| СТАТЬЯ |
26.12.00
|
Часть 1. Общие вопросы организации распределенных вычислений
преподаватель УКЦ Interface Ltd.
© Copyright N.Elmanova & ComputerPress Magazine.
Журнал “ Компьютер Пресс - CD ” #01/1999
Данный цикл статей посвящен организации распределенной обработки данных в информационных системах. В нем будут рассмотрены преимущества такой обработки по сравнению с традиционными способами построения информационных систем, типы используемых для этой цели сервисов, стандарты и спецификации, используемые при их создании, а также некоторые программные средства для их реализации. В данном цикле будут также рассмотрены некоторые примеры реализации таких сервисов, созданные главным образом с помощью средств разработки и технологий Inprise Corporation (Borland).
Из чего состоит информационная система
Информационные службы компаний и предприятий (как крупных, так и небольших) обычно предоставляют (или должны предоставлять в идеале) набор сервисов, доступных с рабочих мест сотрудников этого предприятия. В общем случае понятие сервиса отнюдь не ограничивается информационной системой компании, предоставляющей сотрудникам доступ к корпоративным данным. Сервисом может быть и доступ к тем или иным файлам, хранящимся в локальной сети, и работа с электронной почтой, и доступ в Internet, и использование сетевого принтера или модема, и проведение каких-либо расчетов. Доступность того или иного сервиса в сети нередко определяется тем, какие стандарты он поддерживает (имеются в виду стандартные программные интерфейсы и стандартные протоколы обмена данными).
Если рассматривать многопользовательскую работу с корпоративными данными в сети, основанную на применении какой-либо СУБД (в данном случае неважно, сетевой или серверной), можно заметить, что она подчиняется некоторым общим правилам и состоит, как правило, из стандартного набора программных компонентов и сервисов.
Наиболее важным из таких компонентов является собственно база данных, то есть набор файлов, содержащих данные компании. Этот набор файлов может обслуживаться сервисом, называемым сервером баз данных, если СУБД серверная, или файловыми сервисами операционной системы того компьютера, на котором эти файлы расположены, если СУБД не является серверной.
Следующим важным компонентом такой системы является набор пользовательских приложений, используемых для редактирования и просмотра данных на рабочих станциях сотрудников. В этом случае говорят, что такие приложения содержат презентационную логику информационной системы. Нередко пользовательские приложения используются для проведения других операций с данными (проверка допустимости данных, статистическая обработка, генерация отчетов и др.). В этом случае говорят о том, что такое приложение содержит алгоритмы прикладной обработки данных.
Еще один компонент, без которого работа сетевой информационной системы невозможна - это средства обеспечения доступности данных из СУБД в пользовательском приложении. Набор этих средств существенно зависит от того, является ли СУБД серверной. Как минимум, во всех случаях он включает средства сетевого доступа, базирующиеся на сетевых средствах операционных систем, используемых для эксплуатации СУБД и пользовательских приложений. Сетевые средства операционных систем включают, как минимум, поддержку сетевых протоколов, обеспечивающих этот доступ.
В случае серверных СУБД к этому набору добавляются средства взаимодействия пользовательского приложения и сервера баз данных, использующие ту же самую поддержку сетевых протоколов операционными системами. Эти средства обычно включают клиентскую часть серверной СУБД, содержащую, как правило, низкоуровневое API (Application Program Interface - прикладной программный интерфейс) взаимодействия с сервером баз данных. Помимо этого, средства обеспечения доступности данных нередко содержат библиотеки, содержащие высокоуровневые функции доступа к данным. Эти функции упрощают использование клиентской части, если СУБД серверная, либо реализуют стандартные операции с данными, если СУБД не является серверной. В случае пользовательских приложений, созданных с помощью средств разработки Inprise, это библиотека Borland Database Engine (BDE) и драйверы SQL Links, в случае использования средств разработки Microsoft и многих других производителей (а иногда и средств разработки Inprise) - ODBC-драйверы.
Типичные проблемы эксплуатации информационных систем и способы их решения
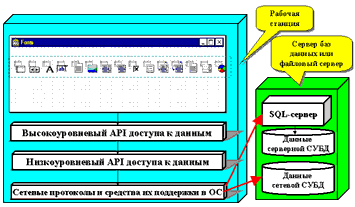
Классические многопользовательские системы, как правило, содержат последние два компонента информационной системы на рабочих станциях пользователей. Из этого следует, что подобные рабочие станции должны предоставлять для самих себя весь требующийся для этого набор сервисов и содержать соответствующее программное обеспечение для их функционирования. Подобное требование нередко усложняет технические требования, предъявляемые к аппаратной части клиентской рабочей станции, и в конечном итоге приводит к удорожанию всей системы в целом (рис. 1)
Рис. 1. Классическая информационная система
Следует также отметить, что подобное программное обеспечение требует обычно проведения работ по его настройке и поддержанию этих настроек в рабочем состоянии. Так, пользовательское приложение должно, как минимум, "знать" о том, где расположены используемые им данные, какого они типа (имеется в виду тип серверной СУБД либо формат данных сетевой СУБД), с помощью какого сетевого протокола они доступны, каков поддерживаемый базой данных язык, определяющий порядок алфавитной сортировки и индексирования данных. Подобная работа нередко является весьма трудоемким процессом, особенно при большом количестве и неоднородном парке рабочих станций. Отметим, что далеко не все компоненты подобного программного обеспечения могут быть включены в состав дистрибутива пользовательского приложения, так как многие из них являются предметом лицензирования и продажи.
Есть и еще один немаловажный фактор: чем сложнее конфигурация, обеспечивающая доступ к данным рабочей станции, тем чаще происходят нарушения в ее работе. По данным некоторых западных источников, переконфигурация и сопровождение программного обеспечения, обеспечивающего доступ рабочих станций к данным, приводит в среднем к четырем дням простоя рабочей станции в год.
Имеется еще один фактор, напрямую связанный с тем, что многие средства разработки используют одни и те же стандартные библиотеки доступа к данным (в случае Windows это BDE и ODBC). На сегодняшний день как на российском, так и на мировом рынке имеется немалое количество различных программных продуктов, содержащих какие-либо данные (в особенности энциклопедий и справочников), при установке которых устанавливаются и эти библиотеки (подобные действия разрешены при определенных условиях производителями этих библиотек). В этом случае нет никакой гарантии, что версия любой из подобных библиотек, входящая в комплект поставки такого продукта, окажется новее, чем уже используемая в корпоративной информационной системе, и что программа установки не внесет изменений в настройки, сопровождающие эту библиотеку, таким образом, что работоспособность уже установленной информационной системы окажется нарушенной. Это, конечно, противоречит правилам создания дистрибутивов, но такие случаи время от времени случаются даже с неплохими коммерческими продуктами.
Известен случай выпуска большим тиражом в одной из европейских стран коммерческого программного продукта (а именно телефонного справочника), установка которого на рабочих станциях пользователей приводила к выходу из строя всех пользовательских приложений, использующих доступ к данным и созданных с помощью более новой версии того же средства разработки, что использовался при создании данного справочника. Причиной подобных неприятностей явилась замена библиотек доступа к данным их более старыми версиями и переписывание файлов конфигурации при инсталляции этого продукта. (Как вы думаете, кому в первую очередь пользователи предъявляли претензии по поводу выхода из строя корпоративной информационной системы? Уверяю вас, отнюдь не разработчикам телефонного справочника, лежавшего в тот момент во всех магазинах этой страны… Собственно, сама эта история была рассказана автору его коллегой-программистом из той самой европейской страны как раз в разгар потока претензий и рекламаций, получаемых им от разъяренных клиентов его компании, занимавшейся разработкой на заказ корпоративных информационных систем, вдруг переставших нормально функционировать после установки купленного пользователями телефонного справочника).
Итак, используя стандартные архитектуры создания многопользовательских информационных систем, можно столкнуться как минимум с двумя серьезными проблемами, требующими материальных затрат: все более повышающимися требованиями к аппаратному обеспечению рабочих станций и обеспечением поддержки настроек доступа к данным. Отметим, что список возможных проблем этим не исчерпывается. Мы не рассматривали проблемы, связанные с перегрузкой сети при росте объема данных (частично они могут быть решены при замене сетевых СУБД на серверные, но далеко не всегда такой переход полностью решает эти проблемы), проблемы, связанные с эксплуатацией всеми пользователями каких-либо общих ресурсов (например, высококачественного многопроцессорного сервера, способного быстро обрабатывать данные по сравнению с пользовательскими рабочими станциями), а также проблемы, возникающие при территориальной разбросанности предприятия или низком качестве линий связи.
Каким образом можно решить весь этот набор проблем? Способов их решения достаточно. Нередко применяются так называемые экстенсивные меры (наращивание аппаратной части рабочих станций, увеличение пропускной способности сети, прокладка новых линий связи, перенос прошлогодних данных в архивы с целью уменьшения объема базы данных), которые обычно требуют немалых материальных затрат, особенно при большом количестве пользователей и высокой скорости роста объема базы данных.
Есть, однако, и иные, интенсивные способы решения подобных проблем. Эти способы решения могут иметь различную реализацию, но в целом они используют одну общую идею. Эта идея заключается в создании новых сервисов, общих для пользователей информационной системы.
Такие сервисы, как правило, являются сервисами промежуточного слоя (middleware services), поскольку занимают промежуточный уровень между данными и сервисами, их обслуживающими, с одной стороны, и пользовательскими приложениями, ориентированными на конкретную предметную область, с другой стороны. Эти сервисы обычно обладают минимальным пользовательским интерфейсом или не имеют его вовсе. Нередко они могут быть реализованы для нескольких различных платформ, так как являются сервисами более высокого уровня, чем сервисы, специфичные для данной операционной системы или СУБД. Такие сервисы могут быть реализованы внутри приложений или библиотек (такие приложения или библиотеки обычно называются серверами приложений - Application Server), а также в виде служб операционных систем. Пользовательские приложения, использующие сервисы промежуточного слоя, обычно называются клиентами.
Технологии, используемые для реализации таких сервисов, могут быть различными. В частности, их реализация может использовать технологию и стандарты DCE (Distributed Computing Environment), разработанные OSF (Open Software Foundation), как это сделано в Inprise Entera. Можно реализовать такие сервисы с использованием спецификации CORBA (Common Object Request Broker Architecture), разработанной консорциумом OMG (Object Management Group). В обоих случаях набор возможных клиентских и серверных платформ весьма широк и отнюдь не ограничивается различными версиями Windows. Если же речь идет об относительно недорогих решениях на основе Windows, вполне допустимо использовать DCOM (Distributed Component Object Model) либо различные расширения COM (например, технологию Inprise MIDAS) и реализовывать сервисы middleware внутри серверов автоматизации или компонентов Microsoft Transaction Server (о нем пойдет речь в следующей статье данного цикла).
Какими бывают сервисы промежуточного слоя и серверы приложений
Одним из наиболее модных на сегодняшний день типов серверов приложений являются серверы доступа к данным (Data Access Server), реализуемые, как правило, в виде приложений (реже - в виде библиотек). Они содержат функциональность, связанную с доступом к данным (а нередко и какую-либо иную функциональность, например, статистическую обработку этих данных или генерацию отчетов). Как правило, такие приложения-серверы сами являются клиентами серверных СУБД. В любом случае такие серверы используют перечисленные выше библиотеки доступа к данным. При грамотной организации разделения функций между пользовательским приложением и сервером доступа к данным конфигурация программного обеспечения рабочей станции сводится к информированию пользовательского приложения о том, как называется (или идентифицируется иным способом) нужный ему сервис и на каком компьютере сети должен находиться либо непосредственно он сам, либо некий сервис-посредник, чья задача заключается в поиске нужного сервиса для данного клиента (рис. 2).
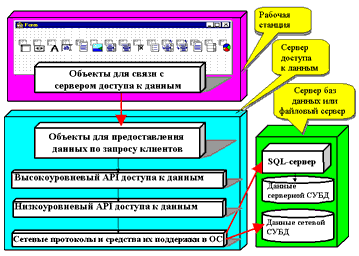
Рис. 2. Информационная система с сервером доступа к данным
К этой же категории сервисов можно отнести так называемые мониторы транзакций. Мониторы транзакций, как правило, применяются в информационных системах, использующих распределенное хранение данных (то есть хранение данных в нескольких базах данных, возможно, в разных СУБД и на физически различных компьютерах) и содержащих приложения, использующие одновременный доступ к нескольким базам данных, включающий так называемые распределенные транзакции (то есть модификацию данных в нескольких различных БД, рассматриваемую как единое целое и либо выполняющуюся целиком, либо целиком отменяемую). Если обычные транзакции внутри одной базы данных с успехом поддерживаются серверными СУБД, лишь бы были реализованы в виде объектов базы данных (индексов, триггеров, хранимых процедур, серверных ограничений и др.) соответствующие правила их выполнения, то распределенные транзакции требуют отдельной поддержки за пределами СУБД. Именно эта поддержка и реализуется в мониторах транзакций (рис.3).

Рис. 3. Информационная система с монитором транзакций
Отметим, однако, что в виде отдельного сервиса может быть реализован не только доступ к данным, но и любая другая функциональность пользовательского приложения, например, многомерный анализ и статистическая обработка данных, генерация и печать отчетов, проведение расчетов, обеспечение шифрования данных и многое другое. В этом случае говорят о серверах функциональности (functionality server). Отметим, что сервер функциональности - более общее понятие, чем сервер доступа к данным; последний есть лишь частный случай сервера функциональности. Один сервер функциональности может в общем случае предоставлять несколько сервисов.
Как правило, на сервер функциональности возлагаются задачи, требующие нестандартных ресурсов, например, избыточного по сравнению с обычной рабочей станцией объема оперативной памяти, нестандартного оборудования, нестандартной операционной системы или иного программного обеспечения (в том числе, например, библиотек для доступа к данным), и др.
Специализированные сервисы
Особым видом сервисов промежуточного слоя являются так называемые специализированные сервисы. Эти сервисы предназначены для обеспечения нормального функционирования системы, содержащей набор серверов функциональности.
К сожалению, терминология (как русская, так и английская), употребляемая при описании таких сервисов, весьма разнообразна и существенно зависит от того, какой спецификации подчиняется их работа и какая реализация данной спецификации используется в конкретном программном продукте, частью которого является данный сервис. Нередко один и тот же термин (например, брокер, агент, или демон) обозначает совершенно различные по своему назначению сервисы в различных спецификациях и различных продуктах, а иногда обозначает не сервис, а просто концепцию, реализованную в сервисах с другими названиями. У некоторых англоязычных терминов имеется несколько разных вариантов русских переводов, некоторые не имеют их вовсе. Поэтому к терминологии, употребляемой в данной статье, следует относиться с осторожностью. В последующих же статьях данного цикла, посвященных конкретным спецификациям или конкретным их реализациям, мы будем придерживаться терминов, в этих спецификациях и реализациях принятых.
Наиболее распространенными из специализированных сервисов являются сервисы, позволяющие на определенных условиях определенным пользователям получить доступ к тому или иному серверу функциональности, содержащемуся на компьютере, где функционирует данный специализированный сервис. Иногда такой сервис может быть выполнен в виде приложения, иногда - в виде сервиса операционной системы. В случае реализации спецификации в продукте Inprise Visibroker он называется Object Activation Daemon, в случае использования доступа к COM-серверам с помощью Inprise OLEnterprise - Object Factory, в случае использования доступа к COM-серверам с помощью протокола TCP/IP - Borland Socket Server, в случае Inprise AppCenter - AppCenter Agent. В случае использования соответствующего сервиса Microsoft DCOM по отношению к нему и другим подобным сервисам иногда употребляется термин Service Control Manager (см., например, Brockschmidt K. What OLE is really about, www.microsoft.com/oledev/olecom/aboutole.html).
Действия этого сервиса действительно напоминают действия агента вражеской разведки - доступ к серверам функциональности данного компьютера возможен только в том случае, если такой сервис запущен. Это диктуется обычными соображениями безопасности - было бы неразумным предоставлять возможность кому угодно использовать предоставляемые данным компьютером сервисы в любое время.
Помимо предоставления доступа к серверу функциональности на приложение, содержащее такой сервис, могут возлагаться и другие обязанности (например, запустить сервер функциональности, как это делает Object Activation Daemon, или передавать и принимать данные, как это делает Borland Socket Server).
Еще один распространенный (но в целом не являющийся обязательным) тип специализированных сервисов - это сервисы, занимающиеся поиском серверов функциональности для обратившихся к ним клиентов и выступающие в качестве посредника между клиентом, нуждающимся в том или ином сервисе, и поставщиком сервиса (в данном случае сервером функциональности), сводя их между собой. Иногда такие сервисы называются общим термином Directory Service. Обычно такие сервисы используются в системах, содержащих несколько одинаковых серверов функциональности, и подключают обратившихся к ним клиентов к этим серверам в соответствии с установленными для этой системы правилами (например, случайным образом, чем достигается баланс загрузки серверов клиентскими приложениями; или, например, к какому-либо конкретному серверу, а в случае сбоя - к другому, считающемуся резервным; правила выбора сервера для обратившегося клиента могут быть самыми разнообразными).
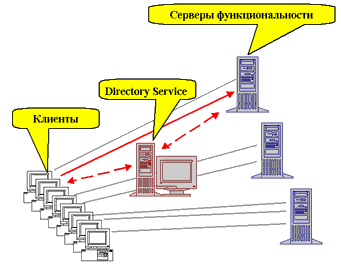
Рис. 4. Система, использующая Directory Service
В случае использования Microsoft DCOM наличие такого сервиса не предполагается, равно как и в случае использования Borland Socket Server. В случае расширения COM с помощью Inprise OLEnterprise этот сервис (в данной реализации он называется Business Object Broker) может как использоваться, так и не использоваться. В случае Inprise Entera 3.2 этот сервис используется обязательно (в данной реализации он называется Entera Broker). В случае Inprise AppCenter использование подобного сервиса также обязательно (в этом случае он называется AppCenter Broker, при этом Entera Broker для него может являться сервером функциональности, который следует искать). А вот в спецификации CORBA и ее реализациях этот сервис называется Object Agent.
Отметим, однако, что в некоторых источниках термин Broker нередко означает просто некую транспортную службу, обеспечивающую передачу серверу запросов клиента и обмен данными между ними. При этом такая служба может быть реализована внутри какого-либо служебного приложения (как, например, это сделано в Borland Socket Server), а может фактически содержаться внутри самого сервера функциональности и использующего его клиента (так, например, устроены клиенты и серверы Entera; при этом сам термин broker в Entera означает Directory Service). В случае же CORBA этот термин обозначает скорее концепцию, нежели конкретный подлежащий реализации сервис.
Регистрационные базы данных и идентификация серверов и сервисов
Каким образом можно инициировать запуск сервера по запросу клиента? Если реализация сервера одна, и клиенту известно, как ее идентифицировать и на каком компьютере сети ее искать, он обращается к сервису, ответственному за предоставление доступа к данной реализации (Service Control Manager). В случае получения разрешения этот сервис обращается к другому сервису, ответственному за запуск сервера функциональности (как было сказано выше, оба сервиса могут и часто бывают реализованы в одном приложении). Этим другим сервисом либо запускается соответствующее приложение (если сервер еще не запущен, или если каждому клиенту нужен свой экземпляр сервера), либо внутри уже запущенного сервера создаются объекты, взаимодействующие с данным клиентом.
Если реализаций сервиса несколько, удаленный запуск одной из них по запросу клиента может быть осуществлен в том случае, если сведения о местоположении этих реализаций доступны либо самому клиенту, либо сервису, который ищет реализацию по его запросу. В простейшем случае список возможных реализаций просто содержится в клиентском приложении. Например, компонент SimpleObjectBroker в Delphi 4 как раз содержит такой список; клиентское приложение, содержащее такой компонент, будет при каждом запуске случайным образом подключаться к одной из реализаций, указанной в списке. Однако в общем случае, особенно когда для поиска реализации используются специализированные сервисы, такой список хранится отдельно от клиентского приложения.
Естественно, для этого в системе должна существовать некая специализированная база данных, в которой содержатся сведения о сервисах и серверах, содержащих их реализацию. Общей спецификации, которой могло бы подчиняться создание такой базы данных, не существует, так как в общем случае такая база данных может содержаться на любой платформе. В случае COM и его расширений (таких как OLEnterprise) роль такой базы данных с успехом выполняет реестр Windows. В случае CORBA эти сведения хранятся в двух репозитариях (в одном регистрируются интерфейсы сервера, в другом - их реализации, то есть конкретные приложения-серверы). Inprise AppCenter использует свою собственную базу данных (ее реализация существует для нескольких платформ), при этом она управляется специальным приложением, регистрирующим обращения к ней других сервисов.
Отметим, что удаленный запуск сервера по запросу брокера или клиента осуществляется в том случае, если выполняются условия, при которых он может быть запущен. Как было сказано ранее, на компьютере должен быть запущен сервис, предоставляющий разрешение на удаленный запуск данного сервера, и выполняются условия, при которых это разрешение может быть получено (например, пользователь клиентского приложения имеет право обращаться к этому серверу).
Всегда ли необходима регистрация серверов и сервисов? Это зависит от конкретной реализации способа удаленного доступа. COM-сервер автоматически регистрирует себя в реестре Windows после первого запуска, но этот первый запуск должен быть осуществлен не удаленно, а локально. При этом запись о COM-сервере обязана содержаться в реестре компьютера, содержащего сервер. При использовании DCOM и OLEnterprise удаленный сервер функциональности должен быть зарегистрирован также и в реестре клиентской рабочей станции, при этом использование DCOM предполагает для регистрации сервера на рабочей станции просто запустить его там. OLEnterprise, в отличие от Microsoft DCOM, предоставляет средства для импорта записи о сервере функциональности из реестра компьютера, содержащего сервер, в реестры рабочих станций. При использовании же Borland Socket Server сведения о сервере обязаны содержаться в клиентском приложении, а регистрация сервера на рабочей станции не требуется.
CORBA-сервер может не быть зарегистрирован в репозитариях, но при этом он не будет запускаться автоматически ни по запросу клиентов, ни по запросу служебных сервисов. Для регистрации интерфейсов и реализаций CORBA-серверов существуют специальные утилиты.
Серверы Entera 3.2 (равно как и другие приложения) можно зарегистрировать в базе данных Inprise AppCenter, а можно не регистрировать нигде. В этом случае сервер Entera 3.2 может быть найден сервисами и клиентами только в том случае, если он уже запущен.
В базе данных Inprise AppCenter можно регистрировать самые разнообразные сервисы, серверы и приложения, а также создавать так называемые конфигурации приложений, описывая правила, которым подчиняется их запуск и остановка. Эти правила могут быть весьма сложными, так как ApCenter, по существу, представляет собой средство управления серверами и сервисами в распределенных системах.
Естественно, если сервер функциональности нигде не зарегистрирован, не запущен в данный момент, и сведения о его возможных реализациях не содержатся в клиентском приложении, он не будет найден ни служебными сервисами, ни клиентами.
Как идентифицируются серверы и содержащиеся в них сервисы? Общих правил на все случаи жизни на этот счет не существует. Однако сейчас довольно часто принято присваивать серверам и сервисам уникальные идентификаторы UUID (Universal Unique Identifier), представляющие собой 128-разрядные значения, сгенерированные с помощью алгоритма, определенного OSF (Open System Foundation), на основе IP-адреса компьютера и иных его характеристик, и гарантирующего с высокой вероятностью уникальность сгенерированного значения. Реализация этого алгоритма содержится, например, в функции Windows API CoCreateGUID. В случае COM эти идентификаторы называются GUID (Global Unique Identifier), IID (Interface Identifier), CLSID (Class Identifier). Именно по этим идентификаторам обычно клиенты и другие сервисы в большинстве случаев ищут реализацию нужного сервера (или предоставляемого им сервиса). Тем не менее в некоторых реализациях можно осуществлять поиск и по другим признакам (имя приложения, имя сервиса и др.). Бывают случаи, когда UUID генерируется с целью соответствия стандартам, но в действительности не используется (например, при использовании серверов Entera 3.2 и доступа к ним непосредственно с помощью протокола TCP/IP).
Как устроено взаимодействие клиентов и серверов
Не стоит и говорить о том, что создание сервисов и серверов middleware имеет смысл главным образом в том случае, когда клиенты и сервер функционируют на разных компьютерах. В этом случае возникает естественный вопрос: а каким же образом клиент обращается к объектам, содержащимся в оперативной памяти другого компьютера (и в общем случае созданным в другой операционной системе)?
В настоящее время существует немало способов реализации подобного взаимодействия. Отметим, однако, что все эти способы базируются на одной и той же придуманной много лет назад идее осуществления вызовов удаленных процедур путем передачи данных между объектами внутри клиента и внутри сервера (рис.5).
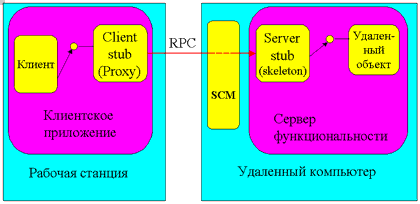
Рис. 5. Осуществление вызовов удаленных процедур
При обращении клиента к удаленному серверу функциональности внутри адресного пространства сервера создается так называемый серверный stub-объект (в терминологии CORBA он называется skeleton, в терминологии COM - stub; некоторые авторы переводят этот термин как "заглушка"), являющийся представителем данного клиента в адресном пространстве сервера (при многопользовательском доступе к одному и тому же экземпляру сервера этих объектов создается несколько).
Внутри адресного пространства клиента создается клиентский stub-объект (в терминологии CORBA он называется stub, в терминологии COM - proxy; иногда этот термин переводят как "заместитель"). Он может обладать таким же списком методов, как соответствующий ему серверный stub-объект, но никогда не содержит их истинной реализации (в лучшем случае вместо истинной реализации могут присутствовать функции API из библиотеки, реализующей вызовы удаленных процедур и передачу данных с помощью того или иного сетевого протокола, как, например, в случае stub-кода, сгенерированного утилитами из комплекта поставки Inprise Entera) Эти два stub-объекта общаются между собой, обмениваясь данными примерно так же, как взаимодействуют между собой сетевые приложения и сервисы. Из передаваемых данных формируются так называемые пакеты данных, которые с помощью сетевых протоколов передаются другому stub-объекту (этот процесс иногда называется маршалингом или маршрутизацией), где и расшифровываются.
При отсоединении клиента от сервера соответствующая пара stub-объектов уничтожается. При этом в том случае, когда первый из подключившихся к серверу клиентов инициировал сам или с помощью служебного сервера запуск сервера, при отключении всех клиентов сервер, как правило, должен прекратить свою работу. Если же сервер был запущен пользователем вручную, как правило, отсутствие подключенных клиентов обычно не является основанием для прекращения его работы.
Многие инструменты для создания серверов функциональности содержат в комплекте поставки утилиты для автоматической генерации stub-кода. Код генерируется на основании описаний интерфейса сервера. Во многих случаях эти описания создаются на языке IDL (Interface Definition Language).
Отметим, что существует несколько диалектов IDL (для COM, для CORBA и др.). Тем не менее различия между ними невелики. Delphi 4 поддерживает как COM IDL, так и CORBA IDL.
Сервер приложений Inprise Entera содержит такой кодогенератор для большого количества языков программирования; существует компилятор MIDL для генерации stub-кода и proxy-кода на C++ на основе COM IDL (он активно используется при создании серверов и клиентов с помощью Microsoft Visual C++). В случае CORBA также имеются кодогенераторы для С++ и Java. При создании серверов функциональности, реализованных в виде серверов автоматизации, c помощью Delphi и C++Builder, stub-код генерируется автоматически при создании соответствующих классов, и создавать описания с помощью IDL необходимости нет. Однако в этом случае всегда можно сгенерировать описание на IDL (как для COM, так и для CORBA) на основании созданной библиотеки типов сервера.
Зачем нужен IDL? Фактически это стандарт, позволяющий описывать вызываемые методы сервера и их параметры, не вдаваясь в детали и правила реализации серверов и клиентов на том или ином языке программирования. Используя IDL, можно описать интерфейсы сервера, а затем создать его реализацию на любом языке программирования с помощью широкого спектра средств разработки для широкого спектра платформ, равно как и реализацию клиента. В определенном смысле IDL - это стандарт для описания взаимодействия между компонентами распределенной системы, не зависящий от деталей реализации, языков программирования и платформ.
Что дальше?
Итак, мы рассмотрели общие принципы создания и использования таких сервисов, а также взаимодействия с ними клиентов. Однако при разработке реальных распределенных систем следует принять решение о выборе конкретной технологии и реализации с учетом особенностей будущей распределенной системы, требований, к ней предъявляемых, а также возможных материальных затрат. Поэтому следующие статьи данного цикла будут посвящены конкретным стандартам и программным продуктам, их реализующим.
О технологии COM и организации распределенных вычислений с использованием серверов автоматизации уже было рассказано в декабрьском номере журнала на примере C++Builder. Ближайшая из статей данного цикла будет снова посвящена использованию COM (точнее, COM+). В ней будет рассмотрено использование Microsoft Transaction Server в качестве средства управления сервисами в распределенных системах.
Другие статьи данного цикла будут посвящены созданию серверов функциональности с помощью Inprise Entera, созданию CORBA-серверов и клиентов, управлению сервисами и серверами с помощью Inprise AppCenter, а также, возможно, другим технологиям Inprise, предназначенным для организации распределенных вычислений.
Дополнительную информацию Вы можете получить в компании Interface Ltd.
Обсудить на форуме Inprise
Отправить
ссылку на страницу по e-mail
Interface Ltd.Отправить E-Mail http://www.interface.ru |
|
| Ваши замечания и
предложения отправляйте автору По техническим вопросам обращайтесь к вебмастеру Документ опубликован: 26.12.00 |