования или обработку исключений с использованием memsize-типов, так как это чревато изменением логики работы программы. Исправление данного кода может заключаться в замене "catch (int)" на "catch (ptrdiff_t)". А более правильным решением будет использование специального класса для передачи информации о возникшей ошибке.
19. Использование устаревших функций и предопределенных констант.
Разрабатывая 64-битное приложение, помните об изменениях среды, в которой оно теперь будет выполняться. Часть функций станут устаревшими, их будет необходимо изменить на обновленные варианты. Примером такой функции в ОС Windows будет GetWindowLong. Обратите внимание на константы, относящиеся к взаимодействию со средой, в которой выполняется программа. В Windows подозрительными будут являться строки, содержащие "system32" или "Program Files".
20. Явные приведения типов
Будьте аккуратны с явными приведениями типов. Они могут изменить логику выполнения программы при изменении разрядности типов или спровоцировать потерю значащих битов. Привести типовые примеры ошибок, связанных с явным приведением типов сложно, так как они очень разнообразны и специфичны для разных программ. С некоторыми из ошибками, связанными с явным приведением типов, Вы уже познакомились ранее.
Диагностика ошибок
Диагностика ошибок, возникающих при переносе 32-битных программ на 64-битные системы, является непростой задачей. Перенос недостаточно качественного кода, разработанного без учета особенностей других архитектур, может потребовать много времени и усилий. Поэтому уделим немного внимания описанию методик и средств, которые смогут упростить эту задачу.
Юнит-тестирование
Юнит-тестирование давно завоевало заслуженное уважение среди программистов. Юнит-тесты помогут проверить корректность программы после переноса на новую платформу. Но тут есть одна тонкость, о которой Вы должны помнить.
Юнит-тестирование может не позволить Вам проверить новые диапазоны входных значений, которые становятся доступны на 64-битных системах. Юнит-тесты классически разрабатываются таким образом, чтобы по возможности проходить за минимальное время. И та функция, которая обычно работает с массивом размером в десятки мегабайт, в юнит-тестах, скорее всего, будет обрабатывать десятки килобайт. Это обоснованно, так как эта функция в тестах может вызваться много раз с различными наборами входных значений. Но вот перед нами 64-битный вариант программы. И рассматриваемая функция теперь обрабатывает уже более 4 гигабайт данных. Соответственно, возникает необходимость увеличения входного размера массива и в тестах до размеров более 4 гигабайт. Проблема в том, что время прохождения тестов в таком случае увеличится на несколько порядков.
Поэтому, модифицируя наборы тестов, помните о компромиссе между скоростью выполнения юнитестов и полнотой проверок. К счастью, убедиться в работоспособности Ваших приложений могут помочь другие методики.
Просмотр кода
Просмотр кода - самая лучшая методика поиска ошибок и улучшения кода. Совместный тщательный просмотр кода может полностью избавить программу от ошибок, связанных с особенностями разработки 64-битных приложений. Естественно, вначале следует узнать, какие именно ошибки следует искать, иначе просмотр может не дать положительных результатов. Для этого необходимо заранее ознакомиться с этой и другими статьями, посвященными переносу программ с 32-битных систем на 64-битные. Ряд интересных ссылок по данной тематике Вы можете найти в конце статьи.
Но у этого подхода к анализу исходного кода есть один существенный недостаток. Он требует очень большого количества времени, из-за чего практически неприменим на больших проектах.
Компромиссом является использование статических анализаторов. Статический анализатор можно рассматривать как автоматизированную систему просмотра кода, где для программиста создается выборка потенциально опасных мест для проведения им дальнейшего анализа.
Но в любом случае желательно провести несколько просмотров кода, с целью совместного обучения команды поиску новых разновидностей ошибок, проявляющих себя на 64-битных системах.
Встроенные средства компиляторов
Часть задач с поиском дефектного кода позволяют решать компиляторы. В них часто бывают встроены различные механизмы для диагностики рассматриваемых нами ошибок. Например, в Microsoft Visual C++ 2005 Вам могут быть полезны следующие ключи: /Wp64, /Wall, а в SunStudio C++ ключ -xport64.
К сожалению, предоставляемые ими возможности часто недостаточны и не стоит полагаться только на них. Но в любом случае крайне рекомендуется включить соответствующие опции компилятора для диагностики ошибок в 64-битном коде.
Статические анализаторы
Статические анализаторы - прекрасное средство повышения качества и надежности программного кода. Основная сложность, связанная с использованием статических анализаторов заключается в том, что они генерируют довольно много ложных сообщений о потенциальных ошибках. Программисты, будучи по натуре ленивыми, используют этот аргумент, чтобы так или иначе не заниматься исправлением найденных ошибок. В Microsoft эта проблема решается безусловным внесением обнаруженных ошибок в bug tracking систему. Тем самым у программиста не остается выбора между исправлением кода и попытками избежать этого.
Мы считаем, что такие жесткие правила оправданы. Выигрыш от качественного кода существенно покрывает издержки времени на статический анализ и соответствующую модификацию кода. Выигрыш достигается за счет облегчения поддержки кода и уменьшения сроков отладки и тестирования.
Статические анализаторы могут с успехом использоваться для диагностики многих из рассмотренных в статье классов ошибок.
Авторам известны 3 статических анализатора, которые заявляют о наличии средств диагностирования ошибок, связанных с переносом программ на 64-битные системы. Хотим сразу предупредить, что мы можем заблуждаться по поводу возможностей, которыми они обладают, тем более что это развивающиеся продукты и новые версии могут иметь большую функциональность.
- Gimpel Software PC-Lint (http://www.gimpel.com). Данный анализатор обладает широким списком поддерживаемых платформ и является статическим анализатором общего назначения. Он позволяет выявлять ошибки при переносе программ на архитектуру с моделью данных LP64. Преимуществом является возможность построения жесткого контроля над преобразованиями типов. К недостаткам можно отнести отсутствие среды, но это можно исправить, используя стороннюю оболочку Riverblade Visual Lint.
- Parasoft C++test (http://www.parasoft.com/). Другой известный статический анализатор общего назначения. Также существует под большое количество аппаратных и программных платформ. Имеет встроенную среду, существенно облегчающую работу и настройку правил анализа. Как и PC-Lint он рассчитан на модель данных LP64.
- Viva64 (http://www.viva64.com). В отличие от других анализаторов рассчитан на модель данных Windows (LLP64). Интегрируется в среду разработки Visual Studio 2005. Предназначен только для диагностики проблем, связанных с переносом программ на 64-битные системы, что существенно упрощает его настройку.
Заключение
Если Вы добрались до этого места в тексте, мы рады Вашему интересу. Надеемся, что статья принесла Вам пользу и поможет облегчить разработку и отладку 64-битных приложений. Мы будем рады получить ваши отзывы, замечания, поправки, дополнения и непременно внести их в следующую версию статьи. Чем больше мы будем описывать типовые ошибки, тем с большей пользой сможем использовать опыт друг друга и получать помощь.
Ресурсы
- Chandra Shekar. Extend your application's reach from 32-bit to 64-bit environments. http://enterprisenetworksandservers.com/monthly/art.php?2670
- Converting 32-bit Applications Into 64-bit Applications: Things to Consider. http://developers.sun.com/sunstudio/articles/ILP32toLP64Issues.html
- Andrew Josey. Data Size Neutrality and 64-bit Support. http://www.unix.org/whitepapers/64bit.html
- Harsha S. Adiga. Porting Linux applications to 64-bit systems. http://www.ibm.com/developerworks/library/l-port64.html
- Transitioning C and C++ programs to the 64-bit data model. http://devresource.hp.com/drc/STK/docs/refs/64datamodel.jsp
- Porting an Application to 64-bit Linux on HP Integrity Servers. http://h21007.www2.hp.com/dspp/files/unprotected/32bitto64bit_whitepaper.pdf
- Stan Murawski. Beyond Windows XP: Get Ready Now for the Upcoming 64-Bit Version of Windows. http://msdn.microsoft.com/msdnmag/issues/01/11/XP64/
- Steve Graegert. 64-bit Data Models Explained. http://digitalether.de/index.php?option=com_content&task=view&id=31&Itemid=46
- Обновляемый список ресурсов, посвященных разработке 64-битных приложений. http://www.viva64.com/links.php