| КНИГА |
06.06.02
|
Консалтинг
при автоматизации предприятий:
подходы, методы, средства
Г.Н.
Калянов,
Краткие сведения об авторе
14.6. Организация и поддержуа репозитария
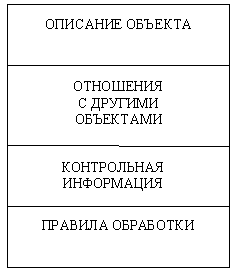
Основные функции средств организации и поддержки репозитария - хранение, доступ, обновление, анализ и визуализация всей информации по проекту ПО. Содержимое репозитария включает не только информационные объекты различных типов, но и отношения между их компонентами, а также правила использования или обработки этих компонент (рис. 14.3). Репозитарий может хранить свыше 100 типов объектов, примерами которых являются структурные диаграммы, определения экранов и меню, проекты отчетов, описания данных, логика обработки, модели данных, модели организации, модели обработки, исходные коды, элементы данных и т.п.
Рис. 14.3. Содержимое репозитария
Каждый информационный объект в репозитарии описывается перечислением его свойств: идентификатор, имена-синонимы, тип, текстовое описание, компоненты, файл-хранилище, область значений. Кроме этого, хранятся все отношения с другими объектами (например, все объекты, в которых данный объект используется; все перекрестные ссылки), правила формирования и редактирования объекта, а также контрольная информация о времени порождения объекта, времени его последнего обновления, кем и в каком проекте он был порожден, номере версии, возможности обновления и т.п.На основе репозитария осуществляется интеграция CASE-средств и разделение системной информации между разработчиками. При этом возможности репозитария обеспечивают несколько уровней интеграции: общий пользовательский интерфейс по всем средствам, передачу данных между средствами, интеграцию этапов разработки через единую систему представлений фаз ЖЦ, передачу данных и средств между аппаратурными платформами.
Репозитарий является базой для стандартизации документации по проекту и контроля состоятельности проектных спецификаций. Все отчеты строятся автоматически по репозитарию, ниже перечислены основные их типы:
Пример отчета по функциональным блокам SADT-модели управления банком, автоматически создаваемого пакетом Design/IDEF, приведен ниже.
Activity Report
[A0] Банк
Inputs: Платежные документы
Outputs: Деньги
Controls: Законы, Время,
Баланс
Mechanisms: Техника,
Сотрудники
Sub-Activities: [A1]
Операционные залы,
[A2] Управление банком,
[A3] Центральный банк
[A1] Операционные
залы
Inputs: Платежные документы
Outputs: Принятые платежные
документы
Controls: Законы,
Продолжит. раб. дня, Остатки счетов клиентов
Mechanisms: Сотрудники,
Терминал БД
[A2] Управление
банком
Inputs: Принятые платежные документы
Outputs: (Unlabled), Деньги, (Unlabled)
Controls: Спец.
законы, Расчет баланса, Срок обработки
Mechanisms: Управленческий
персонал, Компьютеры
[A3] Центральный
банк
Inputs: (Unlabled)
Outputs: Деньги, (Unlabled)
Controls: Срок отправки
Mechanisms: Экспедиторы, Автомашины
Важные функции управления и контроля проекта также реализуются на основе репозитария. В частности через репозитарий может осуществляться контроль безопасности (ограничения доступа, привелегии доступа), контроль версий, контроль изменений и др.
14.7. Поддержка процесса проектирования и разработки
При поддержке процесса проектирования и разработки основную роль играют следующие возможности CASE-пакетов: покрытие ЖЦ, поддержка прототипирования, поддержка структурных методологий, автоматическая кодогенерация.
При покрытии ЖЦ наибольшее внимание уделяется его наиболее критичным этапам - анализу требований и проектированию спецификаций. Последние являются основой всего проекта, поэтому их полнота и корректность влияют на успех разработки в целом.
Важную роль при автоматизации ранних этапов ЖЦ играют возможности поддержки прототипирования. Соответствующие средства используются для определения системных требований и ответа на вопросы об ожидаемом поведении системы. Такие средства как генераторы меню, экранов и отчетов позволяют быстро построить прототипы пользовательских интерфейсов и снабдить моделью функционирования системы с позиций конечного пользователя. Использование языков четвертого поколения (4GL) позволяет строить более сложные модели, при этом прототип позволяет промоделировать основные функции системы, но не способен контролировать ее ожидаемое поведение. Исполняемые языки спецификаций преобразуют процесс разработки в следующий итеративный процесс: спецификации определяются и выполняются, затем производится переопределение или корректировка. Созданные таким образом прототипы позволяют определять, является ли проектируемая система полной и корректной.
Поддержка структурных методологий осуществляется за счет средств их автоматизации на следующих двух уровнях:
Кодогенерация осуществляется на основе репозитария и позволяет автоматически построить до 80-90% объектных кодов или текстов программ на языках высокого уровня. При этом различными CASE-пакетами поддерживаются практически все известные языки программирования, однако наиболее часто в качестве целевых языков выступают COBOL, C и ADA. Средства кодогенерации по отношению к полноте целевого продукта разделяются на средства генерации каркаса ПО и средства генерации полного продукта. В первом случае автоматически строится откомментированная логика (потоки управления) ПО, а также коды для БД, файлов, экранов, отчетов и т.п., остальные фрагменты ПО кодируются вручную. Во втором случае из проектных спецификаций генерируется полная документированная программа, включая выполняемый код, пользовательскую и программную документацию, наборы тестов и т.д. Все эти компоненты полной программы связываются в единый объект, хранящийся в репозитарии для облегчения доступа и сопровождения.
Идея автоматической кодогенерации на основе модели заключается в следующем. Любая программа схематически может быть представлена в виде тройки: обрабатываемые данные, логический каркас обработки, линейные участки обработки. Схема базы данных может быть легко сгенерована на основании модели “сущность-связь”, и современные средства информационного моделирования (например, ERWin, Designer/2000 и др.) обеспечивают такую генерацию. Логика обработки генерируется на основе диаграмм потоков данных: известны алгоритмы автоматического преобразования иерархии DFD в структурные карты, а с задачей получения из структурных карт соответствующих кодов легко справляется теория компиляции. Наконец, линейным участкам соответствуют миниспецификации модели. И именно здесь лежит ключ к высокому проценту автоматически сгенерированного кода, существенно зависящему от метода задания миниспецификаций.
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Отправить ссылку на страницу по e-mail
Interface Ltd.Отправить E-Mail http://www.interface.ru |
|
| Ваши замечания и предложения отправляйте
автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 06.06.02 |